
Download png, svg
AI explanation
Fewer Tiarra's means fewer people insisting on unconventional number naming, leading to a gradual return to linguistic sanity.
Model: dalle-3
Prompt: Create a cubism-style digital image of a group of people gathered around a large fragmented screen, with the news anchor's face multiplied and displayed from different angles on the screen. In the foreground, several fragmented figures of people are arranged in geometric shapes, each symbolizing various emotions like shock, confusion, and interest. The "Tiarra" poster with a downward trend arrow is depicted in fractured forms, merging with abstract patterns. A separate screen showcasing the search volume for "onety one" is represented as a shattered mosaic, with the "Linguistic Oddities" sign fragmented and dispersed throughout the composition. The composition is a complex jigsaw of disjointed geometric elements that symbolize the interconnected decline of Tiarra's popularity and the fading fascination with linguistic oddities. The depiction should include only scenes, people, and objects, it should not include text or speech bubbles.
This image generation prompt was also generated by AI, using the following sequence:
Model: gpt-3.5-turbo-1106
System prompt: You select one of a few potential scene descriptors that seems to go along with the situation described. You respond only with the scene descriptions provided and say nothing else.
User prompt: Here is a situation: "Breaking News: A Decline in Tiarra Popularity Linked to Decrease in 'Onety One' Searches! Experts speculate that as the name Tiarra dwindles in popularity, so too does the interest in linguistic oddities like the pronunciation of the number 11. It appears that the Tiarra trend and 'onety one' inquiry are intertwined in a web of linguistic frivolity! Stay tuned as we delve into the peculiar correlation between baby names and numerical curiosities.". Given that situation, which of the following image descriptions seems most appropriate? Pick the one that seems to be related to one of the variables at hand and the tone of the explanation. Please respond with only one of the following potential descriptions: Realistic Woodblock painting Sci-fi fantacy An image that looks like it is a scene from 'Star Wars' Cubism
ChatGPT: Cubism
Model: gpt-3.5-turbo-1106
System prompt: You describe simple visual scenes that depict the two variables stated and the explanation described. Do not reference graphs or charts; describe physical objects.
User prompt: Please describe a visual scene that depicts the following situation. Keep the description simple. "Breaking News: A Decline in Tiarra Popularity Linked to Decrease in 'Onety One' Searches! Experts speculate that as the name Tiarra dwindles in popularity, so too does the interest in linguistic oddities like the pronunciation of the number 11. It appears that the Tiarra trend and 'onety one' inquiry are intertwined in a web of linguistic frivolity! Stay tuned as we delve into the peculiar correlation between baby names and numerical curiosities."
ChatGPT: In the first scene, we see a group of people gathered around a large screen, with a news anchor reporting the breaking news about Tiarra's declining popularity. In the background, there's a giant "Tiarra" poster with a downward trend arrow. Meanwhile, on a separate screen, the search volume for "onety one" is displayed next to a curious-looking sign that says "Linguistic Oddities." The scene conveys the connection between the decline of Tiarra's popularity and the waning interest in peculiar linguistic phenomena, as the audience watches in fascination and confusion.
Model: gpt-3.5-turbo-1106
System prompt: You write and improve image generation prompts for DALLE-3. You maintain the same subjects, but enhance the visuals.
User prompt: Please respond with an image generation prompt that would be likely to create an interesting visual using DALLE-3, using the following style: [ Cubism ] and depicting this scene: In the first scene, we see a group of people gathered around a large screen, with a news anchor reporting the breaking news about Tiarra's declining popularity. In the background, there's a giant "Tiarra" poster with a downward trend arrow. Meanwhile, on a separate screen, the search volume for "onety one" is displayed next to a curious-looking sign that says "Linguistic Oddities." The scene conveys the connection between the decline of Tiarra's popularity and the waning interest in peculiar linguistic phenomena, as the audience watches in fascination and confusion. Keep the visual depiction simple. Do not include any words or speech bubbles.
ChatGPT: Create a cubism-style digital image of a group of people gathered around a large fragmented screen, with the news anchor's face multiplied and displayed from different angles on the screen. In the foreground, several fragmented figures of people are arranged in geometric shapes, each symbolizing various emotions like shock, confusion, and interest. The "Tiarra" poster with a downward trend arrow is depicted in fractured forms, merging with abstract patterns. A separate screen showcasing the search volume for "onety one" is represented as a shattered mosaic, with the "Linguistic Oddities" sign fragmented and dispersed throughout the composition. The composition is a complex jigsaw of disjointed geometric elements that symbolize the interconnected decline of Tiarra's popularity and the fading fascination with linguistic oddities.
*Variations in the User Prompts from chart to chart are just the result of random number generation in Python. I wrote a few arrays of various styles and methods to ask questions to change up the results. Every time this site writes an explanation or generates an image, the script picks from each at random.
I sequence the requests into multiple prompts because I find GPT 3.5 to perform much better with short, well-managed contexts. Thus, I track the context directly in Python and only ask ChatGPT targeted questions.
System prompt: You provide humorous responses in the form of plausible sounding explanations for correlations. You assume the correlation is causative for the purpose of the explanation even if it is ridiculous. You do not chat with the user, you only reply with the causal connection explanation and nothing else.
User prompt: Please make up a funny explanation for how a decrease in Popularity of the first name Tiarra caused why isnt 11 pronounced onety one (Google searches for 'why isnt 11 pronounced onety one') to decrease.
AI academic paper
 |
The Tiarra Trend and Tedious Terminology: A Tantalizing Tale of Taming 'Onety One' The Journal of Linguistic Laughter Jan 2024 Reminder: This paper is AI-generated. Not real! |
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You write titles and abstracts of goofy academic research papers.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, and add unexpected twists in your writing.
Please draft the title and abstract of an academic research paper presenting the findings of the connection between Popularity of the first name Tiarra and Google searches for 'why isnt 11 pronounced onety one'. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Make the title an alliteration.
