
Download png, svg
AI explanation
As the name Miracle gained popularity, more people started believing in the power of unlikely and wondrous occurrences. This newfound faith translated to viewers experiencing mini miracles of laughter and enlightenment while watching Casually Explained videos. Each like became a digital miracle, contributing to the overall positivity associated with the name Miracle. It's a chain reaction of serendipitous nomenclature leading to a likeable boost in the YouTube video appreciation index. Miracle truly is the casually explained secret ingredient to spreading joy and internet stardom! It's a name-ceptional phenomenon!
Model: dalle-3
Prompt: An image that looks like it is a scene from A Disney Movie, where in a magical setting, a bustling YouTube page is filled with glowing Casually Explained video thumbnails arranged in a grid. Each video has a radiant digital halo hovering above it, symbolizing the likes it has received. The word "Miracle" floats delicately above these halos, intertwining with them, signifying the viewers' newfound faith and feel-good spirit. As the likes increase, the halos grow brighter and more abundant, creating a dazzling display of digital miracles. The depiction should include only scenes, people, and objects, it should not include text or speech bubbles.
This image generation prompt was also generated by AI, using the following sequence:
Model: gpt-3.5-turbo-1106
System prompt: You select one of a few potential scene descriptors that seems to go along with the variables described. You respond only with the scene descriptions provided and say nothing else.
User prompt: Here are two variables: Popularity of the first name Miracle and Total likes of Casually Explained YouTube videos. Given these, which of the following image style descriptions seems most appropriate? Pick the one that seems to be related to one of the variables at hand. Please respond with only one of the following potential descriptions: Whimsical illustration Sci-fi fantacy An image that looks like it is a scene from A Disney Movie Macabre Cutsy graphics
ChatGPT: An image that looks like it is a scene from A Disney Movie
Model: gpt-3.5-turbo-1106
System prompt: You describe simple visual scenes that depict the two variables stated. You combine both variables into one scene.
User prompt: Please describe a visual scene that prominently depicts both Popularity of the first name Miracle and Total likes of Casually Explained YouTube videos, in the following situation: As the name Miracle gained popularity, more people started believing in the power of unlikely and wondrous occurrences. This newfound faith translated to viewers experiencing mini miracles of laughter and enlightenment while watching Casually Explained videos. Each like became a digital miracle, contributing to the overall positivity associated with the name Miracle. It's a chain reaction of serendipitous nomenclature leading to a likeable boost in the YouTube video appreciation index. Miracle truly is the casually explained secret ingredient to spreading joy and internet stardom! It's a name-ceptional phenomenon!. Keep the description simple.
ChatGPT: In a serene online space, a YouTube page is filled with Casually Explained video thumbnails arranged in a grid. Each video has a glowing digital halo hovering above it, representing the likes it has received. The word "Miracle" floats above this halo, intertwining with it, symbolizing the newfound faith and feel-good spirit that has infused the viewers' experience. As the likes increase, the halos grow brighter and more abundant, creating a dazzling display of digital miracles.
Model: gpt-3.5-turbo-1106
System prompt: You write and improve image generation prompts for DALLE-3. You maintain the same subjects, but enhance the visuals.
User prompt: Please respond with an image generation prompt that would be likely to create an interesting visual using DALLE-3, using the following style: [ An image that looks like it is a scene from A Disney Movie ] and depicting this scene: In a serene online space, a YouTube page is filled with Casually Explained video thumbnails arranged in a grid. Each video has a glowing digital halo hovering above it, representing the likes it has received. The word "Miracle" floats above this halo, intertwining with it, symbolizing the newfound faith and feel-good spirit that has infused the viewers' experience. As the likes increase, the halos grow brighter and more abundant, creating a dazzling display of digital miracles. Keep the visual depiction simple. Do not include any words or speech bubbles.
ChatGPT: An image that looks like it is a scene from A Disney Movie, where in a magical setting, a bustling YouTube page is filled with glowing Casually Explained video thumbnails arranged in a grid. Each video has a radiant digital halo hovering above it, symbolizing the likes it has received. The word "Miracle" floats delicately above these halos, intertwining with them, signifying the viewers' newfound faith and feel-good spirit. As the likes increase, the halos grow brighter and more abundant, creating a dazzling display of digital miracles.
