spurious scholar
Step 1: Gather a bunch of data. There are 25,156 variables in my database. The data ranges from the mundane (air pollution in Chicago) to the weird (Hotdogs consumed by Nathan's Hot Dog Eating Competition Champion) to the super-niche (How clickbait-y Numberphile YouTube video titles are, as rated by an AI).
Step 2: Dredge that data to find random correlations between variables. "Dredging data" means taking one variable and correlating it against every other variable just to see what sticks. It's a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
Fun fact: the chart used on the wikipedia page to demonstrate data dredging is also from me. I've been being naughty with data since 2014.
Step 3: Calculate the correlation coefficient, confidence interval, and p-value to see if the connection is statistically significant. "Statistically significant" is a misleading term. It sounds like it means "statistically significant" because, you know, those are the same two words. Unfortunately statistical significance is a technical term that means mumble mumble at least as extreme mumble mumble null hypothesis mumble mumble probability mumble mumble p-values.
You know what? Forget the technical definition. "Statistically significant" just means "someone did some fancy math."
I really did the fancy math below and you can check it by clicking on the "view detailed data" link under each paper. And these really do qualify as "statistically significant" in the technical sense. It's just that "statistically significant" does not mean the results are "significant."
Step 4: If it is, have a large language model draft a research paper.
Step 5: Remind everyone that these papers are AI-generated and are not real. Seriously, just pick one and read the lit review section. The silliness of the papers is an artifact of me (1) having fun and (2) acknowledging that realistic-looking AI-generated noise is a real concern for academic research (peer reviews in particular).
The papers could sound more realistic than they do, but I intentionally prompted the model to write papers that look real but sound silly.
Also: every page says "This paper is AI-generated" at the bottom and the first letters of the names of the authors always spell out C-H-A-T-G-P-T.
Step 6: ...publish:
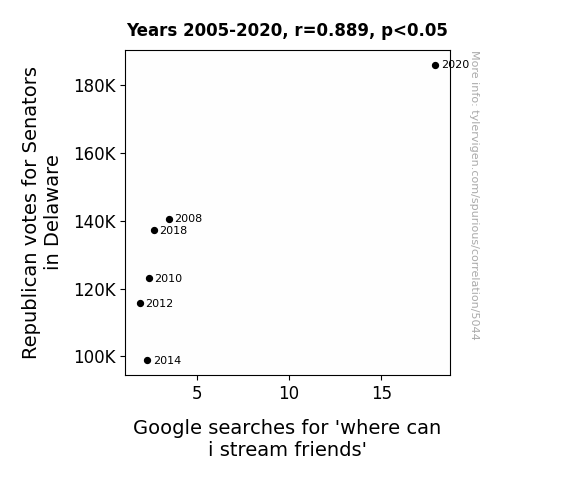

The Journal of Digital Sociology and Pop Culture Studies
r=0.889 · 95% conf. int. [0.277,0.988] · r2=0.790 · p < 0.05
Generated Jan 2024 · View data details
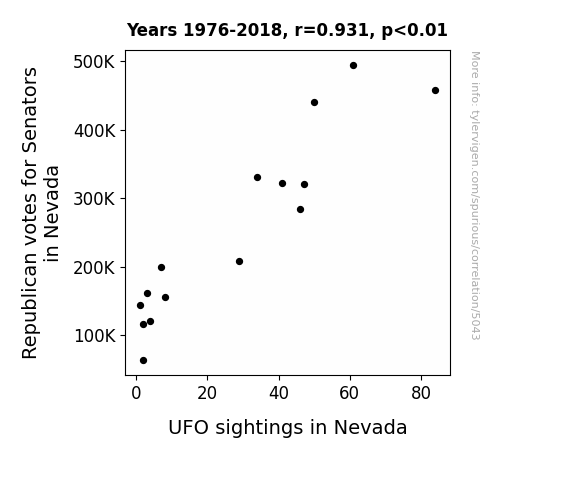

