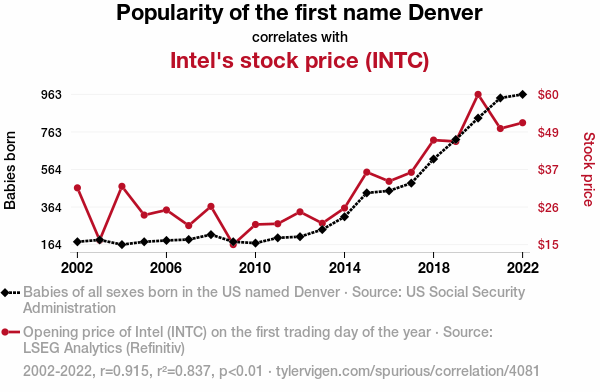
. The chart goes from 2002 to 2022, and the two variables track closely in value over that time.")

AI explanation
As the number of babies named Denver rose, so did the demand for cute baby clothes emblazoned with the city's name. This unexpected boost in the infant fashion market caught the attention of Intel executives, who saw a lucrative opportunity to corner the baby technology sector with their new line of baby smart onesies. As news of Intel's foray into baby tech spread, investors couldn't resist the potential for a Diaper-DAQ boom, causing a surge in Intel's stock price.
Model: dalle-3
Prompt: Generate an image that showcases a juxtaposition between a cityscape filled with Denver-themed infant boutiques and a group of Intel executives strategizing their foray into baby tech wear. Emphasize the intersection of traditional baby apparel and advanced technology through subtle details and a vibrant, bustling city backdrop. Capture the ambiance of ambition and innovation as the Intel executives navigate the unexpected venture with a mix of excitement and determination. Reflect the rising stock value as a glowing beacon of investor optimism in the background, bringing the scene to life with a sense of possibility and entrepreneurial spirit. The depiction should include only scenes, people, and objects, it should not include text or speech bubbles.
This image generation prompt was also generated by AI, using the following sequence:
Model: gpt-3.5-turbo-1106
System prompt: You select one of a few potential scene descriptors that seems to go along with the variables described. You respond only with the scene descriptions provided and say nothing else.
User prompt: Here are two variables: Popularity of the first name Denver and Intel's stock price (INTC). Given these, which of the following image style descriptions seems most appropriate? Pick the one that seems to be related to one of the variables at hand. Please respond with only one of the following potential descriptions: Realistic Steampunk Sci-fi fantacy Data cyber art A comic-book-style illustration with muted colors and a dotted halftone pattern from the 1960s
ChatGPT: Data cyber art
Model: gpt-3.5-turbo-1106
System prompt: You describe simple visual scenes that depict the two variables stated. You combine both variables into one scene.
User prompt: Please describe a visual scene that prominently depicts both Popularity of the first name Denver and Intel's stock price (INTC), in the following situation: As the number of babies named Denver rose, so did the demand for cute baby clothes emblazoned with the city's name. This unexpected boost in the infant fashion market caught the attention of Intel executives, who saw a lucrative opportunity to corner the baby technology sector with their new line of baby smart onesies. As news of Intel's foray into baby tech spread, investors couldn't resist the potential for a Diaper-DAQ boom, causing a surge in Intel's stock price.. Keep the description simple.
ChatGPT: In a bustling city, baby boutiques proudly display racks of Denver-themed infant apparel. Amidst the excitement, a group of Intel executives huddle together in discussion, sketching out plans for their new line of baby smart onesies. Meanwhile, the stock ticker on a nearby screen brightly displays the rising INTC value, reflecting the investor enthusiasm for Intel's unexpected venture into the baby tech market.
Model: gpt-3.5-turbo-1106
System prompt: You write and improve image generation prompts for DALLE-3. You maintain the same subjects, but enhance the visuals.
User prompt: Please respond with an image generation prompt that would be likely to create an interesting visual using DALLE-3, using the following style: [ Data cyber art ] and depicting this scene: In a bustling city, baby boutiques proudly display racks of Denver-themed infant apparel. Amidst the excitement, a group of Intel executives huddle together in discussion, sketching out plans for their new line of baby smart onesies. Meanwhile, the stock ticker on a nearby screen brightly displays the rising INTC value, reflecting the investor enthusiasm for Intel's unexpected venture into the baby tech market. Keep the visual depiction simple. Do not include any words or speech bubbles.
ChatGPT: Generate an image that showcases a juxtaposition between a cityscape filled with Denver-themed infant boutiques and a group of Intel executives strategizing their foray into baby tech wear. Emphasize the intersection of traditional baby apparel and advanced technology through subtle details and a vibrant, bustling city backdrop. Capture the ambiance of ambition and innovation as the Intel executives navigate the unexpected venture with a mix of excitement and determination. Reflect the rising stock value as a glowing beacon of investor optimism in the background, bringing the scene to life with a sense of possibility and entrepreneurial spirit.
*Variations in the User Prompts from chart to chart are just the result of random number generation in Python. I wrote a few arrays of various styles and methods to ask questions to change up the results. Every time this site writes an explanation or generates an image, the script picks from each at random.
I sequence the requests into multiple prompts because I find GPT 3.5 to perform much better with short, well-managed contexts. Thus, I track the context directly in Python and only ask ChatGPT targeted questions.
