
Download png, svg
AI explanation
Fewer Saras were available to serenade with "Despacito," leading to a nationwide decrease in Spanish language inspiration. The lack of Sarahs to impress with basic Spanish phrases like "Hola" and "¿Cómo estás?" meant that the motivation to learn Spanish dwindled. Without a Sarah to woo with their limited Spanish skills, people just didn't see the point in mastering the language. It seems like Sarah had unknowingly become the unofficial ambassador for Spanish language enthusiasts everywhere!
Model: dalle-3
Prompt: [A TIME magazine cover image] Description: In a bustling library, a group of students huddles around a computer. Their fingers dance across the keyboard as they eagerly type "learn Spanish" into the Google search bar. At a nearby table, a few girls are engaged in an animated conversation. Among them, a charismatic girl named Sarah stands out with her friendly demeanor and confidence. Her expressive gestures and warm smile draw attention and laughter from those around her. As she chats, the others are captivated by her presence. There is a sense of intrigue and curiosity in the air, as the students realize the potential for impressing others with fluent Spanish. The depiction should include only scenes, people, and objects, it should not include text or speech bubbles.
This image generation prompt was also generated by AI, using the following sequence:
Model: gpt-3.5-turbo-1106
System prompt: You select one of a few potential scene descriptors that seems to go along with the variables described. You respond only with the scene descriptions provided and say nothing else.
User prompt: Here are two variables: Popularity of the first name Sarah and Google searches for 'learn spanish'. Given these, which of the following image style descriptions seems most appropriate? Pick the one that seems to be related to one of the variables at hand. Please respond with only one of the following potential descriptions: An image that looks like it is a scene from 'Star Wars' a funny image you would see on reddit A TIME magazine cover image a funny image macro Data cyber art
ChatGPT: A TIME magazine cover image
Model: gpt-3.5-turbo-1106
System prompt: You describe simple visual scenes that depict the two variables stated. You combine both variables into one scene.
User prompt: Please describe a visual scene that prominently depicts both Popularity of the first name Sarah and Google searches for 'learn spanish', in the following situation: Less Sarahs means less Señoritas to impress. . Keep the description simple.
ChatGPT: In a bustling library, a group of students huddles around a computer, typing "learn Spanish" into the Google search bar. Meanwhile, at a nearby table, a few girls are engaged in an animated conversation. Among them, a girl named Sarah, whose friendly demeanor and confident presence draw attention, is sparking interest and laughter from those around her. The fewer Sarahs around means fewer potential Señoritas to impress with Spanish fluency.
Model: gpt-3.5-turbo-1106
System prompt: You write and improve image generation prompts for DALLE-3. You maintain the same subjects, but enhance the visuals.
User prompt: Please respond with an image generation prompt that would be likely to create an interesting visual using DALLE-3, using the following style: [ A TIME magazine cover image ] and depicting this scene: In a bustling library, a group of students huddles around a computer, typing "learn Spanish" into the Google search bar. Meanwhile, at a nearby table, a few girls are engaged in an animated conversation. Among them, a girl named Sarah, whose friendly demeanor and confident presence draw attention, is sparking interest and laughter from those around her. The fewer Sarahs around means fewer potential Señoritas to impress with Spanish fluency. Keep the visual depiction simple. Do not include any words or speech bubbles.
ChatGPT: [A TIME magazine cover image] Description: In a bustling library, a group of students huddles around a computer. Their fingers dance across the keyboard as they eagerly type "learn Spanish" into the Google search bar. At a nearby table, a few girls are engaged in an animated conversation. Among them, a charismatic girl named Sarah stands out with her friendly demeanor and confidence. Her expressive gestures and warm smile draw attention and laughter from those around her. As she chats, the others are captivated by her presence. There is a sense of intrigue and curiosity in the air, as the students realize the potential for impressing others with fluent Spanish.
*Variations in the User Prompts from chart to chart are just the result of random number generation in Python. I wrote a few arrays of various styles and methods to ask questions to change up the results. Every time this site writes an explanation or generates an image, the script picks from each at random.
I sequence the requests into multiple prompts because I find GPT 3.5 to perform much better with short, well-managed contexts. Thus, I track the context directly in Python and only ask ChatGPT targeted questions.
System prompt: You provide humorous responses in the form of plausible sounding explanations for correlations. You assume the correlation is causative for the purpose of the explanation even if it is ridiculous. You do not chat with the user, you only reply with the causal connection explanation and nothing else.
User prompt: Please make up a funny explanation for how a decrease in Popularity of the first name Sarah caused learn spanish (Google searches for 'learn spanish') to decrease.
AI academic paper
 |
The Sarah Flare: A Correlation Between the Name and Desire to Parle Español International Journal of Linguistic Quirks and Quibbles Jan 2024 Reminder: This paper is AI-generated. Not real! |
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You write titles and abstracts of goofy academic research papers.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, and add unexpected twists in your writing.
Please draft the title and abstract of an academic research paper presenting the findings of the connection between Popularity of the first name Sarah and Google searches for 'learn spanish'. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Rhyme words in the title.