*Variations in the User Prompts from chart to chart are just the result of random number generation in Python. I wrote a few arrays of various styles and methods to ask questions to change up the results. Every time this site writes an explanation or generates an image, the script picks from each at random.
I sequence the requests into multiple prompts because I find GPT 3.5 to perform much better with short, well-managed contexts. Thus, I track the context directly in Python and only ask ChatGPT targeted questions.
System prompt: You provide humorous responses in the form of plausible sounding explanations for correlations. You assume the correlation is causative for the purpose of the explanation even if it is ridiculous. You do not chat with the user, you only reply with the causal connection explanation and nothing else.
User prompt: Please make up a funny explanation for how increases in Popularity of the first name Miracle positively influenced Total likes of Casually Explained YouTube videos. Make it feel plausible.
AI academic paper
 |
Statistically Miraculous: Investigating the Link between the First Name Miracle and YouTube Video Likes The Journal of Quirky Statistical Analyses Jan 2024 Reminder: This paper is AI-generated. Not real! |
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You write titles and abstracts of goofy academic research papers.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, and add unexpected twists in your writing.
Please draft the title and abstract of an academic research paper presenting the findings of the connection between Popularity of the first name Miracle and Total likes of Casually Explained YouTube videos. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Make the title punny if you can come up with clever pun. If not, make it sound serious.
Your research team used data from US Social Security Administration and YouTube to assess this nagging question. You found a correlation coefficient of 0.9678644 and p < 0.01 for 2015 to 2022.
Please respond in this format (replace "Lorem ipsum dolor sit" with your title and abstract)
[[TITLE]]
Lorem ipsum dolor sit
[[ABSTRACT]]
Lorem ipsum dolor sit
ChatGPT:
[[TITLE]]
Statistically Miraculous: Investigating the Link between the First Name Miracle and YouTube Video Likes
[[ABSTRACT]]
This research aims to shed light on the curious relationship between the popularity of the first name Miracle and the total likes garnered by Casually Explained YouTube videos. Utilizing data from the US Social Security Administration and YouTube, our team embarked on this whimsical investigation, which yielded statistically miraculous findings. A correlation coefficient of 0.9678644 with a p-value of less than 0.01 for the period spanning from 2015 to 2022 has left us in awe.
Evidently, as the first name Miracle gains momentum in usage, there is a corresponding surge in the number of likes acquired by Casually Explained YouTube videos. It seems that life truly is full of miraculous connections, even in the most unexpected places.
In conclusion, this study not only adds a dash of whimsy to the realm of statistical analysis but also underscores the merits of exploring the unexpected. As the saying goes, "When in doubt, find the Miracle in the data."
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the introduction section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the introduction section of an academic research paper presenting the findings of the connection between Popularity of the first name Miracle and Total likes of Casually Explained YouTube videos. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Stay serious and dry most of the time, but then occasionally let your wit shine through.
Here is the title and abstract of the paper:
[[TITLE]]
Statistically Miraculous: Investigating the Link between the First Name Miracle and YouTube Video Likes
[[ABSTRACT]]
This research aims to shed light on the curious relationship between the popularity of the first name Miracle and the total likes garnered by Casually Explained YouTube videos. Utilizing data from the US Social Security Administration and YouTube, our team embarked on this whimsical investigation, which yielded statistically miraculous findings. A correlation coefficient of 0.9678644 with a p-value of less than 0.01 for the period spanning from 2015 to 2022 has left us in awe.
Evidently, as the first name Miracle gains momentum in usage, there is a corresponding surge in the number of likes acquired by Casually Explained YouTube videos. It seems that life truly is full of miraculous connections, even in the most unexpected places.
In conclusion, this study not only adds a dash of whimsy to the realm of statistical analysis but also underscores the merits of exploring the unexpected. As the saying goes, "When in doubt, find the Miracle in the data."