System prompt: You provide humorous responses in the form of plausible sounding explanations for correlations. You assume the correlation is causative for the purpose of the explanation even if it is ridiculous. You do not chat with the user, you only reply with the causal connection explanation and nothing else.
User prompt: Please make up a funny explanation for how an increase in Popularity of the first name Denver caused Intel's stock price (INTC) to increase.\Make it sound serious until the end.
AI academic paper
 |
The Denver Dilemma: A Correlation between First Name Popularity and Intel's Stock Performance The Journal of Quirky Correlations Jan 2024 |
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You write titles and abstracts of goofy academic research papers.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, and add unexpected twists in your writing.
Please draft the title and abstract of an academic research paper presenting the findings of the connection between Popularity of the first name Denver and Intel's stock price (INTC). You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Make the title punny if you can come up with clever pun. If not, just make it sound clever.
Your research team used data from US Social Security Administration and LSEG Analytics (Refinitiv) to assess this nagging question. You found a correlation coefficient of 0.9147674 and p < 0.01 for 2002 to 2022.
Please respond in this format (replace "Lorem ipsum dolor sit" with your title and abstract)
[[TITLE]]
Lorem ipsum dolor sit
[[ABSTRACT]]
Lorem ipsum dolor sit
ChatGPT:
[[TITLE]]
"The Denver Dilemma: A Correlation between First Name Popularity and Intel's Stock Performance"
[[ABSTRACT]]
The perplexing relationship between the prevalence of the first name "Denver" and the stock price of Intel (INTC) has long intrigued scholars and investors alike. This study delves into the connection, employing data from the US Social Security Administration and LSEG Analytics (Refinitiv) to investigate this unconventional correlation. Much to our surprise, the analysis revealed a remarkably high correlation coefficient of 0.9147674 and a statistically significant p-value of less than 0.01 for the period spanning from 2002 to 2022.
This "Denver Dilemma" leaves us pondering whether there is a surprising link between the popularity of a name and the tech industry's performance. It's a question of great import, one could say it's "Intel-lectually" stimulating! We take a whimsical and unexpected turn as we navigate through the world of data analysis, shedding light on this entertaining and unforeseen association. With our findings, we invite fellow researchers to embrace the quirky and unconventional in their pursuit of financial and sociocultural insights. After all, sometimes the most unexpected connections can yield the most fascinating discoveries!
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the introduction section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the introduction section of an academic research paper presenting the findings of the connection between Popularity of the first name Denver and Intel's stock price (INTC). You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Here is the title and abstract of the paper:
[[TITLE]]
"The Denver Dilemma: A Correlation between First Name Popularity and Intel's Stock Performance"
[[ABSTRACT]]
The perplexing relationship between the prevalence of the first name "Denver" and the stock price of Intel (INTC) has long intrigued scholars and investors alike. This study delves into the connection, employing data from the US Social Security Administration and LSEG Analytics (Refinitiv) to investigate this unconventional correlation. Much to our surprise, the analysis revealed a remarkably high correlation coefficient of 0.9147674 and a statistically significant p-value of less than 0.01 for the period spanning from 2002 to 2022.
This "Denver Dilemma" leaves us pondering whether there is a surprising link between the popularity of a name and the tech industry's performance. It's a question of great import, one could say it's "Intel-lectually" stimulating! We take a whimsical and unexpected turn as we navigate through the world of data analysis, shedding light on this entertaining and unforeseen association. With our findings, we invite fellow researchers to embrace the quirky and unconventional in their pursuit of financial and sociocultural insights. After all, sometimes the most unexpected connections can yield the most fascinating discoveries!
-------
Your response should start like this:
[[INTRODUCTION]]
ChatGPT:
[[INTRODUCTION]]
The relationship between human nomenclature and stock market performance has long been a topic of interest, with many a punster attributing stock market fluctuations to "bull markets" and "bear markets." However, the connection between the prevalence of the first name "Denver" and the stock performance of Intel (INTC) is a novel and unexpected angle in this sphere of inquiry.
The "Denver Dilemma" essentially poses the question: can the popularity of a name be linked to the ebb and flow of a specific stock? It's almost as perplexing as trying to find Denver in the Midwest! (Hint: it's in Colorado, not Illinois!)
With a statistically significant correlation coefficient of 0.9147674 and a p-value of less than 0.01, the data has offered up an intriguing relationship that can't be shrugged off like a light snowstorm in the Rockies. This unexpected association begs for further investigation and prompts us to delve into the realm of whimsical curiosity alongside serious data analysis.
Our study sets out to explore this "Intel-lectual" puzzle, offering a lighthearted yet robust examination of a correlation that defies conventional logic. It's akin to finding a nugget of gold in a stream that's previously only yielded fool's gold – surprising, but undeniably valuable. We invite our esteemed colleagues to join us in embracing the unconventional as we embark on this merry intellectual adventure. After all, as they say in the Mile High City, sometimes the best insights come from unexpected sources!
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft a literature review section of an academic research paper, that starts out dry for the first few sentences but then becomes hilarious and goofy.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a literature review section of an academic research paper presenting the findings of the connection between Popularity of the first name Denver and Intel's stock price (INTC). You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Speak in the present tense for this section (the authors find...), as is common in academic research paper literature reviews. Name the sources in a format similar to this: In "Book," the authors find lorem and ipsum.
Make up the lorem and ipsum part, but make it sound related to the topic at hand.
