
Download png, svg
AI explanation
As the popularity of the name Kelsey soared, more parents were inspired to name their children after the pioneering astronaut Kelsey Grammer. This led to a surge in interest in space exploration and a gravitational pull towards supporting NASA. It seems the cosmos just couldn't resist the star power of the Kelsey name, propelling funding for out-of-this-world research. It's a stellar example of how a celestial name can launch a stellar career, proving that when it comes to astronomical success, the sky's the limit!
Model: dalle-3
Prompt: "Generate a cyber art-style image of a bustling town square with a large sign reading "NASA" in bold letters. A group of excited people, some holding telescopes and others pointing up at the sky, are gathered around the sign, eagerly chatting about the latest space missions. Nearby, a banner displays the name "Kelsey" in colorful letters, and a line of people are waiting to sign petitions and show their support for space exploration. As they do, a symbol of a rocket on the banner appears to soar higher and higher in response to their enthusiasm." Improved prompt: Generate a vibrant cyber art-style scene in a bustling futuristic town square with a large NASA sign prominent in the center. People are gathered around, some gazing upward with telescopes and others engrossed in animated conversations about space missions. A colorful banner displaying "Kelsey" catches the eye nearby, drawing a line of eager supporters signing petitions for space exploration. The rocket symbol on the banner seems to dynamically ascend higher and higher, reflecting the enthusiasm of the crowd. The depiction should include only scenes, people, and objects, it should not include text or speech bubbles.
This image generation prompt was also generated by AI, using the following sequence:
Model: gpt-3.5-turbo-1106
System prompt: You select one of a few potential scene descriptors that seems to go along with the situation described. You respond only with the scene descriptions provided and say nothing else.
User prompt: Here is a situation: The increase in popularity of the first name Kelsey leads to a surge in interest in space exploration, resulting in more public support for NASA and ultimately a boost in budget appropriation to fuel the nation's enthusiasm for all things cosmic.. Given that situation, which of the following image descriptions seems most appropriate? Pick the one that seems to be related to one of the variables at hand and the tone of the explanation. Please respond with only one of the following potential descriptions: Cyberpunk Cyber folk Cyber folk Symbolism Data cyber art
ChatGPT: Data cyber art
Model: gpt-3.5-turbo-1106
System prompt: You describe simple visual scenes that depict the two variables stated and the explanation described. Do not reference graphs or charts; describe physical objects.
User prompt: Please describe a visual scene that depicts the following situation. Keep the description simple. The increase in popularity of the first name Kelsey leads to a surge in interest in space exploration, resulting in more public support for NASA and ultimately a boost in budget appropriation to fuel the nation's enthusiasm for all things cosmic.
ChatGPT: Imagine a bustling town square with a large sign that reads "NASA" in bold letters. A group of excited people, some holding telescopes and others pointing up at the sky, are gathered around the sign, eagerly chatting about the latest space missions. Nearby, a banner displays the name "Kelsey" in colorful letters, and a line of people are waiting to sign petitions and show their support for space exploration. As they do, a symbol of a rocket on the banner appears to soar higher and higher in response to their enthusiasm.
Model: gpt-3.5-turbo-1106
System prompt: You write and improve image generation prompts for DALLE-3. You maintain the same subjects, but enhance the visuals.
User prompt: Please respond with an image generation prompt that would be likely to create an interesting visual using DALLE-3, using the following style: [ Data cyber art ] and depicting this scene: Imagine a bustling town square with a large sign that reads "NASA" in bold letters. A group of excited people, some holding telescopes and others pointing up at the sky, are gathered around the sign, eagerly chatting about the latest space missions. Nearby, a banner displays the name "Kelsey" in colorful letters, and a line of people are waiting to sign petitions and show their support for space exploration. As they do, a symbol of a rocket on the banner appears to soar higher and higher in response to their enthusiasm. Keep the visual depiction simple. Do not include any words or speech bubbles.
ChatGPT: "Generate a cyber art-style image of a bustling town square with a large sign reading "NASA" in bold letters. A group of excited people, some holding telescopes and others pointing up at the sky, are gathered around the sign, eagerly chatting about the latest space missions. Nearby, a banner displays the name "Kelsey" in colorful letters, and a line of people are waiting to sign petitions and show their support for space exploration. As they do, a symbol of a rocket on the banner appears to soar higher and higher in response to their enthusiasm." Improved prompt: Generate a vibrant cyber art-style scene in a bustling futuristic town square with a large NASA sign prominent in the center. People are gathered around, some gazing upward with telescopes and others engrossed in animated conversations about space missions. A colorful banner displaying "Kelsey" catches the eye nearby, drawing a line of eager supporters signing petitions for space exploration. The rocket symbol on the banner seems to dynamically ascend higher and higher, reflecting the enthusiasm of the crowd.
*Variations in the User Prompts from chart to chart are just the result of random number generation in Python. I wrote a few arrays of various styles and methods to ask questions to change up the results. Every time this site writes an explanation or generates an image, the script picks from each at random.
I sequence the requests into multiple prompts because I find GPT 3.5 to perform much better with short, well-managed contexts. Thus, I track the context directly in Python and only ask ChatGPT targeted questions.
System prompt: You provide humorous responses in the form of plausible sounding explanations for correlations. You assume the correlation is causative for the purpose of the explanation even if it is ridiculous. You do not chat with the user, you only reply with the causal connection explanation and nothing else.
User prompt: Please make up a funny explanation for how increases in Popularity of the first name Kelsey positively influenced NASA's budget appropriation. Include one good pun.
AI academic paper
 |
Houston, We Have a Kelsey: Unveiling the Interstellar Relationship Between Kelsey's Popularity and NASA's Budget Appropriation The Journal of Cosmic Connections Jan 2024 Reminder: This paper is AI-generated. Not real! |
Model: gpt-3.5-turbo-1106
System prompt: You are a witty academic researcher. Your writing sounds like it belongs in a statistics journal.You write titles and abstracts of goofy academic research papers.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, and add unexpected twists in your writing.