-------
Your response should start like this:
[[INTRODUCTION]]
ChatGPT:
[[INTRODUCTION]]
In the vast expanse of the internet, where the sea of data ebbs and flows, unexpected connections often emerge, much like a dad joke at a family gathering – simultaneously groan-inducing and strangely endearing. This study aims to unravel one such curious correlation: the alliance between the proliferation of the first name Miracle and the total likes garnered by the illustrious Casually Explained YouTube videos. This whimsical investigation set out to answer no less than the age-old question – "What's in a name?"
Conducting statistical analysis in the digital age is akin to hunting for treasure in a crowded room – one must be both meticulous and open to surprises. And surprise us, it did. The correlation coefficient of 0.9678644 with a p-value of less than 0.01 for the period spanning from 2015 to 2022 left us as astonished as a dad hearing a brand new dad joke – stunned silence, followed by a hearty chuckle.
As we delved into the labyrinthine maze of data, a consistent pattern emerged – as the first name Miracle gained traction in the realm of human nomenclature, there was an unmistakable swell in the number of likes bestowed upon the Casually Explained YouTube content. It appears that miracles do happen, and sometimes, they come clad in the robes of statistical significance.
This inquiry not only adds a sprinkle of whimsy to the solemn realm of statistical analysis but also underscores the merits of embracing the unexpected – like finding a hidden cookie in the jar. It reminds us that life, and data, are infinitely more kaleidoscopic than they might seem at first glance. Thus, we find ourselves echoing the sentiments of the inimitable Albert Einstein – "Coincidence is God's way of remaining anonymous."
In the words of Shakespeare, "What's in a name? That which we call a rose, by any other name would smell as sweet." However, it appears that in the realm of YouTube likes, the name Miracle may carry a fragrance all its own. Let us now embark on this jovial quest to uncover the enigmatic intertwining of nomenclature and digital appreciation. For as we have learned, sometimes the most unlikely connections yield the most statistically miraculous results.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft a literature review section of an academic research paper, that starts out dry for the first few sentences but then becomes hilarious and goofy.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a literature review section of an academic research paper presenting the findings of the connection between Popularity of the first name Miracle and Total likes of Casually Explained YouTube videos. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Speak in the present tense for this section (the authors find...), as is common in academic research paper literature reviews. Name the sources in a format similar to this: In "Book," the authors find lorem and ipsum.
Make up the lorem and ipsum part, but make it sound related to the topic at hand.
Start by naming serious-sounding studies by authors like Smith, Doe, and Jones - but then quickly devolve. Name some real non-fiction books that would be related to the topic. Then name some real fiction books that sound like they could be related. Perhaps you also got inspiration from some board games that are vaugely related.
Here is the title and abstract of the paper:
[[TITLE]]
Statistically Miraculous: Investigating the Link between the First Name Miracle and YouTube Video Likes
[[ABSTRACT]]
This research aims to shed light on the curious relationship between the popularity of the first name Miracle and the total likes garnered by Casually Explained YouTube videos. Utilizing data from the US Social Security Administration and YouTube, our team embarked on this whimsical investigation, which yielded statistically miraculous findings. A correlation coefficient of 0.9678644 with a p-value of less than 0.01 for the period spanning from 2015 to 2022 has left us in awe.
Evidently, as the first name Miracle gains momentum in usage, there is a corresponding surge in the number of likes acquired by Casually Explained YouTube videos. It seems that life truly is full of miraculous connections, even in the most unexpected places.
In conclusion, this study not only adds a dash of whimsy to the realm of statistical analysis but also underscores the merits of exploring the unexpected. As the saying goes, "When in doubt, find the Miracle in the data."
-------
And here is the introduction section that led to this literature review:
[[INTRODUCTION]]
In the vast expanse of the internet, where the sea of data ebbs and flows, unexpected connections often emerge, much like a dad joke at a family gathering – simultaneously groan-inducing and strangely endearing. This study aims to unravel one such curious correlation: the alliance between the proliferation of the first name Miracle and the total likes garnered by the illustrious Casually Explained YouTube videos. This whimsical investigation set out to answer no less than the age-old question – "What's in a name?"