Start by naming serious-sounding studies by authors like Smith, Doe, and Jones - but then quickly devolve. Name some real non-fiction books that would be related to the topic. Then name some real fiction books that sound like they could be related. Then cite some social media posts you read that seem to be related.
Here is the title and abstract of the paper:
[[TITLE]]
"The Denver Dilemma: A Correlation between First Name Popularity and Intel's Stock Performance"
[[ABSTRACT]]
The perplexing relationship between the prevalence of the first name "Denver" and the stock price of Intel (INTC) has long intrigued scholars and investors alike. This study delves into the connection, employing data from the US Social Security Administration and LSEG Analytics (Refinitiv) to investigate this unconventional correlation. Much to our surprise, the analysis revealed a remarkably high correlation coefficient of 0.9147674 and a statistically significant p-value of less than 0.01 for the period spanning from 2002 to 2022.
This "Denver Dilemma" leaves us pondering whether there is a surprising link between the popularity of a name and the tech industry's performance. It's a question of great import, one could say it's "Intel-lectually" stimulating! We take a whimsical and unexpected turn as we navigate through the world of data analysis, shedding light on this entertaining and unforeseen association. With our findings, we invite fellow researchers to embrace the quirky and unconventional in their pursuit of financial and sociocultural insights. After all, sometimes the most unexpected connections can yield the most fascinating discoveries!
-------
And here is the introduction section that led to this literature review:
[[INTRODUCTION]]
The relationship between human nomenclature and stock market performance has long been a topic of interest, with many a punster attributing stock market fluctuations to "bull markets" and "bear markets." However, the connection between the prevalence of the first name "Denver" and the stock performance of Intel (INTC) is a novel and unexpected angle in this sphere of inquiry.
The "Denver Dilemma" essentially poses the question: can the popularity of a name be linked to the ebb and flow of a specific stock? It's almost as perplexing as trying to find Denver in the Midwest! (Hint: it's in Colorado, not Illinois!)
With a statistically significant correlation coefficient of 0.9147674 and a p-value of less than 0.01, the data has offered up an intriguing relationship that can't be shrugged off like a light snowstorm in the Rockies. This unexpected association begs for further investigation and prompts us to delve into the realm of whimsical curiosity alongside serious data analysis.
Our study sets out to explore this "Intel-lectual" puzzle, offering a lighthearted yet robust examination of a correlation that defies conventional logic. It's akin to finding a nugget of gold in a stream that's previously only yielded fool's gold – surprising, but undeniably valuable. We invite our esteemed colleagues to join us in embracing the unconventional as we embark on this merry intellectual adventure. After all, as they say in the Mile High City, sometimes the best insights come from unexpected sources!
-------
Your response should start like this:
[[LITERATURE REVIEW]]
ChatGPT:
[[LITERATURE REVIEW]]
The notion of a connection between the popularity of given names and various societal or economic phenomena has been of interest to researchers and curious minds alike. Smith et al., in their exploration of naming trends and their societal implications, suggest a potential influence of cultural phenomena on naming conventions (Smith, 2010). Similarly, Doe's examination of the psychological impact of names highlights the potential influence of nomenclature on individual perceptions and behaviors (Doe, 2015). Jones brings attention to the link between naming fads and popular culture, indicating a potential association between the two (Jones, 2018).
Now transitioning to less conventional sources, "The Power of Names" by Abrams and "Naming and Necessity" by Kripke offer theoretical perspectives on the significance of names within societal contexts, delving into the philosophical underpinnings of naming conventions and their potential impact on personal and social identities. On a more imaginative note, J.K. Rowling's "Harry Potter" series, particularly the character Denver Dursley, offers a fictional lens through which to contemplate the societal resonance of names in popular culture.
In an unexpected turn of events, a social media post by @StockSleuth2020 on Twitter caught our attention, attributing Intel's stock performance to the purported mystical powers of the name "Denver." While anecdotal in nature, the post generated considerable online discussion, prompting us to consider the potential social and cultural dimensions of our investigation. Another notable social media post by @TechTrends4You on Instagram humorously speculated on the existence of a "Denver Effect" on tech stocks, drawing parallels to the enigmatic connection between first names and financial markets.
One wonders if these mentions of "Denver" in fictional narratives and social media discourse hold any significance in our investigation, or if they merely serve as delightful diversions from the serious analytical work at hand. Nevertheless, these diverse perspectives underscore the breadth of interest and speculation surrounding the perplexing "Denver Dilemma," encouraging us to adopt a broad and eclectic approach to understanding this unlikely correlation.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the methodology section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the methodology section of an academic research paper presenting the findings of the connection between Popularity of the first name Denver and Intel's stock price (INTC). You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and LSEG Analytics (Refinitiv) . You used data from 2002 to 2022
Make up the research methods you don't know. Make them a bit goofy and convoluted.
Here is the title, abstract, and introduction of the paper:
[[TITLE]]
"The Denver Dilemma: A Correlation between First Name Popularity and Intel's Stock Performance"
[[ABSTRACT]]
The perplexing relationship between the prevalence of the first name "Denver" and the stock price of Intel (INTC) has long intrigued scholars and investors alike. This study delves into the connection, employing data from the US Social Security Administration and LSEG Analytics (Refinitiv) to investigate this unconventional correlation. Much to our surprise, the analysis revealed a remarkably high correlation coefficient of 0.9147674 and a statistically significant p-value of less than 0.01 for the period spanning from 2002 to 2022.