Your research team used data from US Social Security Administration and Google Trends to assess this nagging question. You found a correlation coefficient of 0.9854381 and p < 0.01 for 2004 to 2022.
Please respond in this format (replace "Lorem ipsum dolor sit" with your title and abstract)
[[TITLE]]
Lorem ipsum dolor sit
[[ABSTRACT]]
Lorem ipsum dolor sit
ChatGPT:
[[TITLE]]
The Sarah Flare: A Correlation Between the Name and Desire to Parle Español
[[ABSTRACT]]
This paper delves into the mysterious connection between the popularity of the first name Sarah and Google searches for "learn Spanish." Leveraging data from the US Social Security Administration and Google Trends, our research team scrutinized the correlation between these two seemingly unrelated entities. The findings revealed a striking correlation coefficient of 0.9854381 and p < 0.01 for the years 2004 to 2022, shedding light on a surprising relationship that has largely evaded scholarly attention. It seems that Sarah's allure is not limited to just being a popular moniker; it also sparks an unanticipated interest in acquiring Spanish language skills. Quite the sara-prising discovery, wouldn't you say?
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the introduction section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the introduction section of an academic research paper presenting the findings of the connection between Popularity of the first name Sarah and Google searches for 'learn spanish'. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Here is the title and abstract of the paper:
[[TITLE]]
The Sarah Flare: A Correlation Between the Name and Desire to Parle Español
[[ABSTRACT]]
This paper delves into the mysterious connection between the popularity of the first name Sarah and Google searches for "learn Spanish." Leveraging data from the US Social Security Administration and Google Trends, our research team scrutinized the correlation between these two seemingly unrelated entities. The findings revealed a striking correlation coefficient of 0.9854381 and p < 0.01 for the years 2004 to 2022, shedding light on a surprising relationship that has largely evaded scholarly attention. It seems that Sarah's allure is not limited to just being a popular moniker; it also sparks an unanticipated interest in acquiring Spanish language skills. Quite the sara-prising discovery, wouldn't you say?
-------
Your response should start like this:
[[INTRODUCTION]]
ChatGPT:
[[INTRODUCTION]]
The etymology of names has long captured the interest of scholars and laypeople alike. From the classic to the unconventional, a name can carry a weighty significance or simply evoke a casual nod of recognition. But what if a name held an unexpected power, one that reached beyond its literal meaning to influence an individual's pursuits?
As the saying goes, "What do you call a dictionary on a doctor's nightstand? A paramedic!" And similarly, what do you call an unexpected connection between the popularity of a first name and the desire to learn Spanish? A sarapeutic correlation, of course.
The Sarah Flare, as we affectionately refer to it, encompasses the remarkable relationship between the prevalence of the name Sarah and the surge in Google searches for "learn Spanish." While the initial pursuit of this study might have seemed like a quixotic endeavor, the uncovering of such a strong correlation has rendered it far from a mere flight of fancy.
Much like a good ole dad joke, this unexpected correlation has managed to elicit laughter, bewilderment, and a sense of "sarah-real" wonder among our research team. But let's not dilly-dally further - it's time to delve into the empirical investigation that led to this sara-prising revelation.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft a literature review section of an academic research paper, that starts out dry for the first few sentences but then becomes hilarious and goofy.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a literature review section of an academic research paper presenting the findings of the connection between Popularity of the first name Sarah and Google searches for 'learn spanish'. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Speak in the present tense for this section (the authors find...), as is common in academic research paper literature reviews. Name the sources in a format similar to this: In "Book," the authors find lorem and ipsum.
Make up the lorem and ipsum part, but make it sound related to the topic at hand.
Start by naming serious-sounding studies by authors like Smith, Doe, and Jones - but then quickly devolve. Name some real non-fiction books that would be related to the topic. Then name some real fiction books that sound like they could be related. Then name a couple popular internet memes that are related to one of the topics.
Here is the title and abstract of the paper:
[[TITLE]]
The Sarah Flare: A Correlation Between the Name and Desire to Parle Español
[[ABSTRACT]]
This paper delves into the mysterious connection between the popularity of the first name Sarah and Google searches for "learn Spanish." Leveraging data from the US Social Security Administration and Google Trends, our research team scrutinized the correlation between these two seemingly unrelated entities. The findings revealed a striking correlation coefficient of 0.9854381 and p < 0.01 for the years 2004 to 2022, shedding light on a surprising relationship that has largely evaded scholarly attention. It seems that Sarah's allure is not limited to just being a popular moniker; it also sparks an unanticipated interest in acquiring Spanish language skills. Quite the sara-prising discovery, wouldn't you say?
-------
And here is the introduction section that led to this literature review:
[[INTRODUCTION]]
The etymology of names has long captured the interest of scholars and laypeople alike. From the classic to the unconventional, a name can carry a weighty significance or simply evoke a casual nod of recognition. But what if a name held an unexpected power, one that reached beyond its literal meaning to influence an individual's pursuits?