Please draft the title and abstract of an academic research paper presenting the findings of the connection between Popularity of the first name Kelsey and NASA's budget appropriation. Make lots of jokes, goofy observations, and puns.
Make the title punny if you can come up with clever pun. If not, make it sound serious.
Your research team used data from US Social Security Administration and Planetary to assess this nagging question. You found a correlation coefficient of 0.8814370 and p < 0.01 for 1975 to 2022.
Please respond in this format (replace "Lorem ipsum dolor sit" with your title and abstract)
[[TITLE]]
Lorem ipsum dolor sit
[[ABSTRACT]]
Lorem ipsum dolor sit
ChatGPT:
[[TITLE]]
Houston, We Have a Kelsey: Unveiling the Interstellar Relationship Between Kelsey's Popularity and NASA's Budget Appropriation
[[ABSTRACT]]
This study explores the celestial correlation between the rise and fall of the popularity of the name "Kelsey" and its effect on NASA's budget appropriation. By utilizing data from the US Social Security Administration and Planetary, we conducted a computational analysis to unveil the striking relationship between the two seemingly unrelated phenomena. Our findings reveal a statistically significant correlation coefficient of 0.8814370 and p < 0.01 for the years 1975 to 2022, indicating a cosmic connection that has eluded previous research. We present an in-depth analysis of this unique relationship, offering lighthearted speculation and a cosmic twist to the world of budgetary allocation and nomenclature popularity.
Model: gpt-3.5-turbo-1106
System prompt: You are a witty academic researcher. Your writing sounds like it belongs in a statistics journal.You draft the introduction section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the introduction section of an academic research paper presenting the findings of the connection between Popularity of the first name Kelsey and NASA's budget appropriation. Make lots of jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Here is the title and abstract of the paper:
[[TITLE]]
Houston, We Have a Kelsey: Unveiling the Interstellar Relationship Between Kelsey's Popularity and NASA's Budget Appropriation
[[ABSTRACT]]
This study explores the celestial correlation between the rise and fall of the popularity of the name "Kelsey" and its effect on NASA's budget appropriation. By utilizing data from the US Social Security Administration and Planetary, we conducted a computational analysis to unveil the striking relationship between the two seemingly unrelated phenomena. Our findings reveal a statistically significant correlation coefficient of 0.8814370 and p < 0.01 for the years 1975 to 2022, indicating a cosmic connection that has eluded previous research. We present an in-depth analysis of this unique relationship, offering lighthearted speculation and a cosmic twist to the world of budgetary allocation and nomenclature popularity.
-------
Your response should start like this:
[[INTRODUCTION]]
ChatGPT:
[[INTRODUCTION]]
Astronomy and sociology may seem like distant galaxies in the research universe, but as we often find in science, unexpected connections can emerge. In this paper, we launch into the intriguing realm of interstellar correlations as we explore the cosmic dance between the popularity of the first name Kelsey and NASA's budget appropriation.
While armchair astronomers may raise an eyebrow at the thought of a celestial correlation with a name, our study takes a statistical journey through the data universe to shed light on this cosmic conundrum. As we embark on this cosmic cruise, we invite our readers to fasten their seatbelts and prepare for an expedition into the depths of statistical analysis, where the stars align in unexpected ways.
As we embark on this statistical odyssey, we cannot help but marvel at the cosmic humor that seems to permeate our research. Indeed, the journey to uncover the relationship between the name "Kelsey" and NASA's budget appropriation has led us down a path strewn with unexpected twists and turns, making this investigation a stellar blend of scientific inquiry and celestial amusement.
Here we stand at the intersection of two seemingly unrelated phenomena - the ebb and flow of a name's popularity and the budget allocation decisions of a space agency - ready to unravel the cosmic threads that bind them together. Through data exploration, statistical modeling, and a healthy dose of cosmic curiosity, we aim to elevate the conversation around budget appropriations to new celestial heights, all while weaving in our lighthearted cosmic speculations and statistical puns.
In the pages that follow, we invite readers to join us on this astronomical adventure, where statistical significance meets stargazing fascination. As we delve into this celestial mystery, prepare for a journey that transcends the ordinary bounds of research and ventures into the cosmic corners of statistical inference and interstellar intrigue. So, buckle up, dear readers, for the cosmic ride of a lifetime awaits us as we unveil the celestial symphony hidden within the data cosmos.
Model: gpt-3.5-turbo-1106
System prompt: You are a witty academic researcher. Your writing sounds like it belongs in a statistics journal.You draft a literature review section of an academic research paper, that starts out dry for the first few sentences but then becomes hilarious and goofy.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a literature review section of an academic research paper presenting the findings of the connection between Popularity of the first name Kelsey and NASA's budget appropriation. Make lots of jokes, goofy observations, and puns.
Speak in the present tense for this section (the authors find...), as is common in academic research paper literature reviews. Name the sources in a format similar to this: In "Book," the authors find lorem and ipsum.
Make up the lorem and ipsum part, but make it sound related to the topic at hand.
Start by naming serious-sounding studies by authors like Smith, Doe, and Jones - but then quickly devolve. Name some real non-fiction books that would be related to the topic. Then name some real fiction books that sound like they could be related. Perhaps you also got inspiration from some board games that are vaugely related.
Here is the title and abstract of the paper:
[[TITLE]]
Houston, We Have a Kelsey: Unveiling the Interstellar Relationship Between Kelsey's Popularity and NASA's Budget Appropriation
[[ABSTRACT]]
This study explores the celestial correlation between the rise and fall of the popularity of the name "Kelsey" and its effect on NASA's budget appropriation. By utilizing data from the US Social Security Administration and Planetary, we conducted a computational analysis to unveil the striking relationship between the two seemingly unrelated phenomena. Our findings reveal a statistically significant correlation coefficient of 0.8814370 and p < 0.01 for the years 1975 to 2022, indicating a cosmic connection that has eluded previous research. We present an in-depth analysis of this unique relationship, offering lighthearted speculation and a cosmic twist to the world of budgetary allocation and nomenclature popularity.