The Journal of Extraterrestrial Political Science
r=0.931 · 95% conf. int. [0.801,0.977] · r2=0.867 · p < 0.01
Generated Jan 2024 · View data details
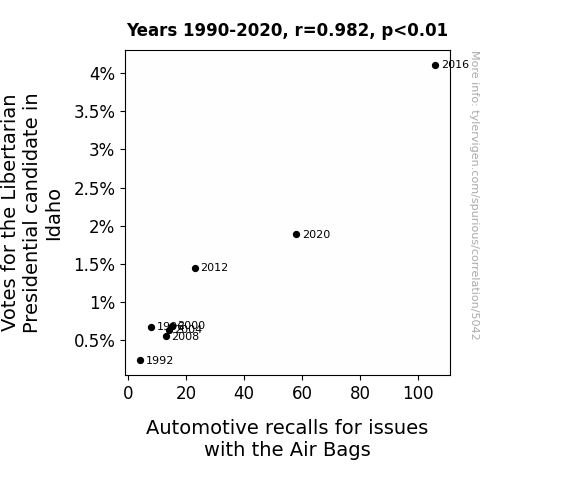

The Journal of Quirky Correlations
r=0.982 · 95% conf. int. [0.898,0.997] · r2=0.964 · p < 0.01
Generated Jan 2024 · View data details
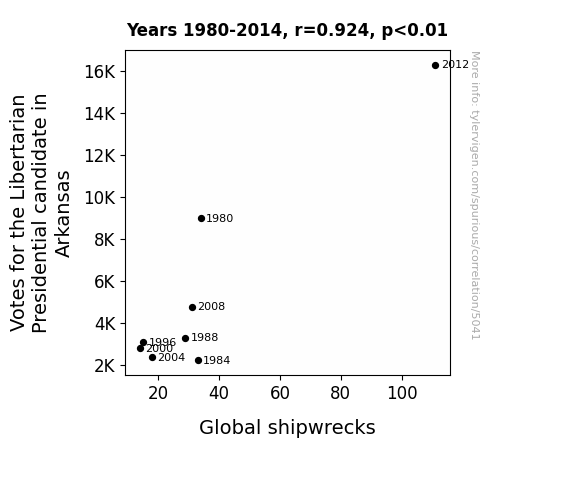

The Journal of Nautical Political Studies
r=0.924 · 95% conf. int. [0.628,0.986] · r2=0.854 · p < 0.01
Generated Jan 2024 · View data details
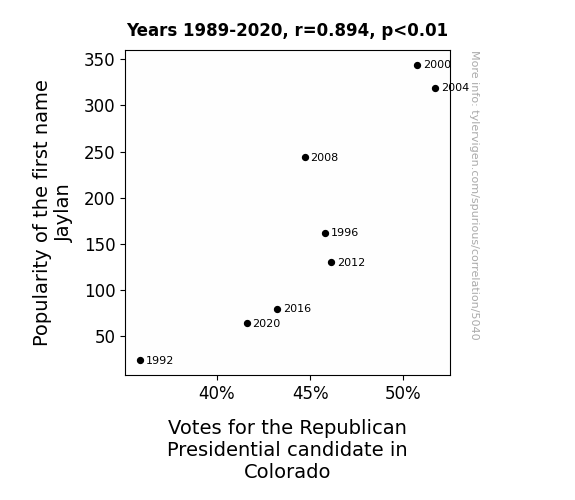

Journal of Political Dynamics and Public Opinion
r=0.894 · 95% conf. int. [0.512,0.981] · r2=0.800 · p < 0.01
Generated Jan 2024 · View data details