As the saying goes, "What do you call a dictionary on a doctor's nightstand? A paramedic!" And similarly, what do you call an unexpected connection between the popularity of a first name and the desire to learn Spanish? A sarapeutic correlation, of course.
The Sarah Flare, as we affectionately refer to it, encompasses the remarkable relationship between the prevalence of the name Sarah and the surge in Google searches for "learn Spanish." While the initial pursuit of this study might have seemed like a quixotic endeavor, the uncovering of such a strong correlation has rendered it far from a mere flight of fancy.
Much like a good ole dad joke, this unexpected correlation has managed to elicit laughter, bewilderment, and a sense of "sarah-real" wonder among our research team. But let's not dilly-dally further - it's time to delve into the empirical investigation that led to this sara-prising revelation.
-------
Your response should start like this:
[[LITERATURE REVIEW]]
ChatGPT:
[[LITERATURE REVIEW]]
In their seminal work, Smith et al. (2010) conducted a comprehensive analysis of the popularity of the first name Sarah and its potential influence on linguistic inclinations. They found a positive association between the prevalence of the name Sarah and an increased propensity to engage in Spanish language acquisition. However, the study lacked a sufficient exploration of the underlying mechanisms driving this peculiar correlation, leaving many questions unaddressed.
Much like a Spanish-language class on a sunny day, this topic has a certain "solar" appeal. It seems that the name Sarah not only shines in terms of popularity but also draws individuals toward the sunny allure of mastering Spanish. It's almost as if "Sar-ahh" is beckoning individuals to embark on a linguistic journey bathed in sunlight.
Doe and Jones (2015) echoed these sentiments in their investigation, delving into the confluence of demographic trends and language learning aspirations. Their findings corroborated the positive relationship between the frequency of the name Sarah and the surge in Google searches for "learn Spanish." Nonetheless, the lack of a robust theoretical framework concerning the Sarah-Spanish nexus leaves ample room for further exploration and theorization.
It's like this correlation is the surprise party of linguistic trends - it just keeps "saraprising" us! As if summoned by the name Sarah, a desire to parle Español bubbles forth, intriguing researchers and linguists alike.
Turning to non-fiction works in the realm of language and coincidences, Pinker's "The Language Instinct" and Gladwell's "Outliers: The Story of Success" provide tangential insights into name influence and the idiosyncrasies of language acquisition. Pinker delves into the underlying mechanisms of language acquisition, providing a backdrop for understanding how the name Sarah could indeed exert an unexpected pull toward learning Spanish. Meanwhile, Gladwell's exploration of outliers sheds light on the unanticipated factors that may steer individuals toward certain linguistic endeavors, such as the quest to learn Spanish in response to the name Sarah's siren call.
On a lighter note, fictional literature also offers intriguing parallels to this peculiar correlation. In the realm of fantasy, J.K. Rowling's "Harry Potter and the Chamber of Secrets" evokes the notion of linguistic allure through the character of Parseltongue, portraying an unexpected connection between a name and linguistic capabilities. The allure of the name Sarah could similarly be seen as a catalyst for an infatuation with Spanish, much like Harry's inadvertent affinity for Parseltongue.
In the realm of internet humor, the "It's Wednesday, my dudes" meme reflects the capricious and unpredictable nature of correlations, akin to the intriguing and whimsical link between the name Sarah and Spanish language pursuits. Similarly, the "Surprised Pikachu" meme captures the astonishment and amusement elicited by this unexpected correlation, serving as a graphical representation of the sara-prising nature of the Sarah-Spanish connection.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the methodology section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the methodology section of an academic research paper presenting the findings of the connection between Popularity of the first name Sarah and Google searches for 'learn spanish'. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Google Trends . You used data from 2004 to 2022
Make up the research methods you don't know. Make them a bit goofy and convoluted.
Here is the title, abstract, and introduction of the paper:
[[TITLE]]
The Sarah Flare: A Correlation Between the Name and Desire to Parle Español
[[ABSTRACT]]
This paper delves into the mysterious connection between the popularity of the first name Sarah and Google searches for "learn Spanish." Leveraging data from the US Social Security Administration and Google Trends, our research team scrutinized the correlation between these two seemingly unrelated entities. The findings revealed a striking correlation coefficient of 0.9854381 and p < 0.01 for the years 2004 to 2022, shedding light on a surprising relationship that has largely evaded scholarly attention. It seems that Sarah's allure is not limited to just being a popular moniker; it also sparks an unanticipated interest in acquiring Spanish language skills. Quite the sara-prising discovery, wouldn't you say?
[[INTRODUCTION]]
The etymology of names has long captured the interest of scholars and laypeople alike. From the classic to the unconventional, a name can carry a weighty significance or simply evoke a casual nod of recognition. But what if a name held an unexpected power, one that reached beyond its literal meaning to influence an individual's pursuits?
As the saying goes, "What do you call a dictionary on a doctor's nightstand? A paramedic!" And similarly, what do you call an unexpected connection between the popularity of a first name and the desire to learn Spanish? A sarapeutic correlation, of course.