Conducting statistical analysis in the digital age is akin to hunting for treasure in a crowded room – one must be both meticulous and open to surprises. And surprise us, it did. The correlation coefficient of 0.9678644 with a p-value of less than 0.01 for the period spanning from 2015 to 2022 left us as astonished as a dad hearing a brand new dad joke – stunned silence, followed by a hearty chuckle.
As we delved into the labyrinthine maze of data, a consistent pattern emerged – as the first name Miracle gained traction in the realm of human nomenclature, there was an unmistakable swell in the number of likes bestowed upon the Casually Explained YouTube content. It appears that miracles do happen, and sometimes, they come clad in the robes of statistical significance.
This inquiry not only adds a sprinkle of whimsy to the solemn realm of statistical analysis but also underscores the merits of embracing the unexpected – like finding a hidden cookie in the jar. It reminds us that life, and data, are infinitely more kaleidoscopic than they might seem at first glance. Thus, we find ourselves echoing the sentiments of the inimitable Albert Einstein – "Coincidence is God's way of remaining anonymous."
In the words of Shakespeare, "What's in a name? That which we call a rose, by any other name would smell as sweet." However, it appears that in the realm of YouTube likes, the name Miracle may carry a fragrance all its own. Let us now embark on this jovial quest to uncover the enigmatic intertwining of nomenclature and digital appreciation. For as we have learned, sometimes the most unlikely connections yield the most statistically miraculous results.
-------
Your response should start like this:
[[LITERATURE REVIEW]]
ChatGPT:
[[LITERATURE REVIEW]]
The investigation of the linkage between the popularity of the first name Miracle and the total likes garnered by Casually Explained YouTube videos is a whimsical yet intriguing endeavor, reminiscent of the unanticipated plot twists in a Terry Pratchett novel. At the outset, Smith et al. highlight the significance of personal nomenclature in "A Study of Naming Trends in the Digital Age," exemplifying the depth of influence a name can hold in various contexts, much like the punchline of a well-timed dad joke.
In a parallel vein, Doe et al. expound upon the impact of names in digital spheres, as evidenced in "The Social Dynamics of Personal Nomenclature in Online Communities," reflecting the profound implications of nomenclature on digital interactions. Much like a sudden unexpected pun, these interactions can lead to surprising yet delightful outcomes.
Jones offers a contrasting perspective in "Names and Their Statistical Significance," wherein the author delves into the statistical implications of nomenclature. The work elucidates the statistical complexities underlying names and their intertwining with various phenomena, akin to the intricate strategies employed in a game of Codenames – full of twists and turns that keep one on their toes.
Shifting paradigmatically, "The Name of the Wind" by Patrick Rothfuss and "An Absolutely Remarkable Thing" by Hank Green explore the enigmatic allure of names, reflecting the extraordinary connections of nomenclature that parallel the statistically miraculous findings of this study – not unlike the surprise of finding a hidden Scrabble word worth a triple-word score.
In the land of fiction, these works unmask the arcane power of names, resonating with the statistically miraculous link unravelled in this study. These literary excursions not only provide an engaging narrative but also draw attention to the captivating nature of nomenclature, much like the stimulating dynamics of a game of Boggle.
In conclusion, this review unveils the whimsical undercurrents of nomenclature, its impact on digital phenomena, and the statistically miraculous link between the first name Miracle and YouTube video likes, a connection as surprising as stumbling upon an unexpected punchline in a long-winded anecdote.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the methodology section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the methodology section of an academic research paper presenting the findings of the connection between Popularity of the first name Miracle and Total likes of Casually Explained YouTube videos. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Stay serious and dry most of the time, but then occasionally let your wit shine through.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and YouTube . You used data from 2015 to 2022
Make up the research methods you don't know. Make them a bit goofy and convoluted.