The Journal of Political Parody and Probability
r=0.855 · 95% conf. int. [0.141,0.984] · r2=0.731 · p < 0.05
Generated Jan 2024 · View data details
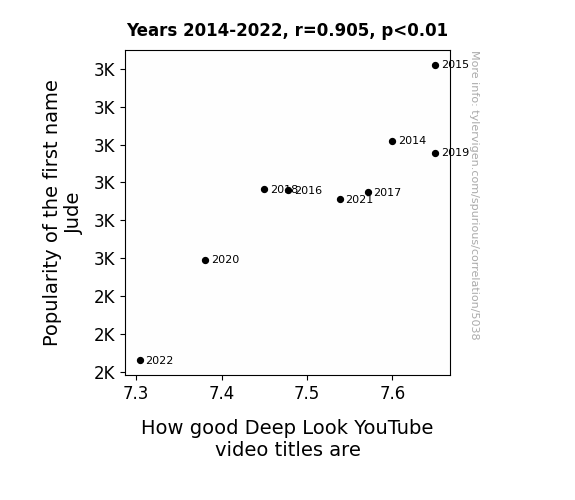

Journal of Eccentric Linguistics
r=0.905 · 95% conf. int. [0.602,0.980] · r2=0.818 · p < 0.01
Generated Jan 2024 · View data details
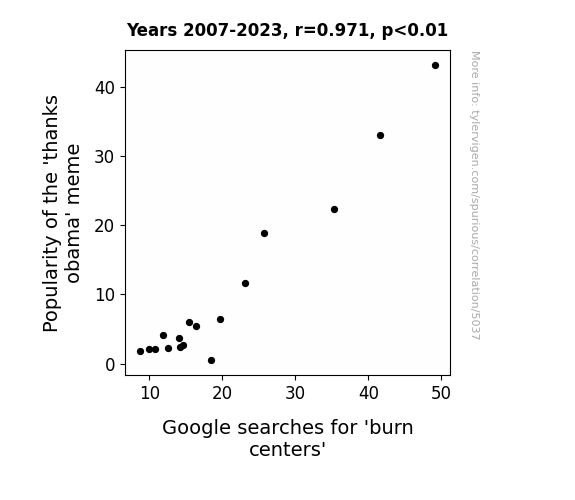

The Journal of Internet Memes and Public Health
r=0.971 · 95% conf. int. [0.919,0.990] · r2=0.942 · p < 0.01
Generated Jan 2024 · View data details


The Journal of Political Hospitality Studies
r=0.966 · 95% conf. int. [0.857,0.992] · r2=0.932 · p < 0.01
Generated Jan 2024 · View data details
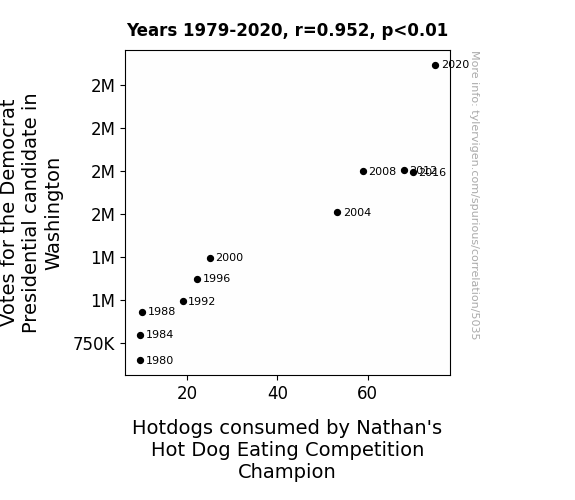

The Journal of Gastronomic Politics
r=0.952 · 95% conf. int. [0.821,0.988] · r2=0.906 · p < 0.01
Generated Jan 2024 · View data details
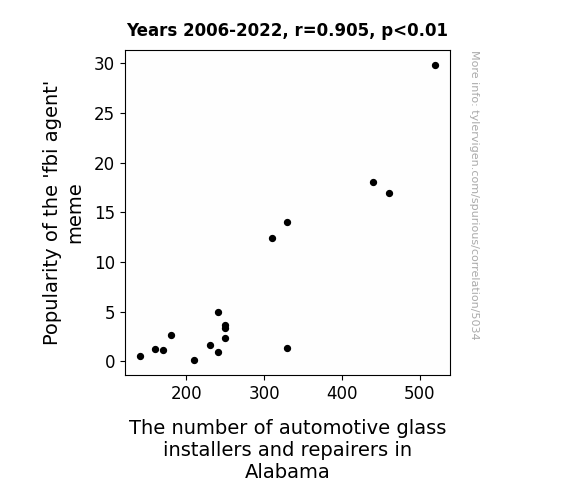