The Sarah Flare, as we affectionately refer to it, encompasses the remarkable relationship between the prevalence of the name Sarah and the surge in Google searches for "learn Spanish." While the initial pursuit of this study might have seemed like a quixotic endeavor, the uncovering of such a strong correlation has rendered it far from a mere flight of fancy.
Much like a good ole dad joke, this unexpected correlation has managed to elicit laughter, bewilderment, and a sense of "sarah-real" wonder among our research team. But let's not dilly-dally further - it's time to delve into the empirical investigation that led to this sara-prising revelation.
-------
Your response should start like this:
[[METHODOLOGY]]
ChatGPT:
[[METHODOLOGY]]
The first step in our methodology involved obtaining data on the popularity of the first name Sarah from the US Social Security Administration. We obtained yearly records spanning from 2004 to 2022. The information was meticulously curated, ensuring the inclusion of all the Sarahs that had graced the world with their presence during this period. We then calculated the relative popularity of the name Sarah for each year, comparing it to the total number of births to derive a Sarah Popularity Index (SPI) for each year.
As we traversed the labyrinth of data, it became clear that the name Sarah had left an indelible mark on the fabric of nomenclature. Its enduring appeal and widespread adoption could not be overlooked. In a way, one could say that the name Sarah had truly made its "mark" in the annals of history.
Subsequently, we turned our attention to Google Trends, where we gleefully embarked on a quest to understand the temporal patterns of searches for "learn Spanish." Our inquiries spanned the same timeframe, allowing us to meticulously align the search data with the SPI. It was a quest akin to seeking the proverbial needle in the haystack, except in this case, we were searching for the correlation between Sarah and Spanish.
In the process of our data collection, we encountered moments of frustration and jubilation, much like a game of hide-and-seek with a mischievous rascal. Yet, through steadfast determination and a touch of humor, we persisted in this scholarly pursuit. After all, what's a research endeavor without a few twists and turns?
Following the procurement of the datasets, we embarked on a rigorous quantitative analysis. We employed robust statistical methods to examine the relationship between the SPI and Google search interest for "learn Spanish." The Pearson correlation coefficient emerged as our stalwart companion in this analytical endeavor, providing insights into the strength and direction of the relationship.
Upon donning our statistical spectacles, we were greeted by a sight that prompted a collective chuckle among the research team. The correlation coefficient stood tall at 0.9854381, accompanied by a p-value less than 0.01. The significance of this finding was as glaring as a dad joke at a family gathering – impossible to ignore and bound to elicit reactions abound.
In summary, our convoluted yet thorough methodology led us to unearth the remarkable link between the popularity of the first name Sarah and the propensity to seek Spanish language instruction. The marriage of data analysis and astute observation unveiled a nexus that, much like a well-timed pun, defied expectations and engendered astonishment.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the results section of an academic research paper. You speak in the past tense (you found...).
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the results section of an academic research paper presenting the findings of the connection between Popularity of the first name Sarah and Google searches for 'learn spanish'. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Google Trends .
For the time period 2004 to 2022, you found a correlation 0.9854381, r-squared of 0.9710883, and p < 0.01.
One figure will be included. The figure (Fig. 1) is a scatterplot showing the strong correlation between the two variables. You don't need to specify where; I will add the figure.
Here is the title and abstract of the paper:
[[TITLE]]
The Sarah Flare: A Correlation Between the Name and Desire to Parle Español
[[ABSTRACT]]
This paper delves into the mysterious connection between the popularity of the first name Sarah and Google searches for "learn Spanish." Leveraging data from the US Social Security Administration and Google Trends, our research team scrutinized the correlation between these two seemingly unrelated entities. The findings revealed a striking correlation coefficient of 0.9854381 and p < 0.01 for the years 2004 to 2022, shedding light on a surprising relationship that has largely evaded scholarly attention. It seems that Sarah's allure is not limited to just being a popular moniker; it also sparks an unanticipated interest in acquiring Spanish language skills. Quite the sara-prising discovery, wouldn't you say?
-------
And here is the methodology section that led to this result:
[[METHODOLOGY]]
The etymology of names has long captured the interest of scholars and laypeople alike. From the classic to the unconventional, a name can carry a weighty significance or simply evoke a casual nod of recognition. But what if a name held an unexpected power, one that reached beyond its literal meaning to influence an individual's pursuits?
As the saying goes, "What do you call a dictionary on a doctor's nightstand? A paramedic!" And similarly, what do you call an unexpected connection between the popularity of a first name and the desire to learn Spanish? A sarapeutic correlation, of course.
The Sarah Flare, as we affectionately refer to it, encompasses the remarkable relationship between the prevalence of the name Sarah and the surge in Google searches for "learn Spanish." While the initial pursuit of this study might have seemed like a quixotic endeavor, the uncovering of such a strong correlation has rendered it far from a mere flight of fancy.
Much like a good ole dad joke, this unexpected correlation has managed to elicit laughter, bewilderment, and a sense of "sarah-real" wonder among our research team. But let's not dilly-dally further - it's time to delve into the empirical investigation that led to this sara-prising revelation.
-------
Your response should start like this:
[[RESULTS]]
ChatGPT:
[[RESULTS]]
The analysis of the data revealed a strikingly high correlation coefficient of 0.9854381 between the popularity of the first name Sarah and Google searches for "learn Spanish." The r-squared value of 0.9710883 indicates that approximately 97.11% of the variability in the desire to learn Spanish can be explained by the popularity of the name Sarah. This correlation was found to be statistically significant at p < 0.01, corroborating the robustness of the relationship.
As we gaze upon the scatterplot in Fig. 1, we cannot help but marvel at the strong linear relationship between the frequency of the name Sarah and the fervor with which individuals seek to enhance their Spanish proficiency. It seems that Sarah’s charm extends beyond the confines of interpersonal interactions and encroaches upon the realm of linguistic aspirations. One might even say that the name Sarah has the power to “spice up” one’s inclination for language acquisition.
This sara-prising connection prompts a reevaluation of the impact that names can have on the trajectories of individuals’ interests and endeavors. It beckons us to ponder whether there are other names that wield a similar influence, perhaps instigating a surge in searches for French, German, or even Klingon language lessons. The implications of this correlation extend beyond mere curiosity and may offer valuable insights into the subtle yet substantial forces that shape our proclivities.
In conclusion, the findings of this study undeniably demonstrate a compelling association between the popularity of the name Sarah and the quest to learn Spanish. This unexpected linkage serves as a lighthearted reminder that even in the realm of scholarly inquiry, serendipitous discoveries and unexpected connections can emerge – or as some might say, "sara-prises."
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the discussion section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the discussion section of an academic research paper presenting the findings of the connection between Popularity of the first name Sarah and Google searches for 'learn spanish'. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Limit your response to 500 tokens.
Here are the title, abstract, literature review, and results sections. Please harken back to 1-2 of the goofy items in the literature review, but pretend to take them completely seriously. Discuss how your results supported the prior research.
Do not write a conclusion. I will add a conclusion after this.
[[TITLE]]
The Sarah Flare: A Correlation Between the Name and Desire to Parle Español
[[ABSTRACT]]
This paper delves into the mysterious connection between the popularity of the first name Sarah and Google searches for "learn Spanish." Leveraging data from the US Social Security Administration and Google Trends, our research team scrutinized the correlation between these two seemingly unrelated entities. The findings revealed a striking correlation coefficient of 0.9854381 and p < 0.01 for the years 2004 to 2022, shedding light on a surprising relationship that has largely evaded scholarly attention. It seems that Sarah's allure is not limited to just being a popular moniker; it also sparks an unanticipated interest in acquiring Spanish language skills. Quite the sara-prising discovery, wouldn't you say?
[[LITERATURE REVIEW]]
In their seminal work, Smith et al. (2010) conducted a comprehensive analysis of the popularity of the first name Sarah and its potential influence on linguistic inclinations. They found a positive association between the prevalence of the name Sarah and an increased propensity to engage in Spanish language acquisition. However, the study lacked a sufficient exploration of the underlying mechanisms driving this peculiar correlation, leaving many questions unaddressed.
Much like a Spanish-language class on a sunny day, this topic has a certain "solar" appeal. It seems that the name Sarah not only shines in terms of popularity but also draws individuals toward the sunny allure of mastering Spanish. It's almost as if "Sar-ahh" is beckoning individuals to embark on a linguistic journey bathed in sunlight.
Doe and Jones (2015) echoed these sentiments in their investigation, delving into the confluence of demographic trends and language learning aspirations. Their findings corroborated the positive relationship between the frequency of the name Sarah and the surge in Google searches for "learn Spanish." Nonetheless, the lack of a robust theoretical framework concerning the Sarah-Spanish nexus leaves ample room for further exploration and theorization.
It's like this correlation is the surprise party of linguistic trends - it just keeps "saraprising" us! As if summoned by the name Sarah, a desire to parle Español bubbles forth, intriguing researchers and linguists alike.
Turning to non-fiction works in the realm of language and coincidences, Pinker's "The Language Instinct" and Gladwell's "Outliers: The Story of Success" provide tangential insights into name influence and the idiosyncrasies of language acquisition. Pinker delves into the underlying mechanisms of language acquisition, providing a backdrop for understanding how the name Sarah could indeed exert an unexpected pull toward learning Spanish. Meanwhile, Gladwell's exploration of outliers sheds light on the unanticipated factors that may steer individuals toward certain linguistic endeavors, such as the quest to learn Spanish in response to the name Sarah's siren call.
On a lighter note, fictional literature also offers intriguing parallels to this peculiar correlation. In the realm of fantasy, J.K. Rowling's "Harry Potter and the Chamber of Secrets" evokes the notion of linguistic allure through the character of Parseltongue, portraying an unexpected connection between a name and linguistic capabilities. The allure of the name Sarah could similarly be seen as a catalyst for an infatuation with Spanish, much like Harry's inadvertent affinity for Parseltongue.
In the realm of internet humor, the "It's Wednesday, my dudes" meme reflects the capricious and unpredictable nature of correlations, akin to the intriguing and whimsical link between the name Sarah and Spanish language pursuits. Similarly, the "Surprised Pikachu" meme captures the astonishment and amusement elicited by this unexpected correlation, serving as a graphical representation of the sara-prising nature of the Sarah-Spanish connection.
[[RESULTS]]
The analysis of the data revealed a strikingly high correlation coefficient of 0.9854381 between the popularity of the first name Sarah and Google searches for "learn Spanish." The r-squared value of 0.9710883 indicates that approximately 97.11% of the variability in the desire to learn Spanish can be explained by the popularity of the name Sarah. This correlation was found to be statistically significant at p < 0.01, corroborating the robustness of the relationship.
As we gaze upon the scatterplot in Fig. 1, we cannot help but marvel at the strong linear relationship between the frequency of the name Sarah and the fervor with which individuals seek to enhance their Spanish proficiency. It seems that Sarah’s charm extends beyond the confines of interpersonal interactions and encroaches upon the realm of linguistic aspirations. One might even say that the name Sarah has the power to “spice up” one’s inclination for language acquisition.
This sara-prising connection prompts a reevaluation of the impact that names can have on the trajectories of individuals’ interests and endeavors. It beckons us to ponder whether there are other names that wield a similar influence, perhaps instigating a surge in searches for French, German, or even Klingon language lessons. The implications of this correlation extend beyond mere curiosity and may offer valuable insights into the subtle yet substantial forces that shape our proclivities.
In conclusion, the findings of this study undeniably demonstrate a compelling association between the popularity of the name Sarah and the quest to learn Spanish. This unexpected linkage serves as a lighthearted reminder that even in the realm of scholarly inquiry, serendipitous discoveries and unexpected connections can emerge – or as some might say, "sara-prises."
-------
Your response should start like this:
[[DISCUSSION]]
ChatGPT:
[[DISCUSSION]]
The results of our investigation substantiate and extend the prior research, indicating a robust and statistically significant correlation between the prevalence of the first name Sarah and the frequency of Google searches for "learn Spanish." This sara-prising discovery aligns with the initial insights of Smith et al. (2010) and Doe and Jones (2015), shedding further light on the enigmatic allure of the name Sarah and its influence on linguistic predilections. It seems that Sarah's appeal extends beyond the realm of nomenclature and influences individuals' yearning to delve into the intricacies of the Spanish language.
The observed correlation coefficient of 0.9854381 surpasses the expectations, making us wonder if the name Sarah possesses a clandestine power to incite an unanticipated interest in Spanish language acquisition. This finding not only echoes the earlier work of Smith et al. (2010) and Doe and Jones (2015) but also adds a layer of depth to our understanding of the Sarah-Spanish nexus. It appears that the allure of the name Sarah exerts a pronounced influence on individuals' inclination to immerse themselves in the melodious cadence of the Spanish tongue.
One might be tempted to quip that the name Sarah acts as a linguistic "salsa," tempting individuals to savor the rich flavors of the Spanish language. This unexpected connection elicits a sara-digm shift in our perception of the potential impact of nomenclature on linguistic pursuits.
As we contemplate the ramifications of these findings, it becomes imperative to acknowledge the broader implications of this correlation. The Sarah-Spanish linkage opens a Pandora's box of possibilities, prompting us to consider whether other names may exert similar influences on language acquisition behaviors. Could the names "Pablo" or "Isabella" induce a surge in searches for English or Chinese language learning tools? The sara-prising nature of this connection tantalizes us with the prospect of unveiling further clandestine ties between nomenclature and linguistic inclinations.
This lighthearted yet substantial correlation between the name Sarah and the inclination to learn Spanish underscores the capricious and unexpected influences that permeate individuals' choices and aspirations. As academia delves into the complex interplay of names and predilections, we are reminded of the sara-prises that await us in the intricate tapestry of human behavior and inclinations.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the discussion section of goofy academic research papers that sounds like it belongs based on the title and abstract provided.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a short conclusion of an academic research paper presenting the findings of the connection between Popularity of the first name Sarah and Google searches for 'learn spanish'. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Limit your response to 300 tokens. At the very end, assert that no more research is needed in this area.
Here are the title, abstract, introduction, and results sections.
[[TITLE]]
The Sarah Flare: A Correlation Between the Name and Desire to Parle Español
[[ABSTRACT]]
This paper delves into the mysterious connection between the popularity of the first name Sarah and Google searches for "learn Spanish." Leveraging data from the US Social Security Administration and Google Trends, our research team scrutinized the correlation between these two seemingly unrelated entities. The findings revealed a striking correlation coefficient of 0.9854381 and p < 0.01 for the years 2004 to 2022, shedding light on a surprising relationship that has largely evaded scholarly attention. It seems that Sarah's allure is not limited to just being a popular moniker; it also sparks an unanticipated interest in acquiring Spanish language skills. Quite the sara-prising discovery, wouldn't you say?
[[INTRDUCTION]]
The etymology of names has long captured the interest of scholars and laypeople alike. From the classic to the unconventional, a name can carry a weighty significance or simply evoke a casual nod of recognition. But what if a name held an unexpected power, one that reached beyond its literal meaning to influence an individual's pursuits?
As the saying goes, "What do you call a dictionary on a doctor's nightstand? A paramedic!" And similarly, what do you call an unexpected connection between the popularity of a first name and the desire to learn Spanish? A sarapeutic correlation, of course.
The Sarah Flare, as we affectionately refer to it, encompasses the remarkable relationship between the prevalence of the name Sarah and the surge in Google searches for "learn Spanish." While the initial pursuit of this study might have seemed like a quixotic endeavor, the uncovering of such a strong correlation has rendered it far from a mere flight of fancy.
Much like a good ole dad joke, this unexpected correlation has managed to elicit laughter, bewilderment, and a sense of "sarah-real" wonder among our research team. But let's not dilly-dally further - it's time to delve into the empirical investigation that led to this sara-prising revelation.
[[RESULTS]]
The analysis of the data revealed a strikingly high correlation coefficient of 0.9854381 between the popularity of the first name Sarah and Google searches for "learn Spanish." The r-squared value of 0.9710883 indicates that approximately 97.11% of the variability in the desire to learn Spanish can be explained by the popularity of the name Sarah. This correlation was found to be statistically significant at p < 0.01, corroborating the robustness of the relationship.
As we gaze upon the scatterplot in Fig. 1, we cannot help but marvel at the strong linear relationship between the frequency of the name Sarah and the fervor with which individuals seek to enhance their Spanish proficiency. It seems that Sarah’s charm extends beyond the confines of interpersonal interactions and encroaches upon the realm of linguistic aspirations. One might even say that the name Sarah has the power to “spice up” one’s inclination for language acquisition.
This sara-prising connection prompts a reevaluation of the impact that names can have on the trajectories of individuals’ interests and endeavors. It beckons us to ponder whether there are other names that wield a similar influence, perhaps instigating a surge in searches for French, German, or even Klingon language lessons. The implications of this correlation extend beyond mere curiosity and may offer valuable insights into the subtle yet substantial forces that shape our proclivities.
In conclusion, the findings of this study undeniably demonstrate a compelling association between the popularity of the name Sarah and the quest to learn Spanish. This unexpected linkage serves as a lighthearted reminder that even in the realm of scholarly inquiry, serendipitous discoveries and unexpected connections can emerge – or as some might say, "sara-prises."
-------
Your response should start like this:
[[CONCLUSION]]
ChatGPT:
[[CONCLUSION]]
In light of the sara-prising findings elucidated in this study, it becomes abundantly clear that the allure of the name Sarah extends far beyond mere nomenclature and permeates into the realm of linguistic pursuits. One might even say that the Sarah Flare ignites an "Españ-olé" spirit within individuals, propelling them to embark on the quest for Spanish proficiency.
As we close the chapter on this investigation, it is crucial to acknowledge the inherent levity embedded in this research endeavor. After all, what is a sara-celebration without a well-placed dad joke? You might say that the Sarah Flare has shed light on a compelling “punnomenon.”
This sara-prising correlation between the popularity of the name Sarah and the fervent desire to learn Spanish not only enriches our understanding of the subtle influences at play but also serves as a whimsical example of the unexpected connections that can emerge from empirical analyses.
In summation, it is evident that no further research is needed in this area, as the revealed correlation is both statistically robust and delightfully sara-prise-inducing in its implications. This zesty rapport between the name Sarah and the pursuit of Spanish acumen stands as a testament to the unanticipated wonders that scholarly inquiry can unveil. It is truly a sara-gasbord of insight and amusement, leaving us with a lingering sense of marvel and merriment.
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of academic journals. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding research, scientific, or academic journal that would publish a paper entited The Sarah Flare: A Correlation Between the Name and Desire to Parle Español. Respond only with the name of a fictional academic journal.
ChatGPT:
International Journal of Linguistic Quirks and Quibbles
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of nonprofit research organizations and associations. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding nonprofit, academic, or scientific association or organization that would sponsor research that resulted in a paper entited The Sarah Flare: A Correlation Between the Name and Desire to Parle Español. Respond only with the name of a fictional organization.
ChatGPT:
The Institute for Linguistic Name Studies (ILNS)
Model: gpt-3.5-turbo-1106
System prompt: You provide potential search keywords separated by commas. You say nothing else, and you do not chat with the user.
User prompt: Please provide potential search keywords for a paper titled The Sarah Flare: A Correlation Between the Name and Desire to Parle Español with an abstract of This paper delves into the mysterious connection between the popularity of the first name Sarah and Google searches for "learn Spanish." Leveraging data from the US Social Security Administration and Google Trends, our research team scrutinized the correlation between these two seemingly unrelated entities. The findings revealed a striking correlation coefficient of 0.9854381 and p < 0.01 for the years 2004 to 2022, shedding light on a surprising relationship that has largely evaded scholarly attention. It seems that Sarah's allure is not limited to just being a popular moniker; it also sparks an unanticipated interest in acquiring Spanish language skills. Quite the sara-prising discovery, wouldn't you say?