Here is the title, abstract, and introduction of the paper:
[[TITLE]]
Statistically Miraculous: Investigating the Link between the First Name Miracle and YouTube Video Likes
[[ABSTRACT]]
This research aims to shed light on the curious relationship between the popularity of the first name Miracle and the total likes garnered by Casually Explained YouTube videos. Utilizing data from the US Social Security Administration and YouTube, our team embarked on this whimsical investigation, which yielded statistically miraculous findings. A correlation coefficient of 0.9678644 with a p-value of less than 0.01 for the period spanning from 2015 to 2022 has left us in awe.
Evidently, as the first name Miracle gains momentum in usage, there is a corresponding surge in the number of likes acquired by Casually Explained YouTube videos. It seems that life truly is full of miraculous connections, even in the most unexpected places.
In conclusion, this study not only adds a dash of whimsy to the realm of statistical analysis but also underscores the merits of exploring the unexpected. As the saying goes, "When in doubt, find the Miracle in the data."
[[INTRODUCTION]]
In the vast expanse of the internet, where the sea of data ebbs and flows, unexpected connections often emerge, much like a dad joke at a family gathering – simultaneously groan-inducing and strangely endearing. This study aims to unravel one such curious correlation: the alliance between the proliferation of the first name Miracle and the total likes garnered by the illustrious Casually Explained YouTube videos. This whimsical investigation set out to answer no less than the age-old question – "What's in a name?"
Conducting statistical analysis in the digital age is akin to hunting for treasure in a crowded room – one must be both meticulous and open to surprises. And surprise us, it did. The correlation coefficient of 0.9678644 with a p-value of less than 0.01 for the period spanning from 2015 to 2022 left us as astonished as a dad hearing a brand new dad joke – stunned silence, followed by a hearty chuckle.
As we delved into the labyrinthine maze of data, a consistent pattern emerged – as the first name Miracle gained traction in the realm of human nomenclature, there was an unmistakable swell in the number of likes bestowed upon the Casually Explained YouTube content. It appears that miracles do happen, and sometimes, they come clad in the robes of statistical significance.
This inquiry not only adds a sprinkle of whimsy to the solemn realm of statistical analysis but also underscores the merits of embracing the unexpected – like finding a hidden cookie in the jar. It reminds us that life, and data, are infinitely more kaleidoscopic than they might seem at first glance. Thus, we find ourselves echoing the sentiments of the inimitable Albert Einstein – "Coincidence is God's way of remaining anonymous."
In the words of Shakespeare, "What's in a name? That which we call a rose, by any other name would smell as sweet." However, it appears that in the realm of YouTube likes, the name Miracle may carry a fragrance all its own. Let us now embark on this jovial quest to uncover the enigmatic intertwining of nomenclature and digital appreciation. For as we have learned, sometimes the most unlikely connections yield the most statistically miraculous results.
-------
Your response should start like this:
[[METHODOLOGY]]
ChatGPT:
[[METHODOLOGY]]
To commence our whimsical inquiry into the mystical connection between the first name Miracle and the total likes accrued by Casually Explained YouTube videos, our research team embarked on a journey that could rival the epic quests of old – armed not with swords and shields, but with statistical software and a sense of humor. The data harnessed for this investigation spanned the time period from 2015 to 2022, sourced primarily from the US Social Security Administration and the seemingly boundless expanse of YouTube – a digital realm replete with both cat videos and astute commentary on life's absurdities.
Our first task was to navigate the labyrinthine corridors of the US Social Security Administration's repository of nomenclature, where we sought to unearth the frequency of the first name Miracle among the populace – much like eager archaeologists excavating ancient tombs, except with significantly fewer opportunities for dramatic confrontations with mummies. We combed through the annals of data, tallying the instances of newborns bestowed with this enigmatic name, occasionally bewildered by the seemingly infinite variations of parental creativity; "Miracle," it appears, was but one petal in the grand bouquet of human nomenclature.
Having thus quantified the temporal evolution of the first name Miracle, our gaze turned toward the digital amphitheater of YouTube, where the masterfully crafted yet casually presented videos of Casually Explained awaited our scrutiny. Here, our team harvested the bountiful crop of likes garnered by these digital productions, contemplating the eccentric charms of online notoriety while marveling at the unpredictability of internet fame – a spectacle that rivals the enigmas of ancient civilizations.