The Journal of Internet Memetics and Regional Occupational Trends
r=0.905 · 95% conf. int. [0.751,0.966] · r2=0.819 · p < 0.01
Generated Jan 2024 · View data details
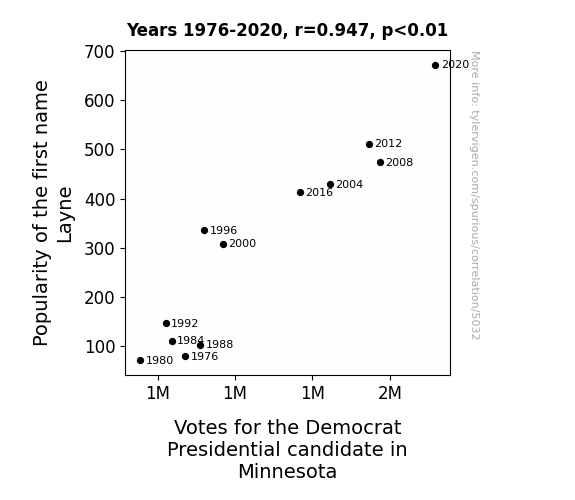

Journal of Political Popularity and Voting Behavior
r=0.947 · 95% conf. int. [0.818,0.985] · r2=0.897 · p < 0.01
Generated Jan 2024 · View data details


The Journal of Quirky Social Science Research
r=0.883 · 95% conf. int. [0.627,0.967] · r2=0.780 · p < 0.01
Generated Jan 2024 · View data details


The Journal of Ecological Entanglements
r=0.805 · 95% conf. int. [0.302,0.957] · r2=0.648 · p < 0.01
Generated Jan 2024 · View data details
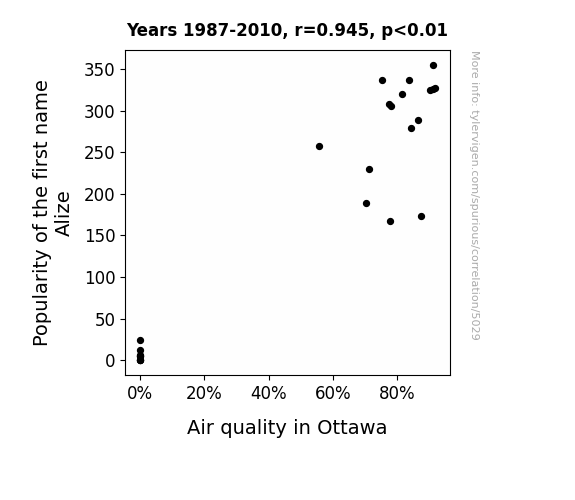

The Journal of Atmospheric Whimsy
r=0.945 · 95% conf. int. [0.876,0.976] · r2=0.893 · p < 0.01
Generated Jan 2024 · View data details