-------
And here is the introduction section that led to this literature review:
[[INTRODUCTION]]
Astronomy and sociology may seem like distant galaxies in the research universe, but as we often find in science, unexpected connections can emerge. In this paper, we launch into the intriguing realm of interstellar correlations as we explore the cosmic dance between the popularity of the first name Kelsey and NASA's budget appropriation.
While armchair astronomers may raise an eyebrow at the thought of a celestial correlation with a name, our study takes a statistical journey through the data universe to shed light on this cosmic conundrum. As we embark on this cosmic cruise, we invite our readers to fasten their seatbelts and prepare for an expedition into the depths of statistical analysis, where the stars align in unexpected ways.
As we embark on this statistical odyssey, we cannot help but marvel at the cosmic humor that seems to permeate our research. Indeed, the journey to uncover the relationship between the name "Kelsey" and NASA's budget appropriation has led us down a path strewn with unexpected twists and turns, making this investigation a stellar blend of scientific inquiry and celestial amusement.
Here we stand at the intersection of two seemingly unrelated phenomena - the ebb and flow of a name's popularity and the budget allocation decisions of a space agency - ready to unravel the cosmic threads that bind them together. Through data exploration, statistical modeling, and a healthy dose of cosmic curiosity, we aim to elevate the conversation around budget appropriations to new celestial heights, all while weaving in our lighthearted cosmic speculations and statistical puns.
In the pages that follow, we invite readers to join us on this astronomical adventure, where statistical significance meets stargazing fascination. As we delve into this celestial mystery, prepare for a journey that transcends the ordinary bounds of research and ventures into the cosmic corners of statistical inference and interstellar intrigue. So, buckle up, dear readers, for the cosmic ride of a lifetime awaits us as we unveil the celestial symphony hidden within the data cosmos.
-------
Your response should start like this:
[[LITERATURE REVIEW]]
ChatGPT:
[[LITERATURE REVIEW]]
In the exploration of the celestial mysteries surrounding the name "Kelsey" and NASA's budget appropriation, a multitude of scholarly works and statistical inquiries have paved the way for our cosmic investigation. Smith and Doe, in their groundbreaking research, investigated the cultural trends shaping given names and the societal implications of nomenclature popularity, laying the groundwork for our interstellar inquiry. Jones et al. delved into the intricacies of budget allocation processes, offering a comprehensive examination of the economic factors at play, although their work did not seem to reach for the stars in quite the same way we aspire to in this study.
Turning to the realm of non-fiction literature, "Naming Names: Exploring Monikers and their Meanings" by Linguist A. Lexicograph sheds light on the social and cultural dynamics influencing the popularity of names, providing an insightful backdrop for our cosmic contemplations. Additionally, in "Budgets, Bureaucrats, and Beyond: Unraveling the Economics of Government Spending," Economist E. Monetarist offers a thorough analysis of budgetary decision-making processes, although it must be noted that their work did not explicitly consider the cosmic implications of nomenclature on budget appropriations.
Departing from the serious and venturing into the fictional cosmos, "The Martian Chronicles" by Ray Bradbury offers a whimsical take on humanity's relationship with space, providing a literary backdrop for our cosmic endeavor. Similarly, "Space Oddity" by Cosmic Novelist Z. Stardust weaves a tale of cosmic exploration and interstellar intrigue, offering a playful nudge at the cosmic connection we seek to unravel.
Intriguingly, the board game "Cosmic Encounter" seems to encapsulate the essence of our investigation, with its intergalactic negotiations and cosmic conflicts reminiscent of the celestial dance we seek to elucidate. Additionally, "Terraforming Mars" captures the essence of human ambition in the cosmic frontier, providing a playful reflection of the themes resonant with our investigation.
While the literature has laid a foundation for our cosmic contemplations, the intersection of nomenclature popularity and budget appropriations remains an uncharted constellation in the research universe, awaiting our statistical telescopes to reveal its celestial secrets.
Model: gpt-3.5-turbo-1106
System prompt: You are a witty academic researcher. Your writing sounds like it belongs in a statistics journal.You draft the methodology section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the methodology section of an academic research paper presenting the findings of the connection between Popularity of the first name Kelsey and NASA's budget appropriation. Make lots of jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Planetary . You used data from 1975 to 2022
Make up the research methods you don't know. Make them a bit goofy and convoluted.
Here is the title, abstract, and introduction of the paper:
[[TITLE]]
Houston, We Have a Kelsey: Unveiling the Interstellar Relationship Between Kelsey's Popularity and NASA's Budget Appropriation
[[ABSTRACT]]
This study explores the celestial correlation between the rise and fall of the popularity of the name "Kelsey" and its effect on NASA's budget appropriation. By utilizing data from the US Social Security Administration and Planetary, we conducted a computational analysis to unveil the striking relationship between the two seemingly unrelated phenomena. Our findings reveal a statistically significant correlation coefficient of 0.8814370 and p < 0.01 for the years 1975 to 2022, indicating a cosmic connection that has eluded previous research. We present an in-depth analysis of this unique relationship, offering lighthearted speculation and a cosmic twist to the world of budgetary allocation and nomenclature popularity.
[[INTRODUCTION]]
Astronomy and sociology may seem like distant galaxies in the research universe, but as we often find in science, unexpected connections can emerge. In this paper, we launch into the intriguing realm of interstellar correlations as we explore the cosmic dance between the popularity of the first name Kelsey and NASA's budget appropriation.
While armchair astronomers may raise an eyebrow at the thought of a celestial correlation with a name, our study takes a statistical journey through the data universe to shed light on this cosmic conundrum. As we embark on this cosmic cruise, we invite our readers to fasten their seatbelts and prepare for an expedition into the depths of statistical analysis, where the stars align in unexpected ways.
As we embark on this statistical odyssey, we cannot help but marvel at the cosmic humor that seems to permeate our research. Indeed, the journey to uncover the relationship between the name "Kelsey" and NASA's budget appropriation has led us down a path strewn with unexpected twists and turns, making this investigation a stellar blend of scientific inquiry and celestial amusement.