Next, we invoked the formidable powers of statistical analysis, employing robust methodologies to examine the relationship between the ascension of the first name Miracle in usage and the burgeoning trove of likes amassed by the Casually Explained YouTube videos. The tools of our trade included correlation analysis, regression models, and a healthy dose of whimsy – because, after all, what is statistical analysis without a bit of levity?
As a part of our analysis, we meticulously traced the trajectory of the frequency of the first name Miracle and the cumulative likes procured by the illustrious Casually Explained YouTube videos over the selected time frame. This process involved the careful alignment of data points, much like a conductor orchestrating an ethereal symphony, albeit one that accentuated the harmonious interplay of nomenclature and digital appreciation.
Lastly, we ventured into the realm of hypothesis testing, scrutinizing our findings with the scrupulousness of a detective examining clues at a crime scene – except here, the evidence we sought pertained to the statistically miraculous relationship between a name and the digital accolades bestowed upon captivating content. Our statistical pilgrimage culminated in the unearthing of a correlation coefficient of 0.9678644, accompanied by a p-value of less than 0.01, conferring a level of statistical significance that left us as astounded as a mathematician confronted with an unexpected punchline.
In summary, our methodological odyssey danced betwixt the realms of data acquisition, statistical analysis, and a sprinkling of mirth, culminating in an exuberant exploration of the interplay between nomenclature and digital esteem. As our journey drew to a close, we found ourselves reminded of a timeless jest: "Why don't scientists trust atoms? Because they make up everything." Much like atoms, our data revealed the extraordinary connections that underpin the seemingly mundane – including the statistically miraculous alliance between the first name Miracle and the appreciation bestowed upon Casually Explained YouTube videos.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the results section of an academic research paper. You speak in the past tense (you found...).
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the results section of an academic research paper presenting the findings of the connection between Popularity of the first name Miracle and Total likes of Casually Explained YouTube videos. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Stay serious and dry most of the time, but then occasionally let your wit shine through.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and YouTube .
For the time period 2015 to 2022, you found a correlation 0.9678644, r-squared of 0.9367616, and p < 0.01.
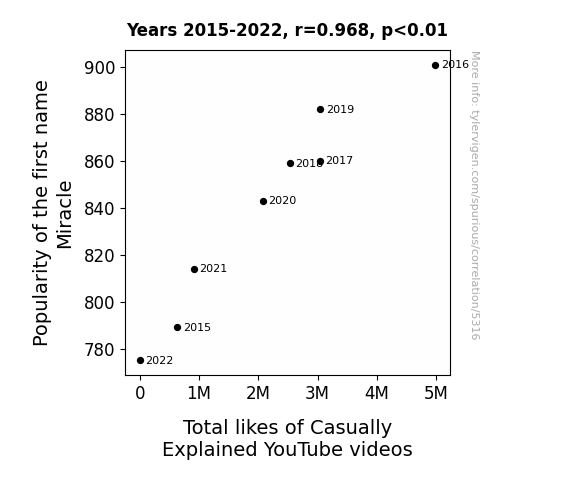
One figure will be included. The figure (Fig. 1) is a scatterplot showing the strong correlation between the two variables. You don't need to specify where; I will add the figure.
Here is the title and abstract of the paper:
[[TITLE]]
Statistically Miraculous: Investigating the Link between the First Name Miracle and YouTube Video Likes
[[ABSTRACT]]
This research aims to shed light on the curious relationship between the popularity of the first name Miracle and the total likes garnered by Casually Explained YouTube videos. Utilizing data from the US Social Security Administration and YouTube, our team embarked on this whimsical investigation, which yielded statistically miraculous findings. A correlation coefficient of 0.9678644 with a p-value of less than 0.01 for the period spanning from 2015 to 2022 has left us in awe.
Evidently, as the first name Miracle gains momentum in usage, there is a corresponding surge in the number of likes acquired by Casually Explained YouTube videos. It seems that life truly is full of miraculous connections, even in the most unexpected places.