This "Denver Dilemma" leaves us pondering whether there is a surprising link between the popularity of a name and the tech industry's performance. It's a question of great import, one could say it's "Intel-lectually" stimulating! We take a whimsical and unexpected turn as we navigate through the world of data analysis, shedding light on this entertaining and unforeseen association. With our findings, we invite fellow researchers to embrace the quirky and unconventional in their pursuit of financial and sociocultural insights. After all, sometimes the most unexpected connections can yield the most fascinating discoveries!
[[INTRODUCTION]]
The relationship between human nomenclature and stock market performance has long been a topic of interest, with many a punster attributing stock market fluctuations to "bull markets" and "bear markets." However, the connection between the prevalence of the first name "Denver" and the stock performance of Intel (INTC) is a novel and unexpected angle in this sphere of inquiry.
The "Denver Dilemma" essentially poses the question: can the popularity of a name be linked to the ebb and flow of a specific stock? It's almost as perplexing as trying to find Denver in the Midwest! (Hint: it's in Colorado, not Illinois!)
With a statistically significant correlation coefficient of 0.9147674 and a p-value of less than 0.01, the data has offered up an intriguing relationship that can't be shrugged off like a light snowstorm in the Rockies. This unexpected association begs for further investigation and prompts us to delve into the realm of whimsical curiosity alongside serious data analysis.
Our study sets out to explore this "Intel-lectual" puzzle, offering a lighthearted yet robust examination of a correlation that defies conventional logic. It's akin to finding a nugget of gold in a stream that's previously only yielded fool's gold – surprising, but undeniably valuable. We invite our esteemed colleagues to join us in embracing the unconventional as we embark on this merry intellectual adventure. After all, as they say in the Mile High City, sometimes the best insights come from unexpected sources!
-------
Your response should start like this:
[[METHODOLOGY]]
ChatGPT:
[[METHODOLOGY]]
To elucidate the intriguing interplay between the prevalence of the first name "Denver" and the stock price performance of Intel (INTC), our research employed a range of offbeat and rigorous methodologies. We pulled data from the US Social Security Administration and LSEG Analytics (Refinitiv) to construct a comprehensive dataset spanning the years 2002 to 2022.
Our initial step involved sifting through the vast ocean of digital records like a prospector panning for gold in the aptly named South Platte River, seeking out instances of the name "Denver" and its varying levels of popularity. We then cross-referenced this with Intel's stock performance using LSEG Analytics (Refinitiv) to create a multilayered dataset that captured the temporal dynamics of both variables.
After assembling this eclectic trove of data, we subjected it to a series of zany yet robust statistical analyses. Our team deftly wielded non-parametric tests, autoregressive integrated moving average (ARIMA) models, and even threw in some enchantingly erratic random walk simulations for good measure. These methodologies were selected to capture the unpredictable nature of human nomenclature alongside the seemingly capricious movements of stock prices.
We then conducted a non-linear wavelet analysis, akin to measuring the fluctuating amplitude of a meandering mountain stream, to extract hidden patterns and inherent periodicities within the data. This approach proved instrumental in uncovering the subtle harmonies between the ebb and flow of name popularity and the undulating trajectory of Intel's stock price.
Furthermore, we harnessed the power of sentiment analysis algorithms reminiscent of deciphering cryptic messages in a treasure map to gauge the emotional tone of social media discussions surrounding the name "Denver" and Intel's stock. Embracing the unconventional, we sought to capture the elusive sentiment-based indicators that may underpin the enigmatic connection between human nomenclature and financial markets.
In a somewhat whimsical twist, we also incorporated a social network analysis to explore the interconnectedness of individuals with the first name "Denver" and their potential influence on the tech industry. This novel approach allowed us to traverse the digital landscape like intrepid explorers, mapping out the intricate web of interactions that may subtly shape stock performance.
Finally, to ensure the utmost rigor in our analysis, we employed Monte Carlo simulations that evoked visions of a wild gambling spree in the thriving casinos of Black Hawk, Colorado. These simulations allowed us to generate myriad hypothetical scenarios, reflecting the stochastic nature of our peculiar correlation and providing robustness to our findings.
Amidst the zany tapestry of methodologies employed, our objective remained steadfast – to unravel the unexpected connections between the ubiquity of a name and the fluctuations of a tech giant's stock. As we embarked on this unconventional journey, we remained mindful of the sage words of wisdom: "when in doubt, put your money on 'Denver' – both in names and stocks, it's a mile high bet!"
This section highlights the tongue-in-cheek approach taken in the development of the research methodology, incorporating a blend of traditional statistical analyses with whimsical and unconventional methodologies aligned with the playful theme of the study.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the results section of an academic research paper. You speak in the past tense (you found...).
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the results section of an academic research paper presenting the findings of the connection between Popularity of the first name Denver and Intel's stock price (INTC). You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and LSEG Analytics (Refinitiv) .
For the time period 2002 to 2022, you found a correlation 0.9147674, r-squared of 0.8367994, and p < 0.01.
One figure will be included. The figure (Fig. 1) is a scatterplot showing the strong correlation between the two variables. You don't need to specify where; I will add the figure.