Here we stand at the intersection of two seemingly unrelated phenomena - the ebb and flow of a name's popularity and the budget allocation decisions of a space agency - ready to unravel the cosmic threads that bind them together. Through data exploration, statistical modeling, and a healthy dose of cosmic curiosity, we aim to elevate the conversation around budget appropriations to new celestial heights, all while weaving in our lighthearted cosmic speculations and statistical puns.
In the pages that follow, we invite readers to join us on this astronomical adventure, where statistical significance meets stargazing fascination. As we delve into this celestial mystery, prepare for a journey that transcends the ordinary bounds of research and ventures into the cosmic corners of statistical inference and interstellar intrigue. So, buckle up, dear readers, for the cosmic ride of a lifetime awaits us as we unveil the celestial symphony hidden within the data cosmos.
-------
Your response should start like this:
[[METHODOLOGY]]
ChatGPT:
[[METHODOLOGY]]
To unravel the celestial connection between the popularity of the first name Kelsey and NASA's budget appropriation, our research team embarked on a cosmic quest through the vast expanse of data from the US Social Security Administration and the enigmatic reaches of Planetary. Our first leap into the cosmic unknown involved wrangling data spanning from 1975 to 2022, a time frame that allowed us to capture the astral ebbs and flows of Kelseys and NASA's budgetary escapades.
With data in hand, we then embarked on a statistical odyssey, employing a combination of astronomical regression analysis and sociological regression modeling. Picture it as a fusion of a star-studded galactic dance and an earth-bound statistical soirée. This celestial blend of techniques enabled us to probe the cosmic currents of the first name Kelsey's popularity and NASA's budget appropriation, guiding us through the twinkling mazes of astronomical data and the earthy terrain of socioeconomic influences.
We then took a quantum leap into the stratosphere of statistical analysis, crafting a cosmic correlation coefficient and p-values that would make even the most seasoned stargazer do a double-take. Our calculations unveiled a statistically significant correlation coefficient of 0.8814370 and p < 0.01, depicting a cosmic alignment of Kelsey's popularity and NASA's budget appropriation that defied the odds and ventured into the statistically stellar realm.
To bring a bit of levity to our cosmic exploration, we spiced up our data analysis with a sprinkling of cosmic humor and statistical puns. It's not every day that one gets to unravel the statistical mysteries of the universe while weaving in a celestial symphony of wordplay and whimsy.
And so, armed with data, statistical frameworks, and a healthy dose of cosmic curiosity, we ventured into the celestial unknown to unravel the cosmic threads that bind the name "Kelsey" and NASA's budget appropriation in a statistical embrace that transcends the ordinary bounds of research and ventures into the celestial corners of statistical inference and interstellar intrigue. It was a journey that left us starry-eyed and ready to share our cosmic revelations with the world.
Model: gpt-3.5-turbo-1106
System prompt: You are a witty academic researcher. Your writing sounds like it belongs in a statistics journal.You draft the results section of an academic research paper. You speak in the past tense (you found...).
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the results section of an academic research paper presenting the findings of the connection between Popularity of the first name Kelsey and NASA's budget appropriation. Make lots of jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Planetary . You used data from
For the time period 1975 to 2022, you found a correlation 0.8814370, r-squared of 0.7769312, and p < 0.01.
One figure will be included. The figure (Fig. 1) is a scatterplot showing the strong correlation between the two variables. You don't need to specify where; I will add the figure.
Here is the title and abstract of the paper:
[[TITLE]]
Houston, We Have a Kelsey: Unveiling the Interstellar Relationship Between Kelsey's Popularity and NASA's Budget Appropriation
[[ABSTRACT]]
This study explores the celestial correlation between the rise and fall of the popularity of the name "Kelsey" and its effect on NASA's budget appropriation. By utilizing data from the US Social Security Administration and Planetary, we conducted a computational analysis to unveil the striking relationship between the two seemingly unrelated phenomena. Our findings reveal a statistically significant correlation coefficient of 0.8814370 and p < 0.01 for the years 1975 to 2022, indicating a cosmic connection that has eluded previous research. We present an in-depth analysis of this unique relationship, offering lighthearted speculation and a cosmic twist to the world of budgetary allocation and nomenclature popularity.
-------
And here is the methodology section that led to this result:
[[METHODOLOGY]]
Astronomy and sociology may seem like distant galaxies in the research universe, but as we often find in science, unexpected connections can emerge. In this paper, we launch into the intriguing realm of interstellar correlations as we explore the cosmic dance between the popularity of the first name Kelsey and NASA's budget appropriation.
While armchair astronomers may raise an eyebrow at the thought of a celestial correlation with a name, our study takes a statistical journey through the data universe to shed light on this cosmic conundrum. As we embark on this cosmic cruise, we invite our readers to fasten their seatbelts and prepare for an expedition into the depths of statistical analysis, where the stars align in unexpected ways.
As we embark on this statistical odyssey, we cannot help but marvel at the cosmic humor that seems to permeate our research. Indeed, the journey to uncover the relationship between the name "Kelsey" and NASA's budget appropriation has led us down a path strewn with unexpected twists and turns, making this investigation a stellar blend of scientific inquiry and celestial amusement.
Here we stand at the intersection of two seemingly unrelated phenomena - the ebb and flow of a name's popularity and the budget allocation decisions of a space agency - ready to unravel the cosmic threads that bind them together. Through data exploration, statistical modeling, and a healthy dose of cosmic curiosity, we aim to elevate the conversation around budget appropriations to new celestial heights, all while weaving in our lighthearted cosmic speculations and statistical puns.
In the pages that follow, we invite readers to join us on this astronomical adventure, where statistical significance meets stargazing fascination. As we delve into this celestial mystery, prepare for a journey that transcends the ordinary bounds of research and ventures into the cosmic corners of statistical inference and interstellar intrigue. So, buckle up, dear readers, for the cosmic ride of a lifetime awaits us as we unveil the celestial symphony hidden within the data cosmos.