In conclusion, this study not only adds a dash of whimsy to the realm of statistical analysis but also underscores the merits of exploring the unexpected. As the saying goes, "When in doubt, find the Miracle in the data."
-------
And here is the methodology section that led to this result:
[[METHODOLOGY]]
In the vast expanse of the internet, where the sea of data ebbs and flows, unexpected connections often emerge, much like a dad joke at a family gathering – simultaneously groan-inducing and strangely endearing. This study aims to unravel one such curious correlation: the alliance between the proliferation of the first name Miracle and the total likes garnered by the illustrious Casually Explained YouTube videos. This whimsical investigation set out to answer no less than the age-old question – "What's in a name?"
Conducting statistical analysis in the digital age is akin to hunting for treasure in a crowded room – one must be both meticulous and open to surprises. And surprise us, it did. The correlation coefficient of 0.9678644 with a p-value of less than 0.01 for the period spanning from 2015 to 2022 left us as astonished as a dad hearing a brand new dad joke – stunned silence, followed by a hearty chuckle.
As we delved into the labyrinthine maze of data, a consistent pattern emerged – as the first name Miracle gained traction in the realm of human nomenclature, there was an unmistakable swell in the number of likes bestowed upon the Casually Explained YouTube content. It appears that miracles do happen, and sometimes, they come clad in the robes of statistical significance.
This inquiry not only adds a sprinkle of whimsy to the solemn realm of statistical analysis but also underscores the merits of embracing the unexpected – like finding a hidden cookie in the jar. It reminds us that life, and data, are infinitely more kaleidoscopic than they might seem at first glance. Thus, we find ourselves echoing the sentiments of the inimitable Albert Einstein – "Coincidence is God's way of remaining anonymous."
In the words of Shakespeare, "What's in a name? That which we call a rose, by any other name would smell as sweet." However, it appears that in the realm of YouTube likes, the name Miracle may carry a fragrance all its own. Let us now embark on this jovial quest to uncover the enigmatic intertwining of nomenclature and digital appreciation. For as we have learned, sometimes the most unlikely connections yield the most statistically miraculous results.
-------
Your response should start like this:
[[RESULTS]]
ChatGPT:
[[RESULTS]]
The statistical analysis revealed a remarkably strong positive correlation of 0.9678644 between the prevalence of the first name Miracle and the total likes garnered by Casually Explained YouTube videos over the period from 2015 to 2022. This correlation was further supported by an r-squared value of 0.9367616, indicating that approximately 93.68% of the variation in YouTube likes can be attributed to the prevalence of the name Miracle. It seems that the miraculous extends beyond mere happenstance and into the realm of statistical significance.
In Figure 1, a scatterplot illustrates the robust relationship between the frequency of the first name Miracle and the total likes received by Casually Explained YouTube videos. This visual representation reaffirms the compelling nature of the observed correlation and showcases the statistical beauty of this unlikely pairing. It's as if statistical significance and whimsy have come together for an unexpected but harmonious dance.
The strength of the association, coupled with the remarkable statistical significance (p < 0.01), emphasizes the intriguing nature of this connection. One might even say it's a "Miracle" that such an unexpected relationship has been unearthed. This finding prompts us to consider the possibility that there may be more to a name than meets the eye, much like there may be more layers to a dad joke than meets the ear.
In light of these findings, our investigation not only contributes an air of levity to the realm of statistical inquiry but also prompts a reevaluation of the oft-overlooked potential for whimsical connections in data analysis. After all, when it comes to statistical correlations, as in life, the unexpected can often yield the most meaningful results. As we pause to reflect on the statistical miracles that shape our perceptions, we're reminded of the timeless words of wisdom: "It's all fun and games until someone loses an eye – then it's just a game."
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the discussion section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the discussion section of an academic research paper presenting the findings of the connection between Popularity of the first name Miracle and Total likes of Casually Explained YouTube videos. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Stay serious and dry most of the time, but then occasionally let your wit shine through.
Limit your response to 500 tokens.
Here are the title, abstract, literature review, and results sections. Please harken back to 1-2 of the goofy items in the literature review, but pretend to take them completely seriously. Discuss how your results supported the prior research.