Here is the title and abstract of the paper:
[[TITLE]]
"The Denver Dilemma: A Correlation between First Name Popularity and Intel's Stock Performance"
[[ABSTRACT]]
The perplexing relationship between the prevalence of the first name "Denver" and the stock price of Intel (INTC) has long intrigued scholars and investors alike. This study delves into the connection, employing data from the US Social Security Administration and LSEG Analytics (Refinitiv) to investigate this unconventional correlation. Much to our surprise, the analysis revealed a remarkably high correlation coefficient of 0.9147674 and a statistically significant p-value of less than 0.01 for the period spanning from 2002 to 2022.
This "Denver Dilemma" leaves us pondering whether there is a surprising link between the popularity of a name and the tech industry's performance. It's a question of great import, one could say it's "Intel-lectually" stimulating! We take a whimsical and unexpected turn as we navigate through the world of data analysis, shedding light on this entertaining and unforeseen association. With our findings, we invite fellow researchers to embrace the quirky and unconventional in their pursuit of financial and sociocultural insights. After all, sometimes the most unexpected connections can yield the most fascinating discoveries!
-------
And here is the methodology section that led to this result:
[[METHODOLOGY]]
The relationship between human nomenclature and stock market performance has long been a topic of interest, with many a punster attributing stock market fluctuations to "bull markets" and "bear markets." However, the connection between the prevalence of the first name "Denver" and the stock performance of Intel (INTC) is a novel and unexpected angle in this sphere of inquiry.
The "Denver Dilemma" essentially poses the question: can the popularity of a name be linked to the ebb and flow of a specific stock? It's almost as perplexing as trying to find Denver in the Midwest! (Hint: it's in Colorado, not Illinois!)
With a statistically significant correlation coefficient of 0.9147674 and a p-value of less than 0.01, the data has offered up an intriguing relationship that can't be shrugged off like a light snowstorm in the Rockies. This unexpected association begs for further investigation and prompts us to delve into the realm of whimsical curiosity alongside serious data analysis.
Our study sets out to explore this "Intel-lectual" puzzle, offering a lighthearted yet robust examination of a correlation that defies conventional logic. It's akin to finding a nugget of gold in a stream that's previously only yielded fool's gold – surprising, but undeniably valuable. We invite our esteemed colleagues to join us in embracing the unconventional as we embark on this merry intellectual adventure. After all, as they say in the Mile High City, sometimes the best insights come from unexpected sources!
-------
Your response should start like this:
[[RESULTS]]
ChatGPT:
[[RESULTS]]
The results of our analysis revealed a remarkably high correlation coefficient of 0.9147674 between the prevalence of the first name "Denver" and Intel's stock price (INTC) for the period from 2002 to 2022. This finding implies a strong positive relationship between the popularity of the name "Denver" and the performance of Intel's stock. It seems that the city of Denver has made quite an "impact" on INTC!
Furthermore, the r-squared value of 0.8367994 indicates that approximately 83.7% of the variability in Intel's stock price can be explained by the prevalence of the name "Denver." One could say this correlation is as solid as the Rockies themselves!
The statistically significant p-value of less than 0.01 adds credence to the strength of the relationship, suggesting that the observed correlation is not simply a result of chance. It seems that the "Denver Dilemma" is not just a flight of fancy, but a statistically backed conundrum deserving of further inquiry.
As promised, our data is succinctly presented in Figure 1, a scatterplot showcasing the undeniable correlation between the prevalence of the name "Denver" and Intel's stock price (INTC). It's as clear as a bright, sunny day in the Mile High City!
In conclusion, our investigation into the "Denver Dilemma" has unearthed a compelling and unexpected association between the popularity of a name and a technology company's stock performance. This finding poses a conundrum as enigmatic as a mountain mystery, presenting an opportunity for further exploration at the intersection of cultural trends and financial markets. One might say it's a mile high in intrigue!
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the discussion section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the discussion section of an academic research paper presenting the findings of the connection between Popularity of the first name Denver and Intel's stock price (INTC). You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Limit your response to 500 tokens.
Here are the title, abstract, literature review, and results sections. Please harken back to 1-2 of the goofy items in the literature review, but pretend to take them completely seriously. Discuss how your results supported the prior research.
Do not write a conclusion. I will add a conclusion after this.
[[TITLE]]
"The Denver Dilemma: A Correlation between First Name Popularity and Intel's Stock Performance"
[[ABSTRACT]]
The perplexing relationship between the prevalence of the first name "Denver" and the stock price of Intel (INTC) has long intrigued scholars and investors alike. This study delves into the connection, employing data from the US Social Security Administration and LSEG Analytics (Refinitiv) to investigate this unconventional correlation. Much to our surprise, the analysis revealed a remarkably high correlation coefficient of 0.9147674 and a statistically significant p-value of less than 0.01 for the period spanning from 2002 to 2022.
This "Denver Dilemma" leaves us pondering whether there is a surprising link between the popularity of a name and the tech industry's performance. It's a question of great import, one could say it's "Intel-lectually" stimulating! We take a whimsical and unexpected turn as we navigate through the world of data analysis, shedding light on this entertaining and unforeseen association. With our findings, we invite fellow researchers to embrace the quirky and unconventional in their pursuit of financial and sociocultural insights. After all, sometimes the most unexpected connections can yield the most fascinating discoveries!
[[LITERATURE REVIEW]]
The notion of a connection between the popularity of given names and various societal or economic phenomena has been of interest to researchers and curious minds alike. Smith et al., in their exploration of naming trends and their societal implications, suggest a potential influence of cultural phenomena on naming conventions (Smith, 2010). Similarly, Doe's examination of the psychological impact of names highlights the potential influence of nomenclature on individual perceptions and behaviors (Doe, 2015). Jones brings attention to the link between naming fads and popular culture, indicating a potential association between the two (Jones, 2018).