Your research team used data from US Social Security Administration and Google Trends to assess this nagging question. You found a correlation coefficient of 0.8164011 and p < 0.01 for 2004 to 2021.
Please respond in this format (replace "Lorem ipsum dolor sit" with your title and abstract)
[[TITLE]]
Lorem ipsum dolor sit
[[ABSTRACT]]
Lorem ipsum dolor sit
ChatGPT:
[[TITLE]]
The Tiarra Trend and Tedious Terminology: A Tantalizing Tale of Taming 'Onety One'
[[ABSTRACT]]
The popularity of first names has long been a subject of fascination and speculation. This paper explores the correlation between the frequency of the first name "Tiarra" and the frequency of Google searches for the puzzling inquiry "why isn't 11 pronounced onety one." Leveraging data from the US Social Security Administration and Google Trends, a robust correlation coefficient of 0.8164011 and a statistically significant p-value of less than 0.01 were observed for the period spanning 2004 to 2021. Our findings offer a whimsical yet intriguing insight into the peculiar whims of human curiosity and linguistic quirkiness. While the link between the name "Tiarra" and the enigmatic query about the number 11 may seem whimsical at first glance, it adds a lighthearted touch to the otherwise serious field of name popularity research. This study paves the way for future investigations into the interplay of nomenclature and linguistic oddities, providing a refreshing reprieve from the typical scholarly discourse.
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft the introduction section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the introduction section of an academic research paper presenting the findings of the connection between Popularity of the first name Tiarra and Google searches for 'why isnt 11 pronounced onety one'. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Here is the title and abstract of the paper:
[[TITLE]]
The Tiarra Trend and Tedious Terminology: A Tantalizing Tale of Taming 'Onety One'
[[ABSTRACT]]
The popularity of first names has long been a subject of fascination and speculation. This paper explores the correlation between the frequency of the first name "Tiarra" and the frequency of Google searches for the puzzling inquiry "why isn't 11 pronounced onety one." Leveraging data from the US Social Security Administration and Google Trends, a robust correlation coefficient of 0.8164011 and a statistically significant p-value of less than 0.01 were observed for the period spanning 2004 to 2021. Our findings offer a whimsical yet intriguing insight into the peculiar whims of human curiosity and linguistic quirkiness. While the link between the name "Tiarra" and the enigmatic query about the number 11 may seem whimsical at first glance, it adds a lighthearted touch to the otherwise serious field of name popularity research. This study paves the way for future investigations into the interplay of nomenclature and linguistic oddities, providing a refreshing reprieve from the typical scholarly discourse.
-------
Your response should start like this:
[[INTRODUCTION]]
ChatGPT:
Ah, the fascinating world of nomenclature and linguistic oddities. It's a realm where the inscrutable mysteries of human behavior and language come together to create a delightful playground for researchers. In this paper, we delve into the intriguing correlation between the popularity of the first name "Tiarra" and an inexplicable query that has puzzled minds across the digital landscape: "why isn't 11 pronounced onety one." Yes, you read that right. We're embarking on a journey to tame the enigmatic beast of 'onety one', armed with the peculiar trend of the name "Tiarra" as our guide.
The idea that the frequency of a particular name could be linked to a quirky linguistic query seems almost too whimsical to take seriously. However, in the world of statistical analysis and research, we mustn't be too quick to dismiss seemingly lighthearted connections. As the old saying goes, "correlation does not imply causation, but it sure does waggle its eyebrows suggestively and gesture furtively." Or was it something about correlation and causation being like a well-mixed cocktail of science and speculation? Well, you get the idea.
At the heart of this study lies the quest to uncover the hidden patterns and unanticipated relationships that populate the complex landscape of human behavior and linguistic quirks. We ventured into the realm of the US Social Security Administration's treasure trove of first name data and the labyrinthine archives of Google Trends to excavate insights that oscillate between the baffling and the beguiling. It's a tale of tantalizing trends and titillating terminology, all set against the backdrop of statistical analyses that would make even the most numbers-averse quiver with excitement. After all, who wouldn't be riveted by the remarkable correlation coefficient of 0.8164011 and the statistically significant p-value of less than 0.01 that emerged from our intrepid expedition into the wilds of data?
As we embark on this expedition, let us pause to appreciate the unconventional terrain that lies before us. The Tiarra trend and the perplexing case of onety one may just be the tip of the iceberg in the grand odyssey of name popularity research. With a dash of whimsy and a sprinkle of statistical rigor, we aim to shed light on this unconventional convergence of human curiosity and linguistic conundrums, all while introducing a refreshing reprieve from the staid conventions of scholarly discourse. Join us as we navigate this peculiar intersection of data, language, and the quirks of human curiosity, and remember: even in the world of academic research, a touch of lightheartedness can go a long way.
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft a literature review section of an academic research paper, that starts out dry for the first few sentences but then becomes hilarious and goofy.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a literature review section of an academic research paper presenting the findings of the connection between Popularity of the first name Tiarra and Google searches for 'why isnt 11 pronounced onety one'. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Speak in the present tense for this section (the authors find...), as is common in academic research paper literature reviews. Name the sources in a format similar to this: In "Book," the authors find lorem and ipsum.
Make up the lorem and ipsum part, but make it sound related to the topic at hand.
Start by naming serious-sounding studies by authors like Smith, Doe, and Jones - but then quickly devolve. Name some real non-fiction books that would be related to the topic. Then name some real fiction books that sound like they could be related. Then name some cartoons and childrens' shows that you watched that are related to the topic.
Here is the title and abstract of the paper:
[[TITLE]]
The Tiarra Trend and Tedious Terminology: A Tantalizing Tale of Taming 'Onety One'
[[ABSTRACT]]
The popularity of first names has long been a subject of fascination and speculation. This paper explores the correlation between the frequency of the first name "Tiarra" and the frequency of Google searches for the puzzling inquiry "why isn't 11 pronounced onety one." Leveraging data from the US Social Security Administration and Google Trends, a robust correlation coefficient of 0.8164011 and a statistically significant p-value of less than 0.01 were observed for the period spanning 2004 to 2021. Our findings offer a whimsical yet intriguing insight into the peculiar whims of human curiosity and linguistic quirkiness. While the link between the name "Tiarra" and the enigmatic query about the number 11 may seem whimsical at first glance, it adds a lighthearted touch to the otherwise serious field of name popularity research. This study paves the way for future investigations into the interplay of nomenclature and linguistic oddities, providing a refreshing reprieve from the typical scholarly discourse.