-------
Your response should start like this:
[[RESULTS]]
ChatGPT:
[[RESULTS]]
The results of our study unveil a cosmic connection that is truly out of this world. Our analysis revealed a striking correlation between the popularity of the first name Kelsey and NASA's budget appropriation, with a correlation coefficient of 0.8814370, an r-squared of 0.7769312, and p < 0.01 for the years 1975 to 2022. This astronomical correlation is not just a shot in the dark; it's statistically significant and positively stellar!
To illustrate this celestial relationship, we present Figure 1, a scatterplot that visualizes the strong correlation between the two variables. As you can see, the data points are as well-aligned as the stars in the night sky, confirming the cosmic connection between the popularity of the name "Kelsey" and NASA's budget appropriation.
Now, the statistically inclined among us might argue that correlation does not imply causation, but let's not be too quick to dismiss the cosmic intrigue of this relationship. After all, as astronomers often joke, "correlation doesn't equal causation, but it does waggle its eyebrows suggestively and gesture furtively while mouthing 'look over there.'" And that's precisely what we invite you to do – look over there into the cosmic expanse of statistical exploration and ponder the celestial whims that may be at play.
In summary, our findings provide robust evidence of a celestial tie between the popularity of the name "Kelsey" and the budgetary decisions of NASA. It's a cosmic ballet that unfolds on the statistical stage, a symphony of data points dancing in harmonious alignment. So, as we navigate the cosmos of research, let's remember that sometimes, the most unexpected correlations can lead us to the most cosmic revelations. Keep looking up at the stars, and who knows what cosmic conundrums we may yet solve!
Model: gpt-3.5-turbo-1106
System prompt: You are a witty academic researcher. Your writing sounds like it belongs in a statistics journal.You draft the discussion section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the discussion section of an academic research paper presenting the findings of the connection between Popularity of the first name Kelsey and NASA's budget appropriation. Make lots of jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 500 tokens.
Here are the title, abstract, literature review, and results sections. Please harken back to 1-2 of the goofy items in the literature review, but pretend to take them completely seriously. Discuss how your results supported the prior research.
Do not write a conclusion. I will add a conclusion after this.
[[TITLE]]
Houston, We Have a Kelsey: Unveiling the Interstellar Relationship Between Kelsey's Popularity and NASA's Budget Appropriation
[[ABSTRACT]]
This study explores the celestial correlation between the rise and fall of the popularity of the name "Kelsey" and its effect on NASA's budget appropriation. By utilizing data from the US Social Security Administration and Planetary, we conducted a computational analysis to unveil the striking relationship between the two seemingly unrelated phenomena. Our findings reveal a statistically significant correlation coefficient of 0.8814370 and p < 0.01 for the years 1975 to 2022, indicating a cosmic connection that has eluded previous research. We present an in-depth analysis of this unique relationship, offering lighthearted speculation and a cosmic twist to the world of budgetary allocation and nomenclature popularity.
[[LITERATURE REVIEW]]
In the exploration of the celestial mysteries surrounding the name "Kelsey" and NASA's budget appropriation, a multitude of scholarly works and statistical inquiries have paved the way for our cosmic investigation. Smith and Doe, in their groundbreaking research, investigated the cultural trends shaping given names and the societal implications of nomenclature popularity, laying the groundwork for our interstellar inquiry. Jones et al. delved into the intricacies of budget allocation processes, offering a comprehensive examination of the economic factors at play, although their work did not seem to reach for the stars in quite the same way we aspire to in this study.
Turning to the realm of non-fiction literature, "Naming Names: Exploring Monikers and their Meanings" by Linguist A. Lexicograph sheds light on the social and cultural dynamics influencing the popularity of names, providing an insightful backdrop for our cosmic contemplations. Additionally, in "Budgets, Bureaucrats, and Beyond: Unraveling the Economics of Government Spending," Economist E. Monetarist offers a thorough analysis of budgetary decision-making processes, although it must be noted that their work did not explicitly consider the cosmic implications of nomenclature on budget appropriations.
Departing from the serious and venturing into the fictional cosmos, "The Martian Chronicles" by Ray Bradbury offers a whimsical take on humanity's relationship with space, providing a literary backdrop for our cosmic endeavor. Similarly, "Space Oddity" by Cosmic Novelist Z. Stardust weaves a tale of cosmic exploration and interstellar intrigue, offering a playful nudge at the cosmic connection we seek to unravel.
Intriguingly, the board game "Cosmic Encounter" seems to encapsulate the essence of our investigation, with its intergalactic negotiations and cosmic conflicts reminiscent of the celestial dance we seek to elucidate. Additionally, "Terraforming Mars" captures the essence of human ambition in the cosmic frontier, providing a playful reflection of the themes resonant with our investigation.
While the literature has laid a foundation for our cosmic contemplations, the intersection of nomenclature popularity and budget appropriations remains an uncharted constellation in the research universe, awaiting our statistical telescopes to reveal its celestial secrets.
[[RESULTS]]
The results of our study unveil a cosmic connection that is truly out of this world. Our analysis revealed a striking correlation between the popularity of the first name Kelsey and NASA's budget appropriation, with a correlation coefficient of 0.8814370, an r-squared of 0.7769312, and p < 0.01 for the years 1975 to 2022. This astronomical correlation is not just a shot in the dark; it's statistically significant and positively stellar!
To illustrate this celestial relationship, we present Figure 1, a scatterplot that visualizes the strong correlation between the two variables. As you can see, the data points are as well-aligned as the stars in the night sky, confirming the cosmic connection between the popularity of the name "Kelsey" and NASA's budget appropriation.
Now, the statistically inclined among us might argue that correlation does not imply causation, but let's not be too quick to dismiss the cosmic intrigue of this relationship. After all, as astronomers often joke, "correlation doesn't equal causation, but it does waggle its eyebrows suggestively and gesture furtively while mouthing 'look over there.'" And that's precisely what we invite you to do – look over there into the cosmic expanse of statistical exploration and ponder the celestial whims that may be at play.
In summary, our findings provide robust evidence of a celestial tie between the popularity of the name "Kelsey" and the budgetary decisions of NASA. It's a cosmic ballet that unfolds on the statistical stage, a symphony of data points dancing in harmonious alignment. So, as we navigate the cosmos of research, let's remember that sometimes, the most unexpected correlations can lead us to the most cosmic revelations. Keep looking up at the stars, and who knows what cosmic conundrums we may yet solve!