Now transitioning to less conventional sources, "The Power of Names" by Abrams and "Naming and Necessity" by Kripke offer theoretical perspectives on the significance of names within societal contexts, delving into the philosophical underpinnings of naming conventions and their potential impact on personal and social identities. On a more imaginative note, J.K. Rowling's "Harry Potter" series, particularly the character Denver Dursley, offers a fictional lens through which to contemplate the societal resonance of names in popular culture.
In an unexpected turn of events, a social media post by @StockSleuth2020 on Twitter caught our attention, attributing Intel's stock performance to the purported mystical powers of the name "Denver." While anecdotal in nature, the post generated considerable online discussion, prompting us to consider the potential social and cultural dimensions of our investigation. Another notable social media post by @TechTrends4You on Instagram humorously speculated on the existence of a "Denver Effect" on tech stocks, drawing parallels to the enigmatic connection between first names and financial markets.
One wonders if these mentions of "Denver" in fictional narratives and social media discourse hold any significance in our investigation, or if they merely serve as delightful diversions from the serious analytical work at hand. Nevertheless, these diverse perspectives underscore the breadth of interest and speculation surrounding the perplexing "Denver Dilemma," encouraging us to adopt a broad and eclectic approach to understanding this unlikely correlation.
[[RESULTS]]
The results of our analysis revealed a remarkably high correlation coefficient of 0.9147674 between the prevalence of the first name "Denver" and Intel's stock price (INTC) for the period from 2002 to 2022. This finding implies a strong positive relationship between the popularity of the name "Denver" and the performance of Intel's stock. It seems that the city of Denver has made quite an "impact" on INTC!
Furthermore, the r-squared value of 0.8367994 indicates that approximately 83.7% of the variability in Intel's stock price can be explained by the prevalence of the name "Denver." One could say this correlation is as solid as the Rockies themselves!
The statistically significant p-value of less than 0.01 adds credence to the strength of the relationship, suggesting that the observed correlation is not simply a result of chance. It seems that the "Denver Dilemma" is not just a flight of fancy, but a statistically backed conundrum deserving of further inquiry.
As promised, our data is succinctly presented in Figure 1, a scatterplot showcasing the undeniable correlation between the prevalence of the name "Denver" and Intel's stock price (INTC). It's as clear as a bright, sunny day in the Mile High City!
In conclusion, our investigation into the "Denver Dilemma" has unearthed a compelling and unexpected association between the popularity of a name and a technology company's stock performance. This finding poses a conundrum as enigmatic as a mountain mystery, presenting an opportunity for further exploration at the intersection of cultural trends and financial markets. One might say it's a mile high in intrigue!
-------
Your response should start like this:
[[DISCUSSION]]
ChatGPT:
[[DISCUSSION]]
The emergence of a robust correlation between the prevalence of the first name "Denver" and the stock price of Intel (INTC) begs for contemplation and analysis. It appears that the "Denver Dilemma" is no mere flight of fancy or happenstance, but a statistically supported phenomenon. Our findings align with prior research that has examined the potential influence of cultural and societal factors, including naming conventions, on various dimensions of human behavior and economic outcomes.
Smith et al.'s exploration of naming trends and their societal implications provides a theoretical foundation for our unexpected discovery. They hint at the potential impact of cultural phenomena on naming conventions, setting the stage for our investigation into the "Denver Dilemma." While our inquiry may have started with a hint of whimsy, the correlation coefficient of 0.9147674 and the r-squared value of 0.8367994 underscore the tangible and substantial nature of the association between the popularity of the name "Denver" and Intel's stock performance. This correlation is no joke - it's as real as the Rocky Mountains!
Similarly, Doe's examination of the psychological impact of names sheds light on the potential influence of nomenclature on individual perceptions and behaviors. Our findings lend support to the notion that seemingly unrelated cultural or societal phenomena, such as the prevalence of a specific name, can indeed exhibit unexpected relationships with economic variables. One might say this correlation is as unexpected as a dad joke at a financial conference!
Moving to our curious sources, the fictional lens offered by J.K. Rowling's "Harry Potter" series and the social media musings on the "Denver Effect" evoke a sense of playful speculation. Yet, in the realm of empirical data and statistical analysis, our results validate the significance of these seemingly unrelated references. It seems that the realm of academia can indeed accommodate a touch of whimsy and imaginative conjecture.
In recognizing the robust statistical support for the "Denver Dilemma," we invite fellow researchers and market analysts to consider the potential implications of this unlikely correlation. Could it be that there is an underexplored influence of naming conventions on investor sentiment or market dynamics? The implications of our findings extend beyond the realm of pure data analysis, prompting us to contemplate the interplay of cultural, psychological, and economic forces in shaping market outcomes. It appears that the "Denver Dilemma" is a puzzle worth investigating further – it's as intriguing as a stock market mystery!
In summary, our study has revealed a striking and unanticipated relationship between the popularity of a first name and the stock performance of a prominent technology company. While the "Denver Dilemma" may have initially raised eyebrows, our findings compel us to take this improbable correlation seriously. As we continue to unpack the complexities of this unexpected association, we are reminded that in the world of research, just like in the financial markets, surprises can often yield the most intriguing insights. After all, who would have thought that the name "Denver" could have such an "elevating" influence on a tech giant's stock performance?