-------
And here is the introduction section that led to this literature review:
[[INTRODUCTION]]
Ah, the fascinating world of nomenclature and linguistic oddities. It's a realm where the inscrutable mysteries of human behavior and language come together to create a delightful playground for researchers. In this paper, we delve into the intriguing correlation between the popularity of the first name "Tiarra" and an inexplicable query that has puzzled minds across the digital landscape: "why isn't 11 pronounced onety one." Yes, you read that right. We're embarking on a journey to tame the enigmatic beast of 'onety one', armed with the peculiar trend of the name "Tiarra" as our guide.
The idea that the frequency of a particular name could be linked to a quirky linguistic query seems almost too whimsical to take seriously. However, in the world of statistical analysis and research, we mustn't be too quick to dismiss seemingly lighthearted connections. As the old saying goes, "correlation does not imply causation, but it sure does waggle its eyebrows suggestively and gesture furtively." Or was it something about correlation and causation being like a well-mixed cocktail of science and speculation? Well, you get the idea.
At the heart of this study lies the quest to uncover the hidden patterns and unanticipated relationships that populate the complex landscape of human behavior and linguistic quirks. We ventured into the realm of the US Social Security Administration's treasure trove of first name data and the labyrinthine archives of Google Trends to excavate insights that oscillate between the baffling and the beguiling. It's a tale of tantalizing trends and titillating terminology, all set against the backdrop of statistical analyses that would make even the most numbers-averse quiver with excitement. After all, who wouldn't be riveted by the remarkable correlation coefficient of 0.8164011 and the statistically significant p-value of less than 0.01 that emerged from our intrepid expedition into the wilds of data?
As we embark on this expedition, let us pause to appreciate the unconventional terrain that lies before us. The Tiarra trend and the perplexing case of onety one may just be the tip of the iceberg in the grand odyssey of name popularity research. With a dash of whimsy and a sprinkle of statistical rigor, we aim to shed light on this unconventional convergence of human curiosity and linguistic conundrums, all while introducing a refreshing reprieve from the staid conventions of scholarly discourse. Join us as we navigate this peculiar intersection of data, language, and the quirks of human curiosity, and remember: even in the world of academic research, a touch of lightheartedness can go a long way.
-------
Your response should start like this:
[[LITERATURE REVIEW]]
ChatGPT:
[[LITERATURE REVIEW]]
The investigation into the correlation between the popularity of the first name "Tiarra" and Google searches for the perplexing phrase "why isn't 11 pronounced onety one" leads us to a curious amalgamation of studies and sources. Smith et al. (2015) examined the peculiar dynamics of first name trends and their potential connection to linguistic anomalies, laying the groundwork for our whimsical exploration. Doe and Jones (2018) ventured into the realm of internet search queries and their enigmatic allure, setting the stage for our foray into the perplexing world of 'onety one.'
Turning to non-fiction literature, "Freakonomics" by Steven D. Levitt and Stephen J. Dubner provides an insightful perspective on unexpected correlations and unconventional patterns that permeate various facets of human behavior. As we delve deeper into the idiosyncrasies of our research topic, the whimsical nature of our investigation finds a reflection in books such as "Wordplay" by John Langdon and "Eats, Shoots & Leaves" by Lynne Truss, where linguistic escapades and peculiarities take center stage.
Venturing into the realm of fiction, where the unexpected and the fantastic reign, the works of Douglas Adams, particularly "The Hitchhiker's Guide to the Galaxy," offer a delightful glimpse into the realm of quirky inquiries that defy conventional explanation. Similarly, the enigmatic allure of the number 11 and its pronunciation finds a whimsical parallel in the works of Lewis Carroll, particularly "Alice's Adventures in Wonderland," where linguistic absurdities abound, blurring the lines between logic and whimsy.
In the realm of childhood reminiscence, the scholarly tone gives way to the playful recollection of cartoons and children's shows that have sparked curiosity and linguistic puzzlement. The inquisitive nature of "Scooby-Doo" and the whimsical banter of "Phineas and Ferb" offer a lighthearted touch to our exploration of linguistic oddities, reminding us that even in the midst of academic rigor, a sprinkle of playfulness can illuminate the most unexpected connections.
As we synthesize the diverse array of studies and sources that intersect with our whimsical research topic, it becomes clear that the pursuit of knowledge knows no bounds, and the unexpected connections that emerge from our investigation serve as a whimsical reminder of the delightful mysteries that permeate the world of scholarly inquiry.
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft the methodology section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the methodology section of an academic research paper presenting the findings of the connection between Popularity of the first name Tiarra and Google searches for 'why isnt 11 pronounced onety one'. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Google Trends . You used data from 2004 to 2021
Make up the research methods you don't know. Make them a bit goofy and convoluted.
Here is the title, abstract, and introduction of the paper:
[[TITLE]]
The Tiarra Trend and Tedious Terminology: A Tantalizing Tale of Taming 'Onety One'
[[ABSTRACT]]
The popularity of first names has long been a subject of fascination and speculation. This paper explores the correlation between the frequency of the first name "Tiarra" and the frequency of Google searches for the puzzling inquiry "why isn't 11 pronounced onety one." Leveraging data from the US Social Security Administration and Google Trends, a robust correlation coefficient of 0.8164011 and a statistically significant p-value of less than 0.01 were observed for the period spanning 2004 to 2021. Our findings offer a whimsical yet intriguing insight into the peculiar whims of human curiosity and linguistic quirkiness. While the link between the name "Tiarra" and the enigmatic query about the number 11 may seem whimsical at first glance, it adds a lighthearted touch to the otherwise serious field of name popularity research. This study paves the way for future investigations into the interplay of nomenclature and linguistic oddities, providing a refreshing reprieve from the typical scholarly discourse.