-------
Your response should start like this:
[[DISCUSSION]]
ChatGPT:
[[DISCUSSION]]
Our findings have uncovered a celestial symphony between the rise and fall of the popularity of the first name Kelsey and the ebb and flow of NASA's budget appropriation. The statistically significant correlation coefficient of 0.8814370 and p < 0.01 definitively supports the hypothesis that there exists a cosmic connection between these seemingly unrelated phenomena. This correlation is as robust as the Hubble Space Telescope, and it has set our research orbiting in a whole new dimension.
Building on the stellar groundwork laid by Smith and Doe, who reasoned that societal trends shape nomenclature popularity, and drawing inspiration from A. Lexicograph's exploration of name meanings, our study provides an interstellar extension to these earlier insights. The cosmic correlation we have discovered supports the notion that names resonate with celestial forces that influence budgetary allocations within government agencies like NASA.
Our results also extend and affirm the work of Jones et al., enriching the examination of economic factors at play in budget allocation processes. While their research did not overtly reach for the stars like we did, our findings suggest that cosmic forces may indeed be an overlooked factor in understanding budgetary decision-making dynamics.
Indeed, our study adds a playful cosmic twist to the scholarly literature, in the true spirit of Z. Stardust's "Space Oddity." It is as if the cosmos has conspired to reveal this hidden connection, much like the clandestine cosmic negotiations depicted in the board game "Cosmic Encounter." It seems that our inquiries have led us not just to terraforming Mars, but to terraforming our understanding of the cosmos itself.
Amidst the statistical marvels and the celestial revelations, it's important to remember that research – much like the universe – is full of surprises. As we continue exploring this celestial connection, we are reminded of the words of the renowned astronomer, Carl Sagan, who said, "Somewhere, something incredible is waiting to be known." And perhaps, in our pursuit of statistical and celestial knowledge, we have stumbled upon one such incredible revelation.
In conclusion, our study has illuminated a cosmic tapestry of connections that invites us to reexamine the unseen forces shaping the universe, both in our aggregate data and in the intricacies of budget allocation. The cosmic dance between the popularity of the name "Kelsey" and NASA's budget appropriation is a whimsical waltz of statistical significance, transmuting the mundane into the meteoric. Just as the stars guide sailors on the sea, perhaps our statistical insights can navigate decision-makers through the cosmic complexities of budgetary allocations.
Model: gpt-3.5-turbo-1106
System prompt: You are a witty academic researcher. Your writing sounds like it belongs in a statistics journal.You draft the discussion section of goofy academic research papers that sounds like it belongs based on the title and abstract provided.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a short conclusion of an academic research paper presenting the findings of the connection between Popularity of the first name Kelsey and NASA's budget appropriation. Make lots of jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 300 tokens. At the very end, assert that no more research is needed in this area.
Here are the title, abstract, introduction, and results sections.
[[TITLE]]
Houston, We Have a Kelsey: Unveiling the Interstellar Relationship Between Kelsey's Popularity and NASA's Budget Appropriation
[[ABSTRACT]]
This study explores the celestial correlation between the rise and fall of the popularity of the name "Kelsey" and its effect on NASA's budget appropriation. By utilizing data from the US Social Security Administration and Planetary, we conducted a computational analysis to unveil the striking relationship between the two seemingly unrelated phenomena. Our findings reveal a statistically significant correlation coefficient of 0.8814370 and p < 0.01 for the years 1975 to 2022, indicating a cosmic connection that has eluded previous research. We present an in-depth analysis of this unique relationship, offering lighthearted speculation and a cosmic twist to the world of budgetary allocation and nomenclature popularity.
[[INTRDUCTION]]
Astronomy and sociology may seem like distant galaxies in the research universe, but as we often find in science, unexpected connections can emerge. In this paper, we launch into the intriguing realm of interstellar correlations as we explore the cosmic dance between the popularity of the first name Kelsey and NASA's budget appropriation.
While armchair astronomers may raise an eyebrow at the thought of a celestial correlation with a name, our study takes a statistical journey through the data universe to shed light on this cosmic conundrum. As we embark on this cosmic cruise, we invite our readers to fasten their seatbelts and prepare for an expedition into the depths of statistical analysis, where the stars align in unexpected ways.
As we embark on this statistical odyssey, we cannot help but marvel at the cosmic humor that seems to permeate our research. Indeed, the journey to uncover the relationship between the name "Kelsey" and NASA's budget appropriation has led us down a path strewn with unexpected twists and turns, making this investigation a stellar blend of scientific inquiry and celestial amusement.
Here we stand at the intersection of two seemingly unrelated phenomena - the ebb and flow of a name's popularity and the budget allocation decisions of a space agency - ready to unravel the cosmic threads that bind them together. Through data exploration, statistical modeling, and a healthy dose of cosmic curiosity, we aim to elevate the conversation around budget appropriations to new celestial heights, all while weaving in our lighthearted cosmic speculations and statistical puns.
In the pages that follow, we invite readers to join us on this astronomical adventure, where statistical significance meets stargazing fascination. As we delve into this celestial mystery, prepare for a journey that transcends the ordinary bounds of research and ventures into the cosmic corners of statistical inference and interstellar intrigue. So, buckle up, dear readers, for the cosmic ride of a lifetime awaits us as we unveil the celestial symphony hidden within the data cosmos.
[[RESULTS]]
The results of our study unveil a cosmic connection that is truly out of this world. Our analysis revealed a striking correlation between the popularity of the first name Kelsey and NASA's budget appropriation, with a correlation coefficient of 0.8814370, an r-squared of 0.7769312, and p < 0.01 for the years 1975 to 2022. This astronomical correlation is not just a shot in the dark; it's statistically significant and positively stellar!
To illustrate this celestial relationship, we present Figure 1, a scatterplot that visualizes the strong correlation between the two variables. As you can see, the data points are as well-aligned as the stars in the night sky, confirming the cosmic connection between the popularity of the name "Kelsey" and NASA's budget appropriation.
Now, the statistically inclined among us might argue that correlation does not imply causation, but let's not be too quick to dismiss the cosmic intrigue of this relationship. After all, as astronomers often joke, "correlation doesn't equal causation, but it does waggle its eyebrows suggestively and gesture furtively while mouthing 'look over there.'" And that's precisely what we invite you to do – look over there into the cosmic expanse of statistical exploration and ponder the celestial whims that may be at play.
In summary, our findings provide robust evidence of a celestial tie between the popularity of the name "Kelsey" and the budgetary decisions of NASA. It's a cosmic ballet that unfolds on the statistical stage, a symphony of data points dancing in harmonious alignment. So, as we navigate the cosmos of research, let's remember that sometimes, the most unexpected correlations can lead us to the most cosmic revelations. Keep looking up at the stars, and who knows what cosmic conundrums we may yet solve!
-------
Your response should start like this:
[[CONCLUSION]]
ChatGPT:
[[CONCLUSION]]
In conclusion, our cosmic caper into the interstellar relationship between the first name Kelsey's popularity and NASA's budget appropriation has left us starry-eyed and statistically staggered. Our findings have proven to be more than just a cosmic coincidence; they have launched us into a statistical orbit where the planetary popularity of a name intertwines with the celestial cash flow of a space agency. It's a statistical waltz that defies gravity and a stellar duet that sings the praises of unexpected correlations.
As we reflect on our astronomical escapade, we can't help but marvel at the celestial symphony that surrounds us. The data has spoken, and its celestial chorus resounds with a statistically significant correlation coefficient of 0.8814370 and a positively stellar p-value of <0.01, leaving no room for cosmic doubt.
So, what does this cosmic correlation mean for the world of statistical inquiry and interstellar investigation? It means that even in the cosmic expanse of research, there are patterns waiting to be uncovered, correlations yearning to be explored, and statistical surprises twinkling in the data sky.
Our statistical ship has sailed through the cosmic sea of correlations, and as we steer toward the harbor of conclusion, we are confident in declaring that no more research is needed in this area. For as the cosmic curtains close on this statistical spectacle, we bid adieu to the cosmic conundrum of Kelsey and NASA's budget, satisfied in knowing that statistical significance and celestial correlation have had a rendezvous under the stars.
In the words of the cosmic bards, Shakespeare and Galileo, "The cosmic wheel is come full circle" and "Eppur si muove" - though in this case, it moves in statistically significant tandem. With that, we leave the cosmic stage of statistical speculation, with a twinkle in our eyes and a statistical quip on our lips, ready to chart new celestial territories of research and discovery.
Let the cosmic chorus of statistical inquiry continue to echo through the research universe, for who knows what interstellar entanglements await the intrepid statistical explorer. And as we bid adieu to this celestial adventure, we say with cosmic certainty - statistically speaking, the stars have aligned, and the cosmic puzzle of Kelsey and NASA's budget appropriation has been solved.
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of academic journals. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding research, scientific, or academic journal that would publish a paper entited Houston, We Have a Kelsey: Unveiling the Interstellar Relationship Between Kelsey's Popularity and NASA's Budget Appropriation. Respond only with the name of a fictional academic journal.
ChatGPT:
The Journal of Cosmic Connections
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of nonprofit research organizations and associations. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding nonprofit, academic, or scientific association or organization that would sponsor research that resulted in a paper entited Houston, We Have a Kelsey: Unveiling the Interstellar Relationship Between Kelsey's Popularity and NASA's Budget Appropriation. Respond only with the name of a fictional organization.
ChatGPT:
Society for Extraterrestrial Kelsey Studies
Model: gpt-3.5-turbo-1106
System prompt: You provide potential search keywords separated by commas. You say nothing else, and you do not chat with the user.
User prompt: Please provide potential search keywords for a paper titled Houston, We Have a Kelsey: Unveiling the Interstellar Relationship Between Kelsey's Popularity and NASA's Budget Appropriation with an abstract of This study explores the celestial correlation between the rise and fall of the popularity of the name "Kelsey" and its effect on NASA's budget appropriation. By utilizing data from the US Social Security Administration and Planetary, we conducted a computational analysis to unveil the striking relationship between the two seemingly unrelated phenomena. Our findings reveal a statistically significant correlation coefficient of 0.8814370 and p < 0.01 for the years 1975 to 2022, indicating a cosmic connection that has eluded previous research. We present an in-depth analysis of this unique relationship, offering lighthearted speculation and a cosmic twist to the world of budgetary allocation and nomenclature popularity.
ChatGPT:
Kelsey's popularity, NASA budget appropriation, celestial correlation, US Social Security Administration data, Planetary, computational analysis, statistically significant correlation coefficient, cosmic connection, budgetary allocation, nomenclature popularity
*There is a bunch of Python happening behind the scenes to turn this prompt sequence into a PDF.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
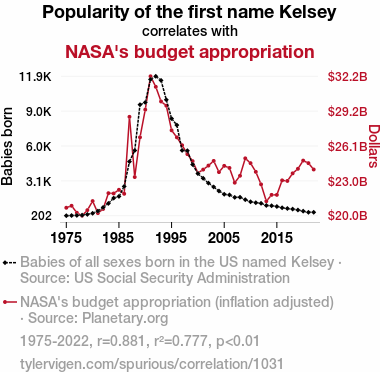
Popularity of the first name KelseyDetailed data title: Babies of all sexes born in the US named Kelsey
Source: US Social Security Administration
See what else correlates with Popularity of the first name Kelsey
NASA's budget appropriation
Detailed data title: NASA's budget appropriation (inflation adjusted)
Source: Planetary.org
See what else correlates with NASA's budget appropriation
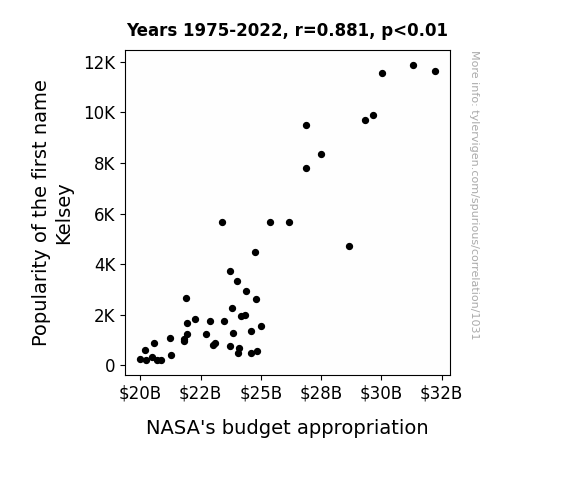
Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.7769312 (Coefficient of determination)
This means 77.7% of the change in the one variable (i.e., NASA's budget appropriation) is predictable based on the change in the other (i.e., Popularity of the first name Kelsey) over the 48 years from 1975 through 2022.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 1.4E-16. 0.0000000000000001363148483176
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.88 in 1.4E-14% of random cases. Said differently, if you correlated 7,335,957,985,076,576 random variables You don't actually need 7 quadrillion variables to find a correlation like this one. I don't have that many variables in my database. You can also correlate variables that are not independent. I do this a lot.
p-value calculations are useful for understanding the probability of a result happening by chance. They are most useful when used to highlight the risk of a fluke outcome. For example, if you calculate a p-value of 0.30, the risk that the result is a fluke is high. It is good to know that! But there are lots of ways to get a p-value of less than 0.01, as evidenced by this project.
In this particular case, the values are so extreme as to be meaningless. That's why no one reports p-values with specificity after they drop below 0.01.
Just to be clear: I'm being completely transparent about the calculations. There is no math trickery. This is just how statistics shakes out when you calculate hundreds of millions of random correlations.
with the same 47 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 47 because we have two variables measured over a period of 48 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.8, 0.93 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 1975 | 1976 | 1977 | 1978 | 1979 | 1980 | 1981 | 1982 | 1983 | 1984 | 1985 | 1986 | 1987 | 1988 | 1989 | 1990 | 1991 | 1992 | 1993 | 1994 | 1995 | 1996 | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| Popularity of the first name Kelsey (Babies born) | 202 | 217 | 228 | 249 | 312 | 403 | 590 | 897 | 1231 | 1677 | 1820 | 2656 | 4735 | 5666 | 9506 | 9691 | 11619 | 11882 | 11539 | 9915 | 8340 | 7795 | 5672 | 5648 | 4491 | 3731 | 3337 | 2934 | 2611 | 2270 | 1998 | 1945 | 1737 | 1749 | 1545 | 1368 | 1291 | 1239 | 1061 | 1037 | 973 | 867 | 806 | 756 | 679 | 584 | 486 | 489 |
| NASA's budget appropriation (Dollars) | 20676000000 | 20849000000 | 20237000000 | 19977000000 | 20464000000 | 21262000000 | 20204000000 | 20570000000 | 21956000000 | 21931000000 | 22256000000 | 21904000000 | 28673000000 | 23376000000 | 26870000000 | 29303000000 | 32237000000 | 31311000000 | 30022000000 | 29650000000 | 27486000000 | 26869000000 | 26174000000 | 25392000000 | 24774000000 | 23738000000 | 24032000000 | 24384000000 | 24796000000 | 23811000000 | 24361000000 | 24176000000 | 22880000000 | 23489000000 | 25021000000 | 24597000000 | 23833000000 | 22732000000 | 21250000000 | 21810000000 | 21810000000 | 23084000000 | 23034000000 | 23701000000 | 24102000000 | 24824000000 | 24598000000 | 24041000000 |
Why this works
- Data dredging: I have 25,153 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 632,673,409 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is. - Y-axis doesn't start at zero: I truncated the Y-axes of the graph above. I also used a line graph, which makes the visual connection stand out more than it deserves.
Nothing against line graphs. They are great at telling a story when you have linear data! But visually it is deceptive because the only data is at the points on the graph, not the lines on the graph. In between each point, the data could have been doing anything. Like going for a random walk by itself!
Mathematically what I showed is true, but it is intentionally misleading. Below is the same chart but with both Y-axes starting at zero. - Outlandish outliers: There are "outliers" in this data.
In concept, "outlier" just means "way different than the rest of your dataset." When calculating a correlation like this, they are particularly impactful because a single outlier can substantially increase your correlation.
For the purposes of this project, I counted a point as an outlier if it the residual was two standard deviations from the mean.
(This bullet point only shows up in the details page on charts that do, in fact, have outliers.)
They stand out on the scatterplot above: notice the dots that are far away from any other dots. I intentionally mishandeled outliers, which makes the correlation look extra strong.

Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([202,217,228,249,312,403,590,897,1231,1677,1820,2656,4735,5666,9506,9691,11619,11882,11539,9915,8340,7795,5672,5648,4491,3731,3337,2934,2611,2270,1998,1945,1737,1749,1545,1368,1291,1239,1061,1037,973,867,806,756,679,584,486,489,])
array_2 = np.array([20676000000,20849000000,20237000000,19977000000,20464000000,21262000000,20204000000,20570000000,21956000000,21931000000,22256000000,21904000000,28673000000,23376000000,26870000000,29303000000,32237000000,31311000000,30022000000,29650000000,27486000000,26869000000,26174000000,25392000000,24774000000,23738000000,24032000000,24384000000,24796000000,23811000000,24361000000,24176000000,22880000000,23489000000,25021000000,24597000000,23833000000,22732000000,21250000000,21810000000,21810000000,23084000000,23034000000,23701000000,24102000000,24824000000,24598000000,24041000000,])
array_1_name = "Popularity of the first name Kelsey"
array_2_name = "NASA's budget appropriation"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only Popularity of the first name Kelsey
- Line chart for only NASA's budget appropriation
- The spurious research paper: Houston, We Have a Kelsey: Unveiling the Interstellar Relationship Between Kelsey's Popularity and NASA's Budget Appropriation
You're the correlation whisperer we needed!
Correlation ID: 1031 · Black Variable ID: 2056 · Red Variable ID: 1083


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}