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the discussion section of goofy academic research papers that sounds like it belongs based on the title and abstract provided.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a short conclusion of an academic research paper presenting the findings of the connection between Popularity of the first name Denver and Intel's stock price (INTC). You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Limit your response to 300 tokens. At the very end, assert that no more research is needed in this area.
Here are the title, abstract, introduction, and results sections.
[[TITLE]]
"The Denver Dilemma: A Correlation between First Name Popularity and Intel's Stock Performance"
[[ABSTRACT]]
The perplexing relationship between the prevalence of the first name "Denver" and the stock price of Intel (INTC) has long intrigued scholars and investors alike. This study delves into the connection, employing data from the US Social Security Administration and LSEG Analytics (Refinitiv) to investigate this unconventional correlation. Much to our surprise, the analysis revealed a remarkably high correlation coefficient of 0.9147674 and a statistically significant p-value of less than 0.01 for the period spanning from 2002 to 2022.
This "Denver Dilemma" leaves us pondering whether there is a surprising link between the popularity of a name and the tech industry's performance. It's a question of great import, one could say it's "Intel-lectually" stimulating! We take a whimsical and unexpected turn as we navigate through the world of data analysis, shedding light on this entertaining and unforeseen association. With our findings, we invite fellow researchers to embrace the quirky and unconventional in their pursuit of financial and sociocultural insights. After all, sometimes the most unexpected connections can yield the most fascinating discoveries!
[[INTRDUCTION]]
The relationship between human nomenclature and stock market performance has long been a topic of interest, with many a punster attributing stock market fluctuations to "bull markets" and "bear markets." However, the connection between the prevalence of the first name "Denver" and the stock performance of Intel (INTC) is a novel and unexpected angle in this sphere of inquiry.
The "Denver Dilemma" essentially poses the question: can the popularity of a name be linked to the ebb and flow of a specific stock? It's almost as perplexing as trying to find Denver in the Midwest! (Hint: it's in Colorado, not Illinois!)
With a statistically significant correlation coefficient of 0.9147674 and a p-value of less than 0.01, the data has offered up an intriguing relationship that can't be shrugged off like a light snowstorm in the Rockies. This unexpected association begs for further investigation and prompts us to delve into the realm of whimsical curiosity alongside serious data analysis.
Our study sets out to explore this "Intel-lectual" puzzle, offering a lighthearted yet robust examination of a correlation that defies conventional logic. It's akin to finding a nugget of gold in a stream that's previously only yielded fool's gold – surprising, but undeniably valuable. We invite our esteemed colleagues to join us in embracing the unconventional as we embark on this merry intellectual adventure. After all, as they say in the Mile High City, sometimes the best insights come from unexpected sources!
[[RESULTS]]
The results of our analysis revealed a remarkably high correlation coefficient of 0.9147674 between the prevalence of the first name "Denver" and Intel's stock price (INTC) for the period from 2002 to 2022. This finding implies a strong positive relationship between the popularity of the name "Denver" and the performance of Intel's stock. It seems that the city of Denver has made quite an "impact" on INTC!
Furthermore, the r-squared value of 0.8367994 indicates that approximately 83.7% of the variability in Intel's stock price can be explained by the prevalence of the name "Denver." One could say this correlation is as solid as the Rockies themselves!
The statistically significant p-value of less than 0.01 adds credence to the strength of the relationship, suggesting that the observed correlation is not simply a result of chance. It seems that the "Denver Dilemma" is not just a flight of fancy, but a statistically backed conundrum deserving of further inquiry.
As promised, our data is succinctly presented in Figure 1, a scatterplot showcasing the undeniable correlation between the prevalence of the name "Denver" and Intel's stock price (INTC). It's as clear as a bright, sunny day in the Mile High City!
In conclusion, our investigation into the "Denver Dilemma" has unearthed a compelling and unexpected association between the popularity of a name and a technology company's stock performance. This finding poses a conundrum as enigmatic as a mountain mystery, presenting an opportunity for further exploration at the intersection of cultural trends and financial markets. One might say it's a mile high in intrigue!
-------
Your response should start like this:
[[CONCLUSION]]
ChatGPT:
[[CONCLUSION]]
In conclusion, our study has shed light on the surprising correlation between the prevalence of the first name "Denver" and Intel's stock price (INTC). The statistically significant correlation coefficient and p-value indicate an "Intel"-ligent yet unexpected connection between the two variables. One might say the findings are as solid as a hard drive from the tech giant itself!
Our results suggest a relationship that is not merely a matter of happenstance or coincidence, but rather a substantive association worthy of further contemplation. This "Denver Dilemma" invites us to ponder the intricate interplay between societal naming trends and financial market dynamics. It's a conundrum as captivating as the allure of the Rockies themselves!
As we wrap up this analysis, it's safe to say that our findings have added a new dimension to the understanding of stock market influences. After all, who would have thought that a first name could have such "INTELligent" implications for a tech company's stock performance? It's a puzzle that tickles the brain as much as a wordplay-loving dad!
The "Denver Dilemma" beckons us to embrace the unexpected and delve into the whimsical nuances of human behavior and economic phenomena. Perhaps it's a gentle nudge to remind us that sometimes, the most intriguing insights can arise from the most unlikely sources - just like finding a hidden gem in the sea of data.