The Journal of Memetics and Energy Dynamics
r=0.980 · 95% conf. int. [0.942,0.993] · r2=0.960 · p < 0.01
Generated Jan 2024 · View data details
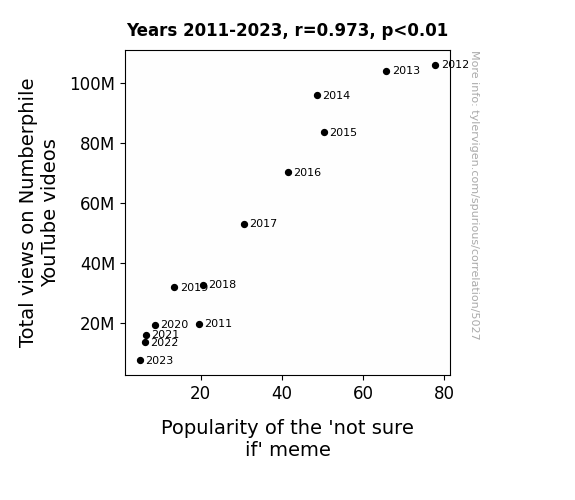

The Journal of Internet Culture and Quantitative Analysis
r=0.973 · 95% conf. int. [0.909,0.992] · r2=0.946 · p < 0.01
Generated Jan 2024 · View data details


The Journal of Environmental Economics and Policy Analysis
r=0.883 · 95% conf. int. [0.765,0.944] · r2=0.781 · p < 0.01
Generated Jan 2024 · View data details
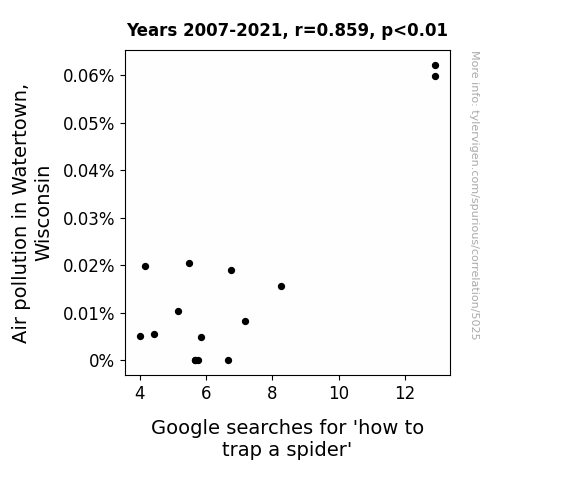

Journal of Anthropo-Arachnological Studies
r=0.859 · 95% conf. int. [0.618,0.952] · r2=0.737 · p < 0.01
Generated Jan 2024 · View data details
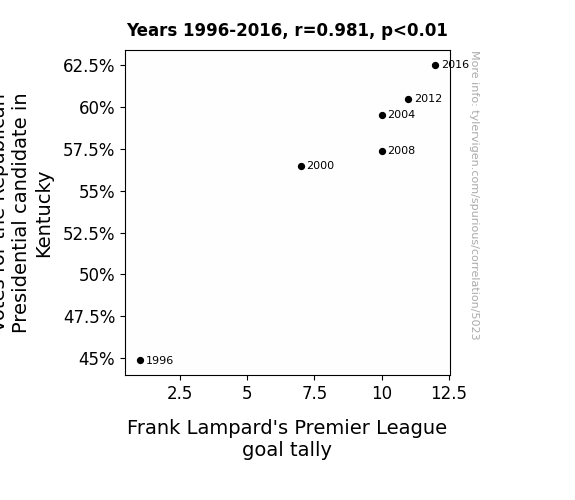

The Journal of Political Sports Science and Kentucky Studies
r=0.981 · 95% conf. int. [0.831,0.998] · r2=0.962 · p < 0.01
Generated Jan 2024 · View data details


The Journal of Political Internet Research
r=0.992 · 95% conf. int. [0.922,0.999] · r2=0.983 · p < 0.01
Generated Jan 2024 · View data details
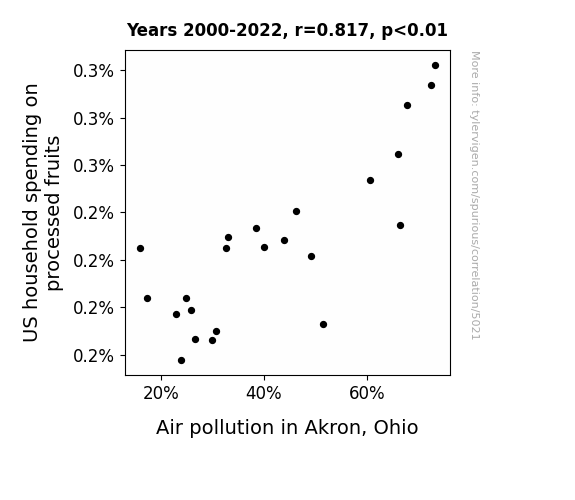