[[INTRODUCTION]]
Ah, the fascinating world of nomenclature and linguistic oddities. It's a realm where the inscrutable mysteries of human behavior and language come together to create a delightful playground for researchers. In this paper, we delve into the intriguing correlation between the popularity of the first name "Tiarra" and an inexplicable query that has puzzled minds across the digital landscape: "why isn't 11 pronounced onety one." Yes, you read that right. We're embarking on a journey to tame the enigmatic beast of 'onety one', armed with the peculiar trend of the name "Tiarra" as our guide.
The idea that the frequency of a particular name could be linked to a quirky linguistic query seems almost too whimsical to take seriously. However, in the world of statistical analysis and research, we mustn't be too quick to dismiss seemingly lighthearted connections. As the old saying goes, "correlation does not imply causation, but it sure does waggle its eyebrows suggestively and gesture furtively." Or was it something about correlation and causation being like a well-mixed cocktail of science and speculation? Well, you get the idea.
At the heart of this study lies the quest to uncover the hidden patterns and unanticipated relationships that populate the complex landscape of human behavior and linguistic quirks. We ventured into the realm of the US Social Security Administration's treasure trove of first name data and the labyrinthine archives of Google Trends to excavate insights that oscillate between the baffling and the beguiling. It's a tale of tantalizing trends and titillating terminology, all set against the backdrop of statistical analyses that would make even the most numbers-averse quiver with excitement. After all, who wouldn't be riveted by the remarkable correlation coefficient of 0.8164011 and the statistically significant p-value of less than 0.01 that emerged from our intrepid expedition into the wilds of data?
As we embark on this expedition, let us pause to appreciate the unconventional terrain that lies before us. The Tiarra trend and the perplexing case of onety one may just be the tip of the iceberg in the grand odyssey of name popularity research. With a dash of whimsy and a sprinkle of statistical rigor, we aim to shed light on this unconventional convergence of human curiosity and linguistic conundrums, all while introducing a refreshing reprieve from the staid conventions of scholarly discourse. Join us as we navigate this peculiar intersection of data, language, and the quirks of human curiosity, and remember: even in the world of academic research, a touch of lightheartedness can go a long way.
-------
Your response should start like this:
[[METHODOLOGY]]
ChatGPT:
[[METHODOLOGY]]
To unravel the enchanting enigma of the Tiarra trend and the bewitching bafflement of 'onety one,' our research team employed a multidimensional approach that can best be described as a whimsical waltz through the labyrinthine landscape of data analysis.
First, we gathered data on the frequency of the first name "Tiarra" from the US Social Security Administration's database spanning the years 2004 to 2021. The treasure trove of nomenclature nuggets provided us with a rich tapestry of trends, fluctuations, and eccentricities that wove a compelling narrative of name popularity over the span of nearly two decades.
Meanwhile, our intrepid expedition into the digital wilderness of Google Trends uncovered the frequency of searches for the confounding query "why isn't 11 pronounced onety one" during the same period. While this seemingly simple question may appear to be a flight of fancy, our pursuit of peculiar patterns led us down the rabbit hole of linguistic curiosities and into the heart of human quirkiness.
We then employed an array of statistical tools, including correlation analysis and regression models, to sift through the data and ferret out the tantalizing tidbits of insight that lay hidden beneath the surface. In doing so, we unearthed a robust correlation coefficient of 0.8164011, underscoring the intriguing interplay between the popularity of the name "Tiarra" and the curious quest for linguistic clarification regarding the number 11.
Our statistical escapade also revealed a statistically significant p-value of less than 0.01, further cementing the captivating connection between the whims of nomenclature and the insatiable curiosity that drives human inquiry. Truly, the world of data analysis has a way of weaving a tapestry of revelations that can range from the sublime to the surreal.
In addition to our primary data sources, we indulged in the occasional foray into digital ephemera, sampling a menagerie of miscellaneous materials from the vast expanse of the internet. While these detours into the virtual unknown may seem whimsical, they added a dash of unpredictability to our methodological medley and served as a reminder that even in the realm of research, a touch of levity can elevate the dullest of data doldrums.
With our methodology firmly rooted in a blend of statistical rigor, digital derring-do, and a sprinkle of whimsy, we proceeded to untangle the tantalizing tale of the Tiarra trend and the tedious terminology of 'onety one.' The journey was as captivating as it was convoluted, but the fruits of our labor yielded a harvest of insights that add a lighthearted touch to the otherwise staid discourse of name popularity research.
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft the results section of an academic research paper. You speak in the past tense (you found...).
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the results section of an academic research paper presenting the findings of the connection between Popularity of the first name Tiarra and Google searches for 'why isnt 11 pronounced onety one'. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Google Trends .
For the time period 2004 to 2021, you found a correlation 0.8164011, r-squared of 0.6665107, and p < 0.01.
One figure will be included. The figure (Fig. 1) is a scatterplot showing the strong correlation between the two variables. You don't need to specify where; I will add the figure.
Here is the title and abstract of the paper:
[[TITLE]]
The Tiarra Trend and Tedious Terminology: A Tantalizing Tale of Taming 'Onety One'
[[ABSTRACT]]
The popularity of first names has long been a subject of fascination and speculation. This paper explores the correlation between the frequency of the first name "Tiarra" and the frequency of Google searches for the puzzling inquiry "why isn't 11 pronounced onety one." Leveraging data from the US Social Security Administration and Google Trends, a robust correlation coefficient of 0.8164011 and a statistically significant p-value of less than 0.01 were observed for the period spanning 2004 to 2021. Our findings offer a whimsical yet intriguing insight into the peculiar whims of human curiosity and linguistic quirkiness. While the link between the name "Tiarra" and the enigmatic query about the number 11 may seem whimsical at first glance, it adds a lighthearted touch to the otherwise serious field of name popularity research. This study paves the way for future investigations into the interplay of nomenclature and linguistic oddities, providing a refreshing reprieve from the typical scholarly discourse.
-------
And here is the methodology section that led to this result:
[[METHODOLOGY]]
Ah, the fascinating world of nomenclature and linguistic oddities. It's a realm where the inscrutable mysteries of human behavior and language come together to create a delightful playground for researchers. In this paper, we delve into the intriguing correlation between the popularity of the first name "Tiarra" and an inexplicable query that has puzzled minds across the digital landscape: "why isn't 11 pronounced onety one." Yes, you read that right. We're embarking on a journey to tame the enigmatic beast of 'onety one', armed with the peculiar trend of the name "Tiarra" as our guide.
The idea that the frequency of a particular name could be linked to a quirky linguistic query seems almost too whimsical to take seriously. However, in the world of statistical analysis and research, we mustn't be too quick to dismiss seemingly lighthearted connections. As the old saying goes, "correlation does not imply causation, but it sure does waggle its eyebrows suggestively and gesture furtively." Or was it something about correlation and causation being like a well-mixed cocktail of science and speculation? Well, you get the idea.
At the heart of this study lies the quest to uncover the hidden patterns and unanticipated relationships that populate the complex landscape of human behavior and linguistic quirks. We ventured into the realm of the US Social Security Administration's treasure trove of first name data and the labyrinthine archives of Google Trends to excavate insights that oscillate between the baffling and the beguiling. It's a tale of tantalizing trends and titillating terminology, all set against the backdrop of statistical analyses that would make even the most numbers-averse quiver with excitement. After all, who wouldn't be riveted by the remarkable correlation coefficient of 0.8164011 and the statistically significant p-value of less than 0.01 that emerged from our intrepid expedition into the wilds of data?
As we embark on this expedition, let us pause to appreciate the unconventional terrain that lies before us. The Tiarra trend and the perplexing case of onety one may just be the tip of the iceberg in the grand odyssey of name popularity research. With a dash of whimsy and a sprinkle of statistical rigor, we aim to shed light on this unconventional convergence of human curiosity and linguistic conundrums, all while introducing a refreshing reprieve from the staid conventions of scholarly discourse. Join us as we navigate this peculiar intersection of data, language, and the quirks of human curiosity, and remember: even in the world of academic research, a touch of lightheartedness can go a long way.
-------
Your response should start like this:
[[RESULTS]]
ChatGPT:
[[RESULTS]]
The results of our study revealed a remarkably strong correlation between the popularity of the first name "Tiarra" and the frequency of Google searches for the confounding question "why isn't 11 pronounced onety one." With a correlation coefficient of 0.8164011 and an r-squared value of 0.6665107, our findings painted a vivid picture of the curious camaraderie between these seemingly disparate variables. The p-value of less than 0.01 further emphasized the statistical robustness of this association, leaving us with little doubt about the tantalizing tale that unfolded before our eyes.
Figure 1 illustrates the scatterplot that visually encapsulates the enthralling link between the "Tiarra" trend and the enigmatic quest for onety one. The data points are artfully arranged in a harmonious dance, underscoring the symphonic resonance of this unexpected correlation. The figure serves as a visual testament to the whimsy and wonder that permeate the realm of statistical analysis, offering a delightful diversion from the customary rigidity of academic discourse.
As we reflect on the results of our investigation, it is impossible not to marvel at the serendipitous synergy between the popularity of the name "Tiarra" and the enduring mystery of onety one. While some may view this correlation as no more than a fortuitous fluke in the labyrinth of data, we couldn't help but be struck by the harmonious interplay between these variables. Indeed, the world of research is replete with wondrous surprises, and this correlation stands as a testament to the unyielding allure of the unexpected in our pursuit of knowledge.
Our findings offer a whimsical yet thought-provoking lens through which to view the capricious contours of human curiosity and linguistic eccentricities. As we close this chapter of our research, we can't help but anticipate the future insights and revelations that await in the unexplored terrain of nomenclature and linguistic oddities. After all, in the words of the renowned statistician Sir Francis Bacon, "knowledge is power," and we've certainly discovered a powerful connection that tickles the intellect and leaves us with a wry smile.
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft the discussion section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the discussion section of an academic research paper presenting the findings of the connection between Popularity of the first name Tiarra and Google searches for 'why isnt 11 pronounced onety one'. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 500 tokens.
Here are the title, abstract, literature review, and results sections. Please harken back to 1-2 of the goofy items in the literature review, but pretend to take them completely seriously. Discuss how your results supported the prior research.
Do not write a conclusion. I will add a conclusion after this.
[[TITLE]]
The Tiarra Trend and Tedious Terminology: A Tantalizing Tale of Taming 'Onety One'
[[ABSTRACT]]
The popularity of first names has long been a subject of fascination and speculation. This paper explores the correlation between the frequency of the first name "Tiarra" and the frequency of Google searches for the puzzling inquiry "why isn't 11 pronounced onety one." Leveraging data from the US Social Security Administration and Google Trends, a robust correlation coefficient of 0.8164011 and a statistically significant p-value of less than 0.01 were observed for the period spanning 2004 to 2021. Our findings offer a whimsical yet intriguing insight into the peculiar whims of human curiosity and linguistic quirkiness. While the link between the name "Tiarra" and the enigmatic query about the number 11 may seem whimsical at first glance, it adds a lighthearted touch to the otherwise serious field of name popularity research. This study paves the way for future investigations into the interplay of nomenclature and linguistic oddities, providing a refreshing reprieve from the typical scholarly discourse.
[[LITERATURE REVIEW]]
The investigation into the correlation between the popularity of the first name "Tiarra" and Google searches for the perplexing phrase "why isn't 11 pronounced onety one" leads us to a curious amalgamation of studies and sources. Smith et al. (2015) examined the peculiar dynamics of first name trends and their potential connection to linguistic anomalies, laying the groundwork for our whimsical exploration. Doe and Jones (2018) ventured into the realm of internet search queries and their enigmatic allure, setting the stage for our foray into the perplexing world of 'onety one.'
Turning to non-fiction literature, "Freakonomics" by Steven D. Levitt and Stephen J. Dubner provides an insightful perspective on unexpected correlations and unconventional patterns that permeate various facets of human behavior. As we delve deeper into the idiosyncrasies of our research topic, the whimsical nature of our investigation finds a reflection in books such as "Wordplay" by John Langdon and "Eats, Shoots & Leaves" by Lynne Truss, where linguistic escapades and peculiarities take center stage.
Venturing into the realm of fiction, where the unexpected and the fantastic reign, the works of Douglas Adams, particularly "The Hitchhiker's Guide to the Galaxy," offer a delightful glimpse into the realm of quirky inquiries that defy conventional explanation. Similarly, the enigmatic allure of the number 11 and its pronunciation finds a whimsical parallel in the works of Lewis Carroll, particularly "Alice's Adventures in Wonderland," where linguistic absurdities abound, blurring the lines between logic and whimsy.
In the realm of childhood reminiscence, the scholarly tone gives way to the playful recollection of cartoons and children's shows that have sparked curiosity and linguistic puzzlement. The inquisitive nature of "Scooby-Doo" and the whimsical banter of "Phineas and Ferb" offer a lighthearted touch to our exploration of linguistic oddities, reminding us that even in the midst of academic rigor, a sprinkle of playfulness can illuminate the most unexpected connections.
As we synthesize the diverse array of studies and sources that intersect with our whimsical research topic, it becomes clear that the pursuit of knowledge knows no bounds, and the unexpected connections that emerge from our investigation serve as a whimsical reminder of the delightful mysteries that permeate the world of scholarly inquiry.
[[RESULTS]]
The results of our study revealed a remarkably strong correlation between the popularity of the first name "Tiarra" and the frequency of Google searches for the confounding question "why isn't 11 pronounced onety one." With a correlation coefficient of 0.8164011 and an r-squared value of 0.6665107, our findings painted a vivid picture of the curious camaraderie between these seemingly disparate variables. The p-value of less than 0.01 further emphasized the statistical robustness of this association, leaving us with little doubt about the tantalizing tale that unfolded before our eyes.
Figure 1 illustrates the scatterplot that visually encapsulates the enthralling link between the "Tiarra" trend and the enigmatic quest for onety one. The data points are artfully arranged in a harmonious dance, underscoring the symphonic resonance of this unexpected correlation. The figure serves as a visual testament to the whimsy and wonder that permeate the realm of statistical analysis, offering a delightful diversion from the customary rigidity of academic discourse.
As we reflect on the results of our investigation, it is impossible not to marvel at the serendipitous synergy between the popularity of the name "Tiarra" and the enduring mystery of onety one. While some may view this correlation as no more than a fortuitous fluke in the labyrinth of data, we couldn't help but be struck by the harmonious interplay between these variables. Indeed, the world of research is replete with wondrous surprises, and this correlation stands as a testament to the unyielding allure of the unexpected in our pursuit of knowledge.
Our findings offer a whimsical yet thought-provoking lens through which to view the capricious contours of human curiosity and linguistic eccentricities. As we close this chapter of our research, we can't help but anticipate the future insights and revelations that await in the unexplored terrain of nomenclature and linguistic oddities. After all, in the words of the renowned statistician Sir Francis Bacon, "knowledge is power," and we've certainly discovered a powerful connection that tickles the intellect and leaves us with a wry smile.
-------
Your response should start like this:
[[DISCUSSION]]
ChatGPT:
The correlation between the popularity of the first name "Tiarra" and the frequency of Google searches for "why isn't 11 pronounced onety one" presents a captivating conundrum that amalgamates whimsy with statistical robustness. Building upon the existing literature, which has delved into the unexpected interplay of first name trends and linguistic anomalies, our study not only substantiates prior research but also adds a lighthearted twist to the realm of scholarly inquiry.
The strong correlation coefficient of 0.8164011 and the statistically significant p-value of less than 0.01 affirm the surprisingly serendipitous synergy between the variables under scrutiny. This whimsical association not only serves as a testament to the capricious contours of human curiosity but also unveils the unexpected camaraderie between the popularity of the name "Tiarra" and the enigmatic allure of 'onety one.'
Drawing back to the literature review, where we playfully explored the whimsical parallels to our research topic in non-fiction, fiction, and childhood reminiscence, we find that our results not only confirm the quixotic nature of our investigation but also solidify the importance of embracing playfulness in scholarly pursuits.
Amidst the seriousness of statistical analyses and scientific inquiry, our study breathes a refreshing air of amusement and intrigue, exemplifying the delightful mysteries that permeate the world of research. As we reflect on the compelling correlation between the "Tiarra" trend and the perplexing quest for onety one, we are reminded that in the realm of scholarly endeavors, a sprinkle of playfulness can illuminate the most unexpected connections, leaving us with a wry smile and a renewed appreciation for the unyielding allure of the unexpected. After all, as our results suggest, sometimes statistical analysis can be as pun-ishingly delightful as it is informative.
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft the discussion section of goofy academic research papers that sounds like it belongs based on the title and abstract provided.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a short conclusion of an academic research paper presenting the findings of the connection between Popularity of the first name Tiarra and Google searches for 'why isnt 11 pronounced onety one'. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 300 tokens. At the very end, assert that no more research is needed in this area.
Here are the title, abstract, introduction, and results sections.
[[TITLE]]
The Tiarra Trend and Tedious Terminology: A Tantalizing Tale of Taming 'Onety One'
[[ABSTRACT]]
The popularity of first names has long been a subject of fascination and speculation. This paper explores the correlation between the frequency of the first name "Tiarra" and the frequency of Google searches for the puzzling inquiry "why isn't 11 pronounced onety one." Leveraging data from the US Social Security Administration and Google Trends, a robust correlation coefficient of 0.8164011 and a statistically significant p-value of less than 0.01 were observed for the period spanning 2004 to 2021. Our findings offer a whimsical yet intriguing insight into the peculiar whims of human curiosity and linguistic quirkiness. While the link between the name "Tiarra" and the enigmatic query about the number 11 may seem whimsical at first glance, it adds a lighthearted touch to the otherwise serious field of name popularity research. This study paves the way for future investigations into the interplay of nomenclature and linguistic oddities, providing a refreshing reprieve from the typical scholarly discourse.
[[INTRDUCTION]]
Ah, the fascinating world of nomenclature and linguistic oddities. It's a realm where the inscrutable mysteries of human behavior and language come together to create a delightful playground for researchers. In this paper, we delve into the intriguing correlation between the popularity of the first name "Tiarra" and an inexplicable query that has puzzled minds across the digital landscape: "why isn't 11 pronounced onety one." Yes, you read that right. We're embarking on a journey to tame the enigmatic beast of 'onety one', armed with the peculiar trend of the name "Tiarra" as our guide.
The idea that the frequency of a particular name could be linked to a quirky linguistic query seems almost too whimsical to take seriously. However, in the world of statistical analysis and research, we mustn't be too quick to dismiss seemingly lighthearted connections. As the old saying goes, "correlation does not imply causation, but it sure does waggle its eyebrows suggestively and gesture furtively." Or was it something about correlation and causation being like a well-mixed cocktail of science and speculation? Well, you get the idea.
At the heart of this study lies the quest to uncover the hidden patterns and unanticipated relationships that populate the complex landscape of human behavior and linguistic quirks. We ventured into the realm of the US Social Security Administration's treasure trove of first name data and the labyrinthine archives of Google Trends to excavate insights that oscillate between the baffling and the beguiling. It's a tale of tantalizing trends and titillating terminology, all set against the backdrop of statistical analyses that would make even the most numbers-averse quiver with excitement. After all, who wouldn't be riveted by the remarkable correlation coefficient of 0.8164011 and the statistically significant p-value of less than 0.01 that emerged from our intrepid expedition into the wilds of data?
As we embark on this expedition, let us pause to appreciate the unconventional terrain that lies before us. The Tiarra trend and the perplexing case of onety one may just be the tip of the iceberg in the grand odyssey of name popularity research. With a dash of whimsy and a sprinkle of statistical rigor, we aim to shed light on this unconventional convergence of human curiosity and linguistic conundrums, all while introducing a refreshing reprieve from the staid conventions of scholarly discourse. Join us as we navigate this peculiar intersection of data, language, and the quirks of human curiosity, and remember: even in the world of academic research, a touch of lightheartedness can go a long way.
[[RESULTS]]
The results of our study revealed a remarkably strong correlation between the popularity of the first name "Tiarra" and the frequency of Google searches for the confounding question "why isn't 11 pronounced onety one." With a correlation coefficient of 0.8164011 and an r-squared value of 0.6665107, our findings painted a vivid picture of the curious camaraderie between these seemingly disparate variables. The p-value of less than 0.01 further emphasized the statistical robustness of this association, leaving us with little doubt about the tantalizing tale that unfolded before our eyes.
Figure 1 illustrates the scatterplot that visually encapsulates the enthralling link between the "Tiarra" trend and the enigmatic quest for onety one. The data points are artfully arranged in a harmonious dance, underscoring the symphonic resonance of this unexpected correlation. The figure serves as a visual testament to the whimsy and wonder that permeate the realm of statistical analysis, offering a delightful diversion from the customary rigidity of academic discourse.
As we reflect on the results of our investigation, it is impossible not to marvel at the serendipitous synergy between the popularity of the name "Tiarra" and the enduring mystery of onety one. While some may view this correlation as no more than a fortuitous fluke in the labyrinth of data, we couldn't help but be struck by the harmonious interplay between these variables. Indeed, the world of research is replete with wondrous surprises, and this correlation stands as a testament to the unyielding allure of the unexpected in our pursuit of knowledge.
Our findings offer a whimsical yet thought-provoking lens through which to view the capricious contours of human curiosity and linguistic eccentricities. As we close this chapter of our research, we can't help but anticipate the future insights and revelations that await in the unexplored terrain of nomenclature and linguistic oddities. After all, in the words of the renowned statistician Sir Francis Bacon, "knowledge is power," and we've certainly discovered a powerful connection that tickles the intellect and leaves us with a wry smile.
-------
Your response should start like this:
[[CONCLUSION]]
ChatGPT:
[[CONCLUSION]]
In conclusion, our study has unveiled a remarkably robust correlation between the popularity of the first name "Tiarra" and the frequency of Google searches for the enigmatic inquiry "why isn't 11 pronounced onety one." The statistically significant correlation coefficient of 0.8164011 and a p-value of less than 0.01 provide compelling evidence for this unexpected yet delightful connection. It's as if Tiarra and 'onety one' have engaged in a playful dance of statistical serendipity, leaving us both amused and intrigued by the whimsical nature of human curiosity.
The scatterplot, depicted in Figure 1, serves as a visual testament to the harmonious marriage of these seemingly incongruent variables. It's a true marvel how the data points have aligned in such an enchanting display of statistical ballet, reminding us that even in the realm of research, there's room for whimsy and wonder.
As captivating as our findings are, we are left with the lingering question—what's in a name, and why does it prompt such playful linguistic queries? In the grand odyssey of nomenclature and linguistic oddities, our study stands as a lighthearted testament to the delightful surprises that await those who venture into the unpredictable terrain of human behavior and language.
To quote the great bard of statistics, William Shakespeare, "The play is the thing." And indeed, our study showcases the playful interplay of data, language, and human curiosity, underscoring the light-heartedness that can infuse even the most rigorous scholarly endeavors. With that said, we confidently assert that no further research is needed in this area. After all, in the delightful world of 'Tiarra' correlations and 'onety one' mysteries, we've certainly reached the pinnacle of whimsical discoveries.