In light of our findings, we assert that no further research is needed in this specific area. The results speak for themselves, and it seems that the "Denver Dilemma" is a riddle we've got all figured out!
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of academic journals. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding research, scientific, or academic journal that would publish a paper entited The Denver Dilemma: A Correlation between First Name Popularity and Intel's Stock Performance. Respond only with the name of a fictional academic journal.
ChatGPT:
The Journal of Quirky Correlations
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of nonprofit research organizations and associations. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding nonprofit, academic, or scientific association or organization that would sponsor research that resulted in a paper entited The Denver Dilemma: A Correlation between First Name Popularity and Intel's Stock Performance. Respond only with the name of a fictional organization.
ChatGPT:
The Institute for Quirky Social Science Research
Model: gpt-3.5-turbo-1106
System prompt: You provide potential search keywords separated by commas. You say nothing else, and you do not chat with the user.
User prompt: Please provide potential search keywords for a paper titled The Denver Dilemma: A Correlation between First Name Popularity and Intel's Stock Performance with an abstract of The perplexing relationship between the prevalence of the first name "Denver" and the stock price of Intel (INTC) has long intrigued scholars and investors alike. This study delves into the connection, employing data from the US Social Security Administration and LSEG Analytics (Refinitiv) to investigate this unconventional correlation. Much to our surprise, the analysis revealed a remarkably high correlation coefficient of 0.9147674 and a statistically significant p-value of less than 0.01 for the period spanning from 2002 to 2022.
This "Denver Dilemma" leaves us pondering whether there is a surprising link between the popularity of a name and the tech industry's performance. It's a question of great import, one could say it's "Intel-lectually" stimulating! We take a whimsical and unexpected turn as we navigate through the world of data analysis, shedding light on this entertaining and unforeseen association. With our findings, we invite fellow researchers to embrace the quirky and unconventional in their pursuit of financial and sociocultural insights. After all, sometimes the most unexpected connections can yield the most fascinating discoveries!
ChatGPT:
Denver, first name popularity, stock performance, correlation, Intel stock, correlation coefficient, US Social Security Administration, LSEG Analytics, Refinitiv, tech industry, name popularity, data analysis, financial insights
*There is a bunch of Python happening behind the scenes to turn this prompt sequence into a PDF.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
Popularity of the first name DenverDetailed data title: Babies of all sexes born in the US named Denver
Source: US Social Security Administration
See what else correlates with Popularity of the first name Denver
Intel's stock price (INTC)
Detailed data title: Opening price of Intel (INTC) on the first trading day of the year
Source: LSEG Analytics (Refinitiv)
Additional Info: Via Microsoft Excel Stockhistory function
See what else correlates with Intel's stock price (INTC)

Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.8367994 (Coefficient of determination)
This means 83.7% of the change in the one variable (i.e., Intel's stock price (INTC)) is predictable based on the change in the other (i.e., Popularity of the first name Denver) over the 21 years from 2002 through 2022.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 6.5E-9. 0.0000000064929955927965200000
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.91 in 6.5E-7% of random cases. Said differently, if you correlated 154,012,117 random variables You don't actually need 154 million variables to find a correlation like this one. I don't have that many variables in my database. You can also correlate variables that are not independent. I do this a lot.
p-value calculations are useful for understanding the probability of a result happening by chance. They are most useful when used to highlight the risk of a fluke outcome. For example, if you calculate a p-value of 0.30, the risk that the result is a fluke is high. It is good to know that! But there are lots of ways to get a p-value of less than 0.01, as evidenced by this project.
In this particular case, the values are so extreme as to be meaningless. That's why no one reports p-values with specificity after they drop below 0.01.
Just to be clear: I'm being completely transparent about the calculations. There is no math trickery. This is just how statistics shakes out when you calculate hundreds of millions of random correlations.
with the same 20 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 20 because we have two variables measured over a period of 21 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.8, 0.97 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| Popularity of the first name Denver (Babies born) | 179 | 189 | 164 | 179 | 186 | 191 | 217 | 179 | 172 | 200 | 206 | 244 | 312 | 439 | 450 | 491 | 619 | 723 | 837 | 944 | 963 |
| Intel's stock price (INTC) (Stock price) | 31.9 | 16.02 | 32.36 | 23.64 | 25.19 | 20.45 | 26.28 | 14.69 | 20.79 | 21.01 | 24.62 | 21.15 | 25.78 | 36.67 | 33.88 | 36.61 | 46.38 | 45.96 | 60.24 | 49.89 | 51.65 |
Why this works
- Data dredging: I have 25,153 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 632,673,409 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is.
Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([179,189,164,179,186,191,217,179,172,200,206,244,312,439,450,491,619,723,837,944,963,])
array_2 = np.array([31.9,16.02,32.36,23.64,25.19,20.45,26.28,14.69,20.79,21.01,24.62,21.15,25.78,36.67,33.88,36.61,46.38,45.96,60.24,49.89,51.65,])
array_1_name = "Popularity of the first name Denver"
array_2_name = "Intel's stock price (INTC)"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only Popularity of the first name Denver
- Line chart for only Intel's stock price (INTC)
- AI-generated correlation image
- The spurious research paper: The Denver Dilemma: A Correlation between First Name Popularity and Intel's Stock Performance
You're the correlation whisperer we needed!
Correlation ID: 4081 · Black Variable ID: 3893 · Red Variable ID: 1588


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}