Journal of Environmental Health and Fruit Consumption
r=0.817 · 95% conf. int. [0.611,0.920] · r2=0.668 · p < 0.01
Generated Jan 2024 · View data details
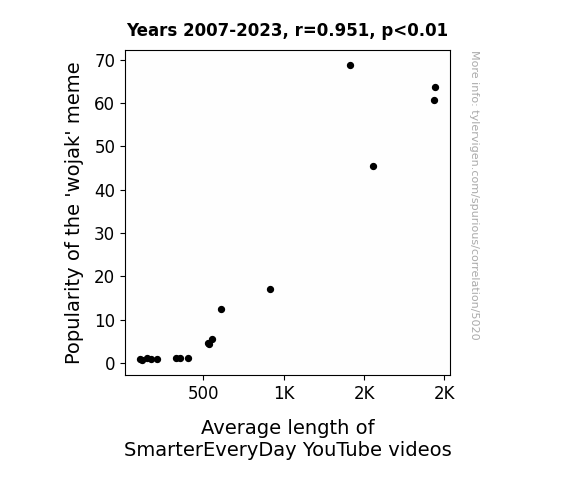

The Journal of Internet Culture and Media Studies
r=0.951 · 95% conf. int. [0.867,0.983] · r2=0.905 · p < 0.01
Generated Jan 2024 · View data details


The Journal of Internet Culture and Bereavement Studies
r=0.863 · 95% conf. int. [0.653,0.950] · r2=0.744 · p < 0.01
Generated Jan 2024 · View data details


The Journal of Comical Chemistry
r=0.867 · 95% conf. int. [0.652,0.953] · r2=0.752 · p < 0.01
Generated Jan 2024 · View data details
Currently viewing 25 of 4,731 spurious research papers
Page
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190
Why this works
- Data dredging: I have 25,156 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 632,824,336 correlation calculations! This is called “data dredging.”
Fun fact: the chart used on the wikipedia page to demonstrate data dredging is also from me. I've been being naughty with data since 2014.
Instead of starting with a hypothesis and testing it, I isntead tossed a bunch of data in a blender to see what correlations would shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random. - Lack of causal connection: There is probably no direct connection between these variables, despite what the AI says above.
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. You will often see trend-lines form. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A naive p-value calculation does not take this into account.
You will calculate a lower chance of "randomly" achieving the result than represents reality.
To be more specific: p-value tests are probability values, where you are calculating the probability of achieving a result at least as extreme as you found completely by chance. When calculating a p-value, you need to assert how many "degrees of freedom" your variable has. I count each year (minus one) as a "degree of freedom," but this is misleading for continuous variables.
This kind of thing can creep up on you pretty easily when using p-values, which is why it's best to take it as "one of many" inputs that help you assess the results of your analysis.
- Outliers: Some datasets here have outliers which drag up the correlation.
In concept, "outlier" just means "way different than the rest of your dataset." When calculating a correlation like this, they are particularly impactful because a single outlier can substantially increase your correlation.
Because this page is automatically generated, I don't know whether any of the charts displayed on it have outliers. I'm just a footnote. ¯\_(ツ)_/¯
I intentionally mishandeled outliers, which makes the correlation look extra strong.
Spurious Scholar was launched January 27, 2024. If you have feedback on it, I'd love to hear from you! Shoot me a note: feedback@tylervigen.com.