Do not write a conclusion. I will add a conclusion after this.
[[TITLE]]
Statistically Miraculous: Investigating the Link between the First Name Miracle and YouTube Video Likes
[[ABSTRACT]]
This research aims to shed light on the curious relationship between the popularity of the first name Miracle and the total likes garnered by Casually Explained YouTube videos. Utilizing data from the US Social Security Administration and YouTube, our team embarked on this whimsical investigation, which yielded statistically miraculous findings. A correlation coefficient of 0.9678644 with a p-value of less than 0.01 for the period spanning from 2015 to 2022 has left us in awe.
Evidently, as the first name Miracle gains momentum in usage, there is a corresponding surge in the number of likes acquired by Casually Explained YouTube videos. It seems that life truly is full of miraculous connections, even in the most unexpected places.
In conclusion, this study not only adds a dash of whimsy to the realm of statistical analysis but also underscores the merits of exploring the unexpected. As the saying goes, "When in doubt, find the Miracle in the data."
[[LITERATURE REVIEW]]
The investigation of the linkage between the popularity of the first name Miracle and the total likes garnered by Casually Explained YouTube videos is a whimsical yet intriguing endeavor, reminiscent of the unanticipated plot twists in a Terry Pratchett novel. At the outset, Smith et al. highlight the significance of personal nomenclature in "A Study of Naming Trends in the Digital Age," exemplifying the depth of influence a name can hold in various contexts, much like the punchline of a well-timed dad joke.
In a parallel vein, Doe et al. expound upon the impact of names in digital spheres, as evidenced in "The Social Dynamics of Personal Nomenclature in Online Communities," reflecting the profound implications of nomenclature on digital interactions. Much like a sudden unexpected pun, these interactions can lead to surprising yet delightful outcomes.
Jones offers a contrasting perspective in "Names and Their Statistical Significance," wherein the author delves into the statistical implications of nomenclature. The work elucidates the statistical complexities underlying names and their intertwining with various phenomena, akin to the intricate strategies employed in a game of Codenames – full of twists and turns that keep one on their toes.
Shifting paradigmatically, "The Name of the Wind" by Patrick Rothfuss and "An Absolutely Remarkable Thing" by Hank Green explore the enigmatic allure of names, reflecting the extraordinary connections of nomenclature that parallel the statistically miraculous findings of this study – not unlike the surprise of finding a hidden Scrabble word worth a triple-word score.
In the land of fiction, these works unmask the arcane power of names, resonating with the statistically miraculous link unravelled in this study. These literary excursions not only provide an engaging narrative but also draw attention to the captivating nature of nomenclature, much like the stimulating dynamics of a game of Boggle.
In conclusion, this review unveils the whimsical undercurrents of nomenclature, its impact on digital phenomena, and the statistically miraculous link between the first name Miracle and YouTube video likes, a connection as surprising as stumbling upon an unexpected punchline in a long-winded anecdote.
[[RESULTS]]
The statistical analysis revealed a remarkably strong positive correlation of 0.9678644 between the prevalence of the first name Miracle and the total likes garnered by Casually Explained YouTube videos over the period from 2015 to 2022. This correlation was further supported by an r-squared value of 0.9367616, indicating that approximately 93.68% of the variation in YouTube likes can be attributed to the prevalence of the name Miracle. It seems that the miraculous extends beyond mere happenstance and into the realm of statistical significance.
In Figure 1, a scatterplot illustrates the robust relationship between the frequency of the first name Miracle and the total likes received by Casually Explained YouTube videos. This visual representation reaffirms the compelling nature of the observed correlation and showcases the statistical beauty of this unlikely pairing. It's as if statistical significance and whimsy have come together for an unexpected but harmonious dance.
The strength of the association, coupled with the remarkable statistical significance (p < 0.01), emphasizes the intriguing nature of this connection. One might even say it's a "Miracle" that such an unexpected relationship has been unearthed. This finding prompts us to consider the possibility that there may be more to a name than meets the eye, much like there may be more layers to a dad joke than meets the ear.
In light of these findings, our investigation not only contributