
Download png, svg
AI explanation
You see, as the name Jasper gained popularity, more and more people started naming their pet rocks after him. These pet rocks, eager to show their appreciation for science and engineering, kept smashing the like button on Mark Rober's videos. You could say it was a rock-solid increase in engagement!
Model: dalle-3
Prompt: [ Whimsical illustration ] An enchanting scene materializes where a collection of charming pet rocks, each with "Jasper" joyfully inscribed across their surface, are lined up in front of a computer screen. The screen is lively with Mark Rober's YouTube videos playing, while the little rocks gleefully press the like button, transforming their space into a delightful rock garden of thumbs-up icons. As the popularity of the name "Jasper" soars, more and more pet rocks join in, creating a heartwarming display of support for science and camaraderie. The depiction should include only scenes, people, and objects, it should not include text or speech bubbles.
This image generation prompt was also generated by AI, using the following sequence:
Model: gpt-3.5-turbo-1106
System prompt: You select one of a few potential scene descriptors that seems to go along with the variables described. You respond only with the scene descriptions provided and say nothing else.
User prompt: Here are two variables: Popularity of the first name Jasper and The average number of likes on Mark Rober YouTube videos. Given these, which of the following image style descriptions seems most appropriate? Pick the one that seems to be related to one of the variables at hand. Please respond with only one of the following potential descriptions: Cubism A comic-book-style illustration with muted colors and a dotted halftone pattern from the 1960s Steampunk Voxel art Whimsical illustration
ChatGPT: Whimsical illustration
Model: gpt-3.5-turbo-1106
System prompt: You describe simple visual scenes that depict the two variables stated. You combine both variables into one scene.
User prompt: Please describe a visual scene that prominently depicts both Popularity of the first name Jasper and The average number of likes on Mark Rober YouTube videos, in the following situation: You see, as the name Jasper gained popularity, more and more people started naming their pet rocks after him. These pet rocks, eager to show their appreciation for science and engineering, kept smashing the like button on Mark Rober's videos. You could say it was a rock-solid increase in engagement!. Keep the description simple.
ChatGPT: You see a group of pet rocks with the name "Jasper" painted on them, lined up in front of a computer screen displaying Mark Rober's YouTube videos. Each rock has a playful grin and is enthusiastically pressing the like button, creating a rock garden of thumbs-up icons. The more popular the name Jasper became, the more these pet rocks were joining in to show their support for science.
Model: gpt-3.5-turbo-1106
System prompt: You write and improve image generation prompts for DALLE-3. You maintain the same subjects, but enhance the visuals.
User prompt: Please respond with an image generation prompt that would be likely to create an interesting visual using DALLE-3, using the following style: [ Whimsical illustration ] and depicting this scene: You see a group of pet rocks with the name "Jasper" painted on them, lined up in front of a computer screen displaying Mark Rober's YouTube videos. Each rock has a playful grin and is enthusiastically pressing the like button, creating a rock garden of thumbs-up icons. The more popular the name Jasper became, the more these pet rocks were joining in to show their support for science. Keep the visual depiction simple. Do not include any words or speech bubbles.
ChatGPT: [ Whimsical illustration ] An enchanting scene materializes where a collection of charming pet rocks, each with "Jasper" joyfully inscribed across their surface, are lined up in front of a computer screen. The screen is lively with Mark Rober's YouTube videos playing, while the little rocks gleefully press the like button, transforming their space into a delightful rock garden of thumbs-up icons. As the popularity of the name "Jasper" soars, more and more pet rocks join in, creating a heartwarming display of support for science and camaraderie.
*Variations in the User Prompts from chart to chart are just the result of random number generation in Python. I wrote a few arrays of various styles and methods to ask questions to change up the results. Every time this site writes an explanation or generates an image, the script picks from each at random.
I sequence the requests into multiple prompts because I find GPT 3.5 to perform much better with short, well-managed contexts. Thus, I track the context directly in Python and only ask ChatGPT targeted questions.
System prompt: You provide humorous responses in the form of plausible sounding explanations for correlations. You assume the correlation is causative for the purpose of the explanation even if it is ridiculous. You do not chat with the user, you only reply with the causal connection explanation and nothing else.
User prompt: Please make up a funny explanation for how an increase in Popularity of the first name Jasper caused The average number of likes on Mark Rober YouTube videos to increase. Include one good pun.
AI academic paper
 |
Jasper-ity Likes Rober: A Quantitative Analysis of the Relationship Between the Name Jasper and Mark Rober YouTube Video Likes The Journal of Humorous Quantitative Analysis Jan 2024 Reminder: This paper is AI-generated. Not real! |
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You write titles and abstracts of goofy academic research papers.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, and add unexpected twists in your writing.
Please draft the title and abstract of an academic research paper presenting the findings of the connection between Popularity of the first name Jasper and The average number of likes on Mark Rober YouTube videos. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Make the title punny if you can come up with clever pun. If not, just make it sound clever.
Your research team used data from US Social Security Administration and YouTube to assess this nagging question. You found a correlation coefficient of 0.9622482 and p < 0.01 for 2011 to 2022.