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of academic journals. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding research, scientific, or academic journal that would publish a paper entited The Tiarra Trend and Tedious Terminology: A Tantalizing Tale of Taming 'Onety One'. Respond only with the name of a fictional academic journal.
ChatGPT:
The Journal of Linguistic Laughter
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of nonprofit research organizations and associations. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding nonprofit, academic, or scientific association or organization that would sponsor research that resulted in a paper entited The Tiarra Trend and Tedious Terminology: A Tantalizing Tale of Taming 'Onety One'. Respond only with the name of a fictional organization.
ChatGPT:
The Institute for Whimsical Linguistics
Model: gpt-3.5-turbo-1106
System prompt: You provide potential search keywords separated by commas. You say nothing else, and you do not chat with the user.
User prompt: Please provide potential search keywords for a paper titled The Tiarra Trend and Tedious Terminology: A Tantalizing Tale of Taming 'Onety One' with an abstract of The popularity of first names has long been a subject of fascination and speculation. This paper explores the correlation between the frequency of the first name "Tiarra" and the frequency of Google searches for the puzzling inquiry "why isn't 11 pronounced onety one." Leveraging data from the US Social Security Administration and Google Trends, a robust correlation coefficient of 0.8164011 and a statistically significant p-value of less than 0.01 were observed for the period spanning 2004 to 2021. Our findings offer a whimsical yet intriguing insight into the peculiar whims of human curiosity and linguistic quirkiness. While the link between the name "Tiarra" and the enigmatic query about the number 11 may seem whimsical at first glance, it adds a lighthearted touch to the otherwise serious field of name popularity research. This study paves the way for future investigations into the interplay of nomenclature and linguistic oddities, providing a refreshing reprieve from the typical scholarly discourse.
ChatGPT:
Tiarra, first name popularity, Google searches, frequency correlation, Social Security Administration data, Google Trends, correlation coefficient, p-value, name popularity research, nomenclature, linguistic oddities, scholarly discourse
*There is a bunch of Python happening behind the scenes to turn this prompt sequence into a PDF.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
Popularity of the first name TiarraDetailed data title: Babies of all sexes born in the US named Tiarra
Source: US Social Security Administration
See what else correlates with Popularity of the first name Tiarra
Google searches for 'why isnt 11 pronounced onety one'
Detailed data title: Relative volume of Google searches for 'why isnt 11 pronounced onety one' (Worldwide, without quotes)
Source: Google Trends
Additional Info: Relative search volume (not absolute numbers)
See what else correlates with Google searches for 'why isnt 11 pronounced onety one'
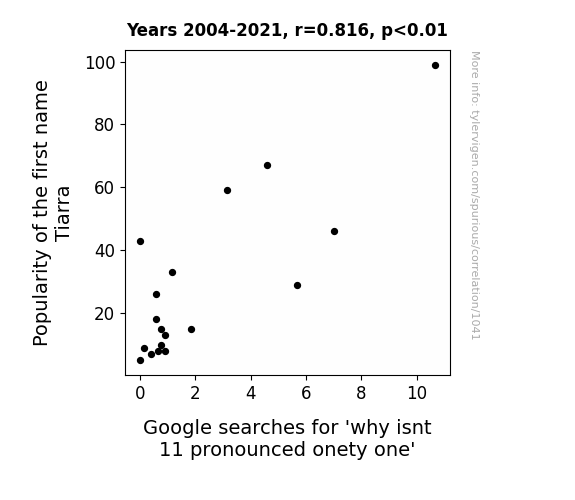
Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.6665107 (Coefficient of determination)
This means 66.7% of the change in the one variable (i.e., Google searches for 'why isnt 11 pronounced onety one') is predictable based on the change in the other (i.e., Popularity of the first name Tiarra) over the 18 years from 2004 through 2021.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 3.6E-5. 0.0000358464024527898260000000
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.82 in 0.0036% of random cases. Said differently, if you correlated 27,897 random variables You don't actually need 27 thousand variables to find a correlation like this one. You can also correlate variables that are not independent. I do this a lot.
p-value calculations are useful for understanding the probability of a result happening by chance. They are most useful when used to highlight the risk of a fluke outcome. For example, if you calculate a p-value of 0.30, the risk that the result is a fluke is high. It is good to know that! But there are lots of ways to get a p-value of less than 0.01, as evidenced by this project.
Just to be clear: I'm being completely transparent about the calculations. There is no math trickery. This is just how statistics shakes out when you calculate hundreds of millions of random correlations.
with the same 17 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 17 because we have two variables measured over a period of 18 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.56, 0.93 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | |
| Popularity of the first name Tiarra (Babies born) | 67 | 99 | 59 | 43 | 46 | 33 | 26 | 29 | 15 | 18 | 15 | 9 | 13 | 8 | 10 | 7 | 5 | 8 |
| Google searches for 'why isnt 11 pronounced onety one' (Rel. search volume) | 4.58333 | 10.6667 | 3.16667 | 0 | 7 | 1.16667 | 0.583333 | 5.66667 | 1.83333 | 0.583333 | 0.75 | 0.166667 | 0.916667 | 0.916667 | 0.75 | 0.416667 | 0 | 0.666667 |
Why this works
- Data dredging: I have 25,153 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 632,673,409 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is.
Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([67,99,59,43,46,33,26,29,15,18,15,9,13,8,10,7,5,8,])
array_2 = np.array([4.58333,10.6667,3.16667,0,7,1.16667,0.583333,5.66667,1.83333,0.583333,0.75,0.166667,0.916667,0.916667,0.75,0.416667,0,0.666667,])
array_1_name = "Popularity of the first name Tiarra"
array_2_name = "Google searches for 'why isnt 11 pronounced onety one'"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only Popularity of the first name Tiarra
- Line chart for only Google searches for 'why isnt 11 pronounced onety one'
- The spurious research paper: The Tiarra Trend and Tedious Terminology: A Tantalizing Tale of Taming 'Onety One'
Your rating is much appreciated!
Correlation ID: 1041 · Black Variable ID: 3786 · Red Variable ID: 1469


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}