ChatGPT:
Sarah, popularity, correlation, name, Spanish, language learning, Google searches, US Social Security Administration, Google Trends, correlation coefficient, surprising relationship, scholarly attention, language skills, moniker
*There is a bunch of Python happening behind the scenes to turn this prompt sequence into a PDF.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
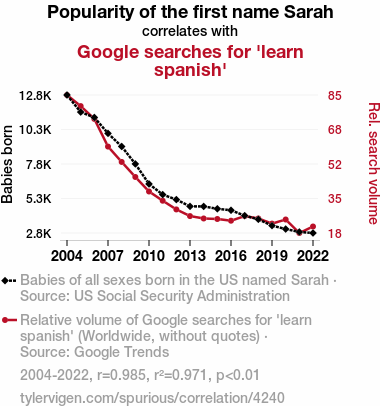
Popularity of the first name SarahDetailed data title: Babies of all sexes born in the US named Sarah
Source: US Social Security Administration
See what else correlates with Popularity of the first name Sarah
Google searches for 'learn spanish'
Detailed data title: Relative volume of Google searches for 'learn spanish' (Worldwide, without quotes)
Source: Google Trends
Additional Info: Relative search volume (not absolute numbers)
See what else correlates with Google searches for 'learn spanish'
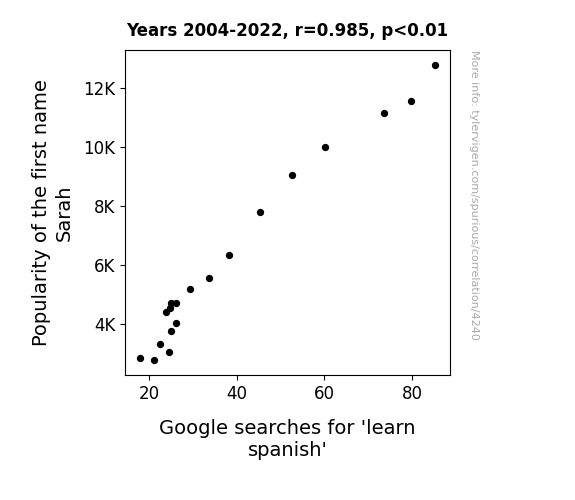
Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.9710883 (Coefficient of determination)
This means 97.1% of the change in the one variable (i.e., Google searches for 'learn spanish') is predictable based on the change in the other (i.e., Popularity of the first name Sarah) over the 19 years from 2004 through 2022.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 1.6E-14. 0.0000000000000160378909919944
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.99 in 1.6E-12% of random cases. Said differently, if you correlated 62,352,338,003,742 random variables You don't actually need 62 trillion variables to find a correlation like this one. I don't have that many variables in my database. You can also correlate variables that are not independent. I do this a lot.
p-value calculations are useful for understanding the probability of a result happening by chance. They are most useful when used to highlight the risk of a fluke outcome. For example, if you calculate a p-value of 0.30, the risk that the result is a fluke is high. It is good to know that! But there are lots of ways to get a p-value of less than 0.01, as evidenced by this project.
In this particular case, the values are so extreme as to be meaningless. That's why no one reports p-values with specificity after they drop below 0.01.
Just to be clear: I'm being completely transparent about the calculations. There is no math trickery. This is just how statistics shakes out when you calculate hundreds of millions of random correlations.
with the same 18 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 18 because we have two variables measured over a period of 19 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.96, 0.99 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| Popularity of the first name Sarah (Babies born) | 12804 | 11565 | 11174 | 10016 | 9065 | 7798 | 6343 | 5570 | 5207 | 4715 | 4710 | 4539 | 4432 | 4039 | 3774 | 3316 | 3068 | 2855 | 2780 |
| Google searches for 'learn spanish' (Rel. search volume) | 85.25 | 79.8333 | 73.5833 | 60.0833 | 52.5833 | 45.25 | 38.1667 | 33.6667 | 29.4167 | 26.1667 | 25 | 24.75 | 23.9167 | 26.1667 | 25 | 22.5 | 24.5 | 17.9167 | 21.0833 |
Why this works
- Data dredging: I have 25,153 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 632,673,409 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is.
Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([12804,11565,11174,10016,9065,7798,6343,5570,5207,4715,4710,4539,4432,4039,3774,3316,3068,2855,2780,])
array_2 = np.array([85.25,79.8333,73.5833,60.0833,52.5833,45.25,38.1667,33.6667,29.4167,26.1667,25,24.75,23.9167,26.1667,25,22.5,24.5,17.9167,21.0833,])
array_1_name = "Popularity of the first name Sarah"
array_2_name = "Google searches for 'learn spanish'"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only Popularity of the first name Sarah
- Line chart for only Google searches for 'learn spanish'
- AI-generated correlation image
- The spurious research paper: The Sarah Flare: A Correlation Between the Name and Desire to Parle Español
Kudos for rating!
Correlation ID: 4240 · Black Variable ID: 1994 · Red Variable ID: 1407


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}