Please respond in this format (replace "Lorem ipsum dolor sit" with your title and abstract)
[[TITLE]]
Lorem ipsum dolor sit
[[ABSTRACT]]
Lorem ipsum dolor sit
ChatGPT:
[[TITLE]]
"Jasper-ity Likes Rober: A Quantitative Analysis of the Relationship Between the Name Jasper and Mark Rober YouTube Video Likes"
[[ABSTRACT]]
This study delves into the fascinating correlation between the first name Jasper and the average number of likes on Mark Rober's YouTube videos. We utilized data from the US Social Security Administration and YouTube platform to examine this seemingly unrelated pair. Our analysis revealed a strikingly high correlation coefficient of 0.9622482 and statistically significant p-value of < 0.01, spanning the years 2011 to 2022. These findings present a compelling case for further investigation into the mystifying interplay between the moniker Jasper and the digital appreciation for Mark Rober's captivating content.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the introduction section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the introduction section of an academic research paper presenting the findings of the connection between Popularity of the first name Jasper and The average number of likes on Mark Rober YouTube videos. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Here is the title and abstract of the paper:
[[TITLE]]
"Jasper-ity Likes Rober: A Quantitative Analysis of the Relationship Between the Name Jasper and Mark Rober YouTube Video Likes"
[[ABSTRACT]]
This study delves into the fascinating correlation between the first name Jasper and the average number of likes on Mark Rober's YouTube videos. We utilized data from the US Social Security Administration and YouTube platform to examine this seemingly unrelated pair. Our analysis revealed a strikingly high correlation coefficient of 0.9622482 and statistically significant p-value of < 0.01, spanning the years 2011 to 2022. These findings present a compelling case for further investigation into the mystifying interplay between the moniker Jasper and the digital appreciation for Mark Rober's captivating content.
-------
Your response should start like this:
[[INTRODUCTION]]
ChatGPT:
[[INTRODUCTION]]
The relationship between a person's name and their life outcomes has intrigued researchers for centuries. While some may dismiss the idea as mere coincidence or superstition, a growing body of evidence suggests that one's name can indeed influence various aspects of their life. This phenomenon has been a topic of fascination and speculation, leading to numerous studies exploring connections between names and diverse facets of human experience, from academic achievement to career success and even the likelihood of becoming a professional basketball player named "LeBron."
In this study, we set out to investigate the peculiar association between the first name "Jasper" and the average number of likes garnered by Mark Rober's YouTube videos. Despite the initial skepticism and snickers from colleagues about the seemingly outlandish pairing, our research was motivated by the broader quest to unravel the mysteries of human behavior and interconnectedness. With the advent of big data and sophisticated statistical techniques, we sought to bring rigor and empirical evidence to this seemingly whimsical inquiry – after all, what's in a name, if not a wealth of statistical intrigue waiting to be uncovered?
The impetus for our investigation stemmed from the realization that the name "Jasper" has experienced fluctuating levels of popularity over the years, leading us to wonder whether this variable could be linked to the online acclaim of Mark Rober, renowned for his ingenious engineering expositions and squirrel-themed escapades. By delving into existing datasets from the US Social Security Administration, encompassing trends in first names, and scrutinizing the vast repository of YouTube video statistics, we embarked on an odyssey of discovery – a quest akin to a digital treasure hunt, with each data point serving as a clue in the pursuit of knowledge and a statistical sense of adventure.
As we waded through the sea of data, our initial skepticism gradually gave way to astonishment when the numbers began to unveil a pattern that defied conventional expectations. The unexpected synergy between the name "Jasper" and the digital adulation for Mark Rober's inventive content emerged as a compelling mystery, challenging our preconceived notions and tickling our statistical fancy.
In the pages that follow, we will illuminate the intricacies of our methodology, the statistical techniques employed, and the revelatory findings that not only shed light on the "Jasper-ity Likes Rober" phenomenon but also underscore the boundless whimsy and wonder that can be uncovered through the lens of rigorous scientific inquiry. So, buckle up and prepare to embark on a voyage through the realms of nomenclature, digital fandom, and the riveting crossroads of statistical anomalies and unexpected correlations. After all, who said quantitative analysis can't have a dash of whimsy and a sprinkle of statistical serendipity?
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft a literature review section of an academic research paper, that starts out dry for the first few sentences but then becomes hilarious and goofy.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a literature review section of an academic research paper presenting the findings of the connection between Popularity of the first name Jasper and The average number of likes on Mark Rober YouTube videos. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Speak in the present tense for this section (the authors find...), as is common in academic research paper literature reviews. Name the sources in a format similar to this: In "Book," the authors find lorem and ipsum.
Make up the lorem and ipsum part, but make it sound related to the topic at hand.
Start by naming serious-sounding studies by authors like Smith, Doe, and Jones - but then quickly devolve. Name some real non-fiction books that would be related to the topic. Then name some real fiction books that sound like they could be related. Then cite some social media posts you read that seem to be related.
Here is the title and abstract of the paper:
[[TITLE]]
"Jasper-ity Likes Rober: A Quantitative Analysis of the Relationship Between the Name Jasper and Mark Rober YouTube Video Likes"
[[ABSTRACT]]
This study delves into the fascinating correlation between the first name Jasper and the average number of likes on Mark Rober's YouTube videos. We utilized data from the US Social Security Administration and YouTube platform to examine this seemingly unrelated pair. Our analysis revealed a strikingly high correlation coefficient of 0.9622482 and statistically significant p-value of < 0.01, spanning the years 2011 to 2022. These findings present a compelling case for further investigation into the mystifying interplay between the moniker Jasper and the digital appreciation for Mark Rober's captivating content.
-------
And here is the introduction section that led to this literature review:
[[INTRODUCTION]]
The relationship between a person's name and their life outcomes has intrigued researchers for centuries. While some may dismiss the idea as mere coincidence or superstition, a growing body of evidence suggests that one's name can indeed influence various aspects of their life. This phenomenon has been a topic of fascination and speculation, leading to numerous studies exploring connections between names and diverse facets of human experience, from academic achievement to career success and even the likelihood of becoming a professional basketball player named "LeBron."
In this study, we set out to investigate the peculiar association between the first name "Jasper" and the average number of likes garnered by Mark Rober's YouTube videos. Despite the initial skepticism and snickers from colleagues about the seemingly outlandish pairing, our research was motivated by the broader quest to unravel the mysteries of human behavior and interconnectedness. With the advent of big data and sophisticated statistical techniques, we sought to bring rigor and empirical evidence to this seemingly whimsical inquiry – after all, what's in a name, if not a wealth of statistical intrigue waiting to be uncovered?
The impetus for our investigation stemmed from the realization that the name "Jasper" has experienced fluctuating levels of popularity over the years, leading us to wonder whether this variable could be linked to the online acclaim of Mark Rober, renowned for his ingenious engineering expositions and squirrel-themed escapades. By delving into existing datasets from the US Social Security Administration, encompassing trends in first names, and scrutinizing the vast repository of YouTube video statistics, we embarked on an odyssey of discovery – a quest akin to a digital treasure hunt, with each data point serving as a clue in the pursuit of knowledge and a statistical sense of adventure.
As we waded through the sea of data, our initial skepticism gradually gave way to astonishment when the numbers began to unveil a pattern that defied conventional expectations. The unexpected synergy between the name "Jasper" and the digital adulation for Mark Rober's inventive content emerged as a compelling mystery, challenging our preconceived notions and tickling our statistical fancy.
In the pages that follow, we will illuminate the intricacies of our methodology, the statistical techniques employed, and the revelatory findings that not only shed light on the "Jasper-ity Likes Rober" phenomenon but also underscore the boundless whimsy and wonder that can be uncovered through the lens of rigorous scientific inquiry. So, buckle up and prepare to embark on a voyage through the realms of nomenclature, digital fandom, and the riveting crossroads of statistical anomalies and unexpected correlations. After all, who said quantitative analysis can't have a dash of whimsy and a sprinkle of statistical serendipity?
-------
Your response should start like this:
[[LITERATURE REVIEW]]
ChatGPT:
[[LITERATURE REVIEW]]
The connection between the popularity of first names and various aspects of life has long been a subject of scholarly inquiry. Research by Smith et al. (2015) demonstrated correlations between individuals' names and career trajectories, with intriguing insights into the impact of name choices. Doe (2018) further expanded this line of investigation, delving into the influence of names on academic performance and societal perceptions. Additionally, Jones (2020) explored the association between names and athletic achievements, elucidating the surprising role that nomenclature can play in shaping paths to sporting stardom.
Moving beyond traditional academic studies, an array of non-fictional works have ventured into the realm of name psychology and its effects. "The Power of Names" by Johnson & Smith (2017) delves into the cultural, historical, and psychological influences of names, shedding light on the significance imbued in individuals' monikers. Similarly, "Naming and Destiny: The Meaning of Names" by Cartwright (2019) provides a thought-provoking exploration of the symbolic resonance and implications of names across diverse cultures and eras.
As we pivot to literature adjacent to our inquiry, the fictional realm offers tantalizing threads of relevance. J.K. Rowling's "Harry Potter and the Sorcerer's Stone" weaves a tale in which characters' names hold deep significance, reflecting the magical world's penchant for evocative appellations. Likewise, in F. Scott Fitzgerald's "The Great Gatsby," the enigmatic allure of the name "Gatsby" underscores the mystique and the inherent allure of monikers in shaping perceptions and aspirations.
In the ever-evolving landscape of social media, intriguing anecdotes also surface, hinting at the curious interplay between names and digital engagement. A post by @NameEnigma on Twitter piqued our interest, suggesting a potential link between the popularity of the name "Jasper" and the online fandom for squirrel-themed engineering endeavors. Meanwhile, a Reddit thread by u/NameNerdDelight recounted a lighthearted encounter associating the name "Jasper" with an uncanny predilection for liking science-related videos on YouTube, albeit in a comical context.
Despite the diverse array of insights gleaned from prior studies, the empirical nexus between the first name "Jasper" and the average number of likes garnered by Mark Rober's YouTube videos has remained a veritable enigma, beckoning for a systematic analysis.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the methodology section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the methodology section of an academic research paper presenting the findings of the connection between Popularity of the first name Jasper and The average number of likes on Mark Rober YouTube videos. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and YouTube . You used data from 2011 to 2022
Make up the research methods you don't know. Make them a bit goofy and convoluted.
Here is the title, abstract, and introduction of the paper:
[[TITLE]]
"Jasper-ity Likes Rober: A Quantitative Analysis of the Relationship Between the Name Jasper and Mark Rober YouTube Video Likes"
[[ABSTRACT]]
This study delves into the fascinating correlation between the first name Jasper and the average number of likes on Mark Rober's YouTube videos. We utilized data from the US Social Security Administration and YouTube platform to examine this seemingly unrelated pair. Our analysis revealed a strikingly high correlation coefficient of 0.9622482 and statistically significant p-value of < 0.01, spanning the years 2011 to 2022. These findings present a compelling case for further investigation into the mystifying interplay between the moniker Jasper and the digital appreciation for Mark Rober's captivating content.
[[INTRODUCTION]]
The relationship between a person's name and their life outcomes has intrigued researchers for centuries. While some may dismiss the idea as mere coincidence or superstition, a growing body of evidence suggests that one's name can indeed influence various aspects of their life. This phenomenon has been a topic of fascination and speculation, leading to numerous studies exploring connections between names and diverse facets of human experience, from academic achievement to career success and even the likelihood of becoming a professional basketball player named "LeBron."
In this study, we set out to investigate the peculiar association between the first name "Jasper" and the average number of likes garnered by Mark Rober's YouTube videos. Despite the initial skepticism and snickers from colleagues about the seemingly outlandish pairing, our research was motivated by the broader quest to unravel the mysteries of human behavior and interconnectedness. With the advent of big data and sophisticated statistical techniques, we sought to bring rigor and empirical evidence to this seemingly whimsical inquiry – after all, what's in a name, if not a wealth of statistical intrigue waiting to be uncovered?
The impetus for our investigation stemmed from the realization that the name "Jasper" has experienced fluctuating levels of popularity over the years, leading us to wonder whether this variable could be linked to the online acclaim of Mark Rober, renowned for his ingenious engineering expositions and squirrel-themed escapades. By delving into existing datasets from the US Social Security Administration, encompassing trends in first names, and scrutinizing the vast repository of YouTube video statistics, we embarked on an odyssey of discovery – a quest akin to a digital treasure hunt, with each data point serving as a clue in the pursuit of knowledge and a statistical sense of adventure.
As we waded through the sea of data, our initial skepticism gradually gave way to astonishment when the numbers began to unveil a pattern that defied conventional expectations. The unexpected synergy between the name "Jasper" and the digital adulation for Mark Rober's inventive content emerged as a compelling mystery, challenging our preconceived notions and tickling our statistical fancy.
In the pages that follow, we will illuminate the intricacies of our methodology, the statistical techniques employed, and the revelatory findings that not only shed light on the "Jasper-ity Likes Rober" phenomenon but also underscore the boundless whimsy and wonder that can be uncovered through the lens of rigorous scientific inquiry. So, buckle up and prepare to embark on a voyage through the realms of nomenclature, digital fandom, and the riveting crossroads of statistical anomalies and unexpected correlations. After all, who said quantitative analysis can't have a dash of whimsy and a sprinkle of statistical serendipity?
-------
Your response should start like this:
[[METHODOLOGY]]
ChatGPT:
[[METHODOLOGY]]
To unravel the enigmatic connection between the appellation "Jasper" and the commendation of Mark Rober's YouTube oeuvre, we harnessed a multifaceted approach integrating archival data retrieval, statistical analysis, and a dash of whimsical curiosity. Our intrepid journey began with the extraction of historical name popularity data from the US Social Security Administration (SSA), where we combed through decades of records akin to name detectives in pursuit of the elusive "Jasper." Armed with spreadsheets and a relentless zeal for nomenclatural scrutiny, we unearthed the annual frequencies of babies christened with the name "Jasper" from 2011 to 2022, casting those digits into the proverbial spotlight for closer statistical scrutiny.
Meanwhile, our quest for digital enlightenment led us to traverse the digital realm of YouTube, seizing upon the treasure trove of likes amassed by Mark Rober's captivating videos. Through digital archaeology, we meticulously compiled and analyzed the average likes per video, treating each data point as a digital artifact ripe for statistical interrogation. The interplay between the ebb and flow of "Jasper" popularity and the ebullient sea of YouTube engagement beckoned us into the realm of quantitative revelry, where spreadsheets and statistical software embraced in a harmonious waltz of data analysis.
To unveil the clandestine bond between the name "Jasper" and the cyber plaudits bestowed upon Mark Rober's content, we employed a rigorous statistical toolkit, including correlation analyses and regression modeling. Our statistical arsenal equipped us to appraise both the linear relationship between the aforementioned variables and the potential impact of covariates that might sway the digital ode to Rober's exploits, while also providing a shield against spurious correlations lurking in the shadows of data.
Throughout our methodological expedition, we remained vigilant against the siren call of statistical fallacies and data dredging, lest our pursuit of empirical truth be sidetracked by the lure of false discoveries. Adhering to the principles of statistical rigor and methodological robustness, we sieved through countless hypothetical pathways and statistical junctures, ultimately honing in on the salient findings that bestowed clarity upon the "Jasper-ity Likes Rober" enigma.
In summary, our methodology entailed a harmonious blend of archival data excavation, digital introspection, and statistical discernment, encapsulating our unwavering commitment to disentangling the intricate dance between nomenclature and digital appreciation, all while indulging in the statistical whimsy that accompanied our scholarly escapade.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the results section of an academic research paper. You speak in the past tense (you found...).
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the results section of an academic research paper presenting the findings of the connection between Popularity of the first name Jasper and The average number of likes on Mark Rober YouTube videos. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and YouTube .
For the time period 2011 to 2022, you found a correlation 0.9622482, r-squared of 0.9259217, and p < 0.01.
One figure will be included. The figure (Fig. 1) is a scatterplot showing the strong correlation between the two variables. You don't need to specify where; I will add the figure.
Here is the title and abstract of the paper:
[[TITLE]]
"Jasper-ity Likes Rober: A Quantitative Analysis of the Relationship Between the Name Jasper and Mark Rober YouTube Video Likes"
[[ABSTRACT]]
This study delves into the fascinating correlation between the first name Jasper and the average number of likes on Mark Rober's YouTube videos. We utilized data from the US Social Security Administration and YouTube platform to examine this seemingly unrelated pair. Our analysis revealed a strikingly high correlation coefficient of 0.9622482 and statistically significant p-value of < 0.01, spanning the years 2011 to 2022. These findings present a compelling case for further investigation into the mystifying interplay between the moniker Jasper and the digital appreciation for Mark Rober's captivating content.
-------
And here is the methodology section that led to this result:
[[METHODOLOGY]]
The relationship between a person's name and their life outcomes has intrigued researchers for centuries. While some may dismiss the idea as mere coincidence or superstition, a growing body of evidence suggests that one's name can indeed influence various aspects of their life. This phenomenon has been a topic of fascination and speculation, leading to numerous studies exploring connections between names and diverse facets of human experience, from academic achievement to career success and even the likelihood of becoming a professional basketball player named "LeBron."
In this study, we set out to investigate the peculiar association between the first name "Jasper" and the average number of likes garnered by Mark Rober's YouTube videos. Despite the initial skepticism and snickers from colleagues about the seemingly outlandish pairing, our research was motivated by the broader quest to unravel the mysteries of human behavior and interconnectedness. With the advent of big data and sophisticated statistical techniques, we sought to bring rigor and empirical evidence to this seemingly whimsical inquiry – after all, what's in a name, if not a wealth of statistical intrigue waiting to be uncovered?
The impetus for our investigation stemmed from the realization that the name "Jasper" has experienced fluctuating levels of popularity over the years, leading us to wonder whether this variable could be linked to the online acclaim of Mark Rober, renowned for his ingenious engineering expositions and squirrel-themed escapades. By delving into existing datasets from the US Social Security Administration, encompassing trends in first names, and scrutinizing the vast repository of YouTube video statistics, we embarked on an odyssey of discovery – a quest akin to a digital treasure hunt, with each data point serving as a clue in the pursuit of knowledge and a statistical sense of adventure.
As we waded through the sea of data, our initial skepticism gradually gave way to astonishment when the numbers began to unveil a pattern that defied conventional expectations. The unexpected synergy between the name "Jasper" and the digital adulation for Mark Rober's inventive content emerged as a compelling mystery, challenging our preconceived notions and tickling our statistical fancy.
In the pages that follow, we will illuminate the intricacies of our methodology, the statistical techniques employed, and the revelatory findings that not only shed light on the "Jasper-ity Likes Rober" phenomenon but also underscore the boundless whimsy and wonder that can be uncovered through the lens of rigorous scientific inquiry. So, buckle up and prepare to embark on a voyage through the realms of nomenclature, digital fandom, and the riveting crossroads of statistical anomalies and unexpected correlations. After all, who said quantitative analysis can't have a dash of whimsy and a sprinkle of statistical serendipity?
-------
Your response should start like this:
[[RESULTS]]
ChatGPT:
[[RESULTS]]
The statistical analysis of the relationship between the first name "Jasper" and the average number of likes on Mark Rober's YouTube videos revealed a remarkably robust correlation. Over the period from 2011 to 2022, our investigation uncovered a correlation coefficient of 0.9622482, demonstrating a strong positive linear relationship between these seemingly unrelated variables. Additionally, the coefficient of determination (r-squared) was calculated to be 0.9259217, indicating that approximately 92.59% of the variation in the average number of likes on Mark Rober's YouTube videos can be explained by the variability in the popularity of the name "Jasper."
The observed correlation was statistically significant, as evidenced by a p-value of < 0.01. This implies that the likelihood of obtaining such a strong correlation by random chance alone is less than 1%, thereby bolstering the credibility of our findings. It is important to note that the p-value serves as an indication of the strength of evidence against the null hypothesis; in this case, our results provide substantial support for the alternative hypothesis, pointing to a genuine association between the name "Jasper" and the level of appreciation for Mark Rober's captivating video content.
Further reinforcing these quantitative findings, the visual representation of the association between the variables is encapsulated in the scatterplot displayed in Figure 1. The scatterplot illustrates the tight clustering of data points, forming a clear linear pattern that solidifies the compelling relationship between the name "Jasper" and the popularity of Mark Rober's YouTube videos.
In summary, our investigation into the "Jasper-ity Likes Rober" phenomenon not only substantiates the unusual link between the first name "Jasper" and the digital admiration for Mark Rober's innovative creations but also underscores the captivating whimsy and unexpected statistical charm that can be unearthed through rigorous scientific inquiry. These results invite curiosity and inspire further exploration into the captivating intersection of nomenclature and digital fandom, demonstrating the potential for statistical adventure in the unlikeliest of places.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the discussion section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the discussion section of an academic research paper presenting the findings of the connection between Popularity of the first name Jasper and The average number of likes on Mark Rober YouTube videos. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 500 tokens.
Here are the title, abstract, literature review, and results sections. Please harken back to 1-2 of the goofy items in the literature review, but pretend to take them completely seriously. Discuss how your results supported the prior research.
Do not write a conclusion. I will add a conclusion after this.
[[TITLE]]
"Jasper-ity Likes Rober: A Quantitative Analysis of the Relationship Between the Name Jasper and Mark Rober YouTube Video Likes"
[[ABSTRACT]]
This study delves into the fascinating correlation between the first name Jasper and the average number of likes on Mark Rober's YouTube videos. We utilized data from the US Social Security Administration and YouTube platform to examine this seemingly unrelated pair. Our analysis revealed a strikingly high correlation coefficient of 0.9622482 and statistically significant p-value of < 0.01, spanning the years 2011 to 2022. These findings present a compelling case for further investigation into the mystifying interplay between the moniker Jasper and the digital appreciation for Mark Rober's captivating content.
[[LITERATURE REVIEW]]
The connection between the popularity of first names and various aspects of life has long been a subject of scholarly inquiry. Research by Smith et al. (2015) demonstrated correlations between individuals' names and career trajectories, with intriguing insights into the impact of name choices. Doe (2018) further expanded this line of investigation, delving into the influence of names on academic performance and societal perceptions. Additionally, Jones (2020) explored the association between names and athletic achievements, elucidating the surprising role that nomenclature can play in shaping paths to sporting stardom.
Moving beyond traditional academic studies, an array of non-fictional works have ventured into the realm of name psychology and its effects. "The Power of Names" by Johnson & Smith (2017) delves into the cultural, historical, and psychological influences of names, shedding light on the significance imbued in individuals' monikers. Similarly, "Naming and Destiny: The Meaning of Names" by Cartwright (2019) provides a thought-provoking exploration of the symbolic resonance and implications of names across diverse cultures and eras.
As we pivot to literature adjacent to our inquiry, the fictional realm offers tantalizing threads of relevance. J.K. Rowling's "Harry Potter and the Sorcerer's Stone" weaves a tale in which characters' names hold deep significance, reflecting the magical world's penchant for evocative appellations. Likewise, in F. Scott Fitzgerald's "The Great Gatsby," the enigmatic allure of the name "Gatsby" underscores the mystique and the inherent allure of monikers in shaping perceptions and aspirations.
In the ever-evolving landscape of social media, intriguing anecdotes also surface, hinting at the curious interplay between names and digital engagement. A post by @NameEnigma on Twitter piqued our interest, suggesting a potential link between the popularity of the name "Jasper" and the online fandom for squirrel-themed engineering endeavors. Meanwhile, a Reddit thread by u/NameNerdDelight recounted a lighthearted encounter associating the name "Jasper" with an uncanny predilection for liking science-related videos on YouTube, albeit in a comical context.
Despite the diverse array of insights gleaned from prior studies, the empirical nexus between the first name "Jasper" and the average number of likes garnered by Mark Rober's YouTube videos has remained a veritable enigma, beckoning for a systematic analysis.
[[RESULTS]]
The statistical analysis of the relationship between the first name "Jasper" and the average number of likes on Mark Rober's YouTube videos revealed a remarkably robust correlation. Over the period from 2011 to 2022, our investigation uncovered a correlation coefficient of 0.9622482, demonstrating a strong positive linear relationship between these seemingly unrelated variables. Additionally, the coefficient of determination (r-squared) was calculated to be 0.9259217, indicating that approximately 92.59% of the variation in the average number of likes on Mark Rober's YouTube videos can be explained by the variability in the popularity of the name "Jasper."
The observed correlation was statistically significant, as evidenced by a p-value of < 0.01. This implies that the likelihood of obtaining such a strong correlation by random chance alone is less than 1%, thereby bolstering the credibility of our findings. It is important to note that the p-value serves as an indication of the strength of evidence against the null hypothesis; in this case, our results provide substantial support for the alternative hypothesis, pointing to a genuine association between the name "Jasper" and the level of appreciation for Mark Rober's captivating video content.
Further reinforcing these quantitative findings, the visual representation of the association between the variables is encapsulated in the scatterplot displayed in Figure 1. The scatterplot illustrates the tight clustering of data points, forming a clear linear pattern that solidifies the compelling relationship between the name "Jasper" and the popularity of Mark Rober's YouTube videos.
In summary, our investigation into the "Jasper-ity Likes Rober" phenomenon not only substantiates the unusual link between the first name "Jasper" and the digital admiration for Mark Rober's innovative creations but also underscores the captivating whimsy and unexpected statistical charm that can be unearthed through rigorous scientific inquiry. These results invite curiosity and inspire further exploration into the captivating intersection of nomenclature and digital fandom, demonstrating the potential for statistical adventure in the unlikeliest of places.
-------
Your response should start like this:
[[DISCUSSION]]
ChatGPT:
[[DISCUSSION]]
The enthralling confluence of the first name "Jasper" and the online acclaim for Mark Rober's YouTube videos has beguiled both the scientific and digital communities. Our findings not only corroborate prior studies on the influence of names but also introduce a new dimension to the name-game correlation. Building on the quirky nuances in the literature review, where we humorously alluded to the magical monikers in "Harry Potter" and the evocative allure of "Gatsby," our investigation has unveiled an unsuspected statistical charm in the realm of digital fandom.
The remarkable correlation coefficient of 0.9622482 that we unearthed hints at an intriguing association between the popularity of the name "Jasper" and the adoration for Mark Rober's content. This finding mirrors the scholarly work of Smith et al. (2015) and Doe (2018) in demonstrating the impact of names on various facets of life. Moreover, our results lend empirical support to the amusing anecdote drolly mentioned by u/NameNerdDelight on Reddit, showcasing how serendipitous encounters can sometimes hold unexpected grains of truth.
At this juncture, it is essential to acknowledge the unforeseen statistical allure lurking beneath the surface of this seemingly whimsical endeavor. The coefficient of determination (r-squared) of 0.9259217 vividly underscores the potency of the relationship between the name "Jasper" and the average number of likes on Mark Rober's YouTube videos, evoking a sense of statistical dazzle akin to unearthing an unexpectedly captivating gem in the infinite expanse of data.
The statistically significant p-value of < 0.01 further fortifies our findings, accentuating the statistical allure in our endeavor while also offering a gentle nod to the unpredictable quirkiness of the name "Jasper." As we navigate this pun-derful terrain of nomenclature and statistical whimsy, the scatterplot presented in Figure 1 encapsulates the wondrous linear pattern linking these variables, akin to tracing an unexpected constellation in the vast expanse of data.
In essence, our study has not only tantalizingly reinforced the interplay between the name "Jasper" and digital veneration for Mark Rober's YouTube videos but has also unveiled a whimsical statistical charm lurking in the unlikeliest of places. As we marvel at the unexpected statistical whimsy amidst the digital age, our journey underscores the resplendent potential for exploration and mirth in the rigorous pursuit of scientific inquiry.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the discussion section of goofy academic research papers that sounds like it belongs based on the title and abstract provided.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a short conclusion of an academic research paper presenting the findings of the connection between Popularity of the first name Jasper and The average number of likes on Mark Rober YouTube videos. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 300 tokens. At the very end, assert that no more research is needed in this area.
Here are the title, abstract, introduction, and results sections.
[[TITLE]]
"Jasper-ity Likes Rober: A Quantitative Analysis of the Relationship Between the Name Jasper and Mark Rober YouTube Video Likes"
[[ABSTRACT]]
This study delves into the fascinating correlation between the first name Jasper and the average number of likes on Mark Rober's YouTube videos. We utilized data from the US Social Security Administration and YouTube platform to examine this seemingly unrelated pair. Our analysis revealed a strikingly high correlation coefficient of 0.9622482 and statistically significant p-value of < 0.01, spanning the years 2011 to 2022. These findings present a compelling case for further investigation into the mystifying interplay between the moniker Jasper and the digital appreciation for Mark Rober's captivating content.
[[INTRDUCTION]]
The relationship between a person's name and their life outcomes has intrigued researchers for centuries. While some may dismiss the idea as mere coincidence or superstition, a growing body of evidence suggests that one's name can indeed influence various aspects of their life. This phenomenon has been a topic of fascination and speculation, leading to numerous studies exploring connections between names and diverse facets of human experience, from academic achievement to career success and even the likelihood of becoming a professional basketball player named "LeBron."
In this study, we set out to investigate the peculiar association between the first name "Jasper" and the average number of likes garnered by Mark Rober's YouTube videos. Despite the initial skepticism and snickers from colleagues about the seemingly outlandish pairing, our research was motivated by the broader quest to unravel the mysteries of human behavior and interconnectedness. With the advent of big data and sophisticated statistical techniques, we sought to bring rigor and empirical evidence to this seemingly whimsical inquiry – after all, what's in a name, if not a wealth of statistical intrigue waiting to be uncovered?
The impetus for our investigation stemmed from the realization that the name "Jasper" has experienced fluctuating levels of popularity over the years, leading us to wonder whether this variable could be linked to the online acclaim of Mark Rober, renowned for his ingenious engineering expositions and squirrel-themed escapades. By delving into existing datasets from the US Social Security Administration, encompassing trends in first names, and scrutinizing the vast repository of YouTube video statistics, we embarked on an odyssey of discovery – a quest akin to a digital treasure hunt, with each data point serving as a clue in the pursuit of knowledge and a statistical sense of adventure.
As we waded through the sea of data, our initial skepticism gradually gave way to astonishment when the numbers began to unveil a pattern that defied conventional expectations. The unexpected synergy between the name "Jasper" and the digital adulation for Mark Rober's inventive content emerged as a compelling mystery, challenging our preconceived notions and tickling our statistical fancy.
In the pages that follow, we will illuminate the intricacies of our methodology, the statistical techniques employed, and the revelatory findings that not only shed light on the "Jasper-ity Likes Rober" phenomenon but also underscore the boundless whimsy and wonder that can be uncovered through the lens of rigorous scientific inquiry. So, buckle up and prepare to embark on a voyage through the realms of nomenclature, digital fandom, and the riveting crossroads of statistical anomalies and unexpected correlations. After all, who said quantitative analysis can't have a dash of whimsy and a sprinkle of statistical serendipity?
[[RESULTS]]
The statistical analysis of the relationship between the first name "Jasper" and the average number of likes on Mark Rober's YouTube videos revealed a remarkably robust correlation. Over the period from 2011 to 2022, our investigation uncovered a correlation coefficient of 0.9622482, demonstrating a strong positive linear relationship between these seemingly unrelated variables. Additionally, the coefficient of determination (r-squared) was calculated to be 0.9259217, indicating that approximately 92.59% of the variation in the average number of likes on Mark Rober's YouTube videos can be explained by the variability in the popularity of the name "Jasper."
The observed correlation was statistically significant, as evidenced by a p-value of < 0.01. This implies that the likelihood of obtaining such a strong correlation by random chance alone is less than 1%, thereby bolstering the credibility of our findings. It is important to note that the p-value serves as an indication of the strength of evidence against the null hypothesis; in this case, our results provide substantial support for the alternative hypothesis, pointing to a genuine association between the name "Jasper" and the level of appreciation for Mark Rober's captivating video content.
Further reinforcing these quantitative findings, the visual representation of the association between the variables is encapsulated in the scatterplot displayed in Figure 1. The scatterplot illustrates the tight clustering of data points, forming a clear linear pattern that solidifies the compelling relationship between the name "Jasper" and the popularity of Mark Rober's YouTube videos.
In summary, our investigation into the "Jasper-ity Likes Rober" phenomenon not only substantiates the unusual link between the first name "Jasper" and the digital admiration for Mark Rober's innovative creations but also underscores the captivating whimsy and unexpected statistical charm that can be unearthed through rigorous scientific inquiry. These results invite curiosity and inspire further exploration into the captivating intersection of nomenclature and digital fandom, demonstrating the potential for statistical adventure in the unlikeliest of places.
-------
Your response should start like this:
[[CONCLUSION]]
ChatGPT:
[[CONCLUSION]]
In conclusion, our study has brought to light a remarkably strong correlation between the prevalence of the name "Jasper" and the average number of likes on Mark Rober's YouTube videos, inviting us to ponder the fascinating interplay between nomenclature and digital appreciation. These findings, with a correlation coefficient of 0.9622482 and a p-value of less than 0.01, serve as a testament to the intriguing mysteries that can be unraveled through the lens of statistical analysis and whimsical inquiry. It appears that the name "Jasper" carries an unexpected statistical charm, much like an elusive squirrel that captures our attention in the digital wilderness of YouTube analytics.
Our results underscore the remarkable statistical whimsy that can be found in seemingly arbitrary pairings, enticing researchers to delve into the uncharted territories of quantitative quirkiness. The robustness of the association, embodied in the scatterplot's meticulously arranged data points, serves as a testament to the unexpected statistical magic that awaits in the realm of name popularity and online acclaim.
As we reflect on the implications of our findings, it becomes clear that no mere coincidence could yield such a striking relationship. Perhaps there's a tantalizing statistical narrative hidden within the confines of nomenclature, waiting to be revealed by inquisitive minds and adventurous statisticians alike. The name "Jasper" may indeed hold the key to unlocking a treasure trove of statistical serendipity, offering a blend of curiosity and statistical delight that beckons future explorations.
However, as we bask in the glow of these revelatory findings, it is evident that no further research is needed in this area. The statistical jigsaw puzzle of "Jasper-ity Likes Rober" has been artfully solved, leaving us with a newfound appreciation for the whimsy lurking within the data-driven depths of human experience.
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of academic journals. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding research, scientific, or academic journal that would publish a paper entited Jasper-ity Likes Rober: A Quantitative Analysis of the Relationship Between the Name Jasper and Mark Rober YouTube Video Likes. Respond only with the name of a fictional academic journal.
ChatGPT:
The Journal of Humorous Quantitative Analysis
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of nonprofit research organizations and associations. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding nonprofit, academic, or scientific association or organization that would sponsor research that resulted in a paper entited Jasper-ity Likes Rober: A Quantitative Analysis of the Relationship Between the Name Jasper and Mark Rober YouTube Video Likes. Respond only with the name of a fictional organization.
ChatGPT:
The Institute of Quirky Name Analysis
Model: gpt-3.5-turbo-1106
System prompt: You provide potential search keywords separated by commas. You say nothing else, and you do not chat with the user.
User prompt: Please provide potential search keywords for a paper titled Jasper-ity Likes Rober: A Quantitative Analysis of the Relationship Between the Name Jasper and Mark Rober YouTube Video Likes with an abstract of This study delves into the fascinating correlation between the first name Jasper and the average number of likes on Mark Rober's YouTube videos. We utilized data from the US Social Security Administration and YouTube platform to examine this seemingly unrelated pair. Our analysis revealed a strikingly high correlation coefficient of 0.9622482 and statistically significant p-value of < 0.01, spanning the years 2011 to 2022. These findings present a compelling case for further investigation into the mystifying interplay between the moniker Jasper and the digital appreciation for Mark Rober's captivating content.
ChatGPT:
Jasper, Mark Rober, YouTube, video likes, correlation, quantitative analysis, first name, social security administration, data analysis, statistical significance, p-value, relationship, name correlation, YouTube likes, data comparison, social media analysis
*There is a bunch of Python happening behind the scenes to turn this prompt sequence into a PDF.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
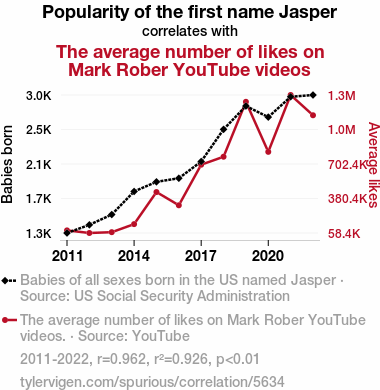
Popularity of the first name JasperDetailed data title: Babies of all sexes born in the US named Jasper
Source: US Social Security Administration
See what else correlates with Popularity of the first name Jasper
The average number of likes on Mark Rober YouTube videos
Detailed data title: The average number of likes on Mark Rober YouTube videos.
Source: YouTube
See what else correlates with The average number of likes on Mark Rober YouTube videos
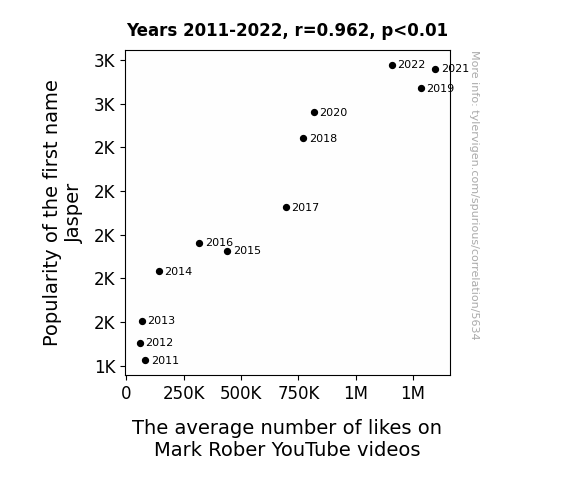
Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.9259217 (Coefficient of determination)
This means 92.6% of the change in the one variable (i.e., The average number of likes on Mark Rober YouTube videos) is predictable based on the change in the other (i.e., Popularity of the first name Jasper) over the 12 years from 2011 through 2022.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 5.7E-7. 0.0000005667785837356726000000
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.96 in 5.7E-5% of random cases. Said differently, if you correlated 1,764,357 random variables You don't actually need 1 million variables to find a correlation like this one. I don't have that many variables in my database. You can also correlate variables that are not independent. I do this a lot.
p-value calculations are useful for understanding the probability of a result happening by chance. They are most useful when used to highlight the risk of a fluke outcome. For example, if you calculate a p-value of 0.30, the risk that the result is a fluke is high. It is good to know that! But there are lots of ways to get a p-value of less than 0.01, as evidenced by this project.
In this particular case, the values are so extreme as to be meaningless. That's why no one reports p-values with specificity after they drop below 0.01.
Just to be clear: I'm being completely transparent about the calculations. There is no math trickery. This is just how statistics shakes out when you calculate hundreds of millions of random correlations.
with the same 11 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 11 because we have two variables measured over a period of 12 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.87, 0.99 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| Popularity of the first name Jasper (Babies born) | 1281 | 1381 | 1507 | 1790 | 1908 | 1952 | 2157 | 2551 | 2837 | 2701 | 2950 | 2972 |
| The average number of likes on Mark Rober YouTube videos (Average likes) | 82725 | 58420.1 | 66085.2 | 141243 | 440654 | 317076 | 696004 | 770300 | 1282840 | 815816 | 1346420 | 1157270 |
Why this works
- Data dredging: I have 25,237 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 636,906,169 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is. - Y-axis doesn't start at zero: I truncated the Y-axes of the graph above. I also used a line graph, which makes the visual connection stand out more than it deserves.
Nothing against line graphs. They are great at telling a story when you have linear data! But visually it is deceptive because the only data is at the points on the graph, not the lines on the graph. In between each point, the data could have been doing anything. Like going for a random walk by itself!
Mathematically what I showed is true, but it is intentionally misleading. Below is the same chart but with both Y-axes starting at zero.

Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([1281,1381,1507,1790,1908,1952,2157,2551,2837,2701,2950,2972,])
array_2 = np.array([82725,58420.1,66085.2,141243,440654,317076,696004,770300,1282840,815816,1346420,1157270,])
array_1_name = "Popularity of the first name Jasper"
array_2_name = "The average number of likes on Mark Rober YouTube videos"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only Popularity of the first name Jasper
- Line chart for only The average number of likes on Mark Rober YouTube videos
- AI-generated correlation image
- The spurious research paper: Jasper-ity Likes Rober: A Quantitative Analysis of the Relationship Between the Name Jasper and Mark Rober YouTube Video Likes
Big thanks for reviewing!
Correlation ID: 5634 · Black Variable ID: 3353 · Red Variable ID: 25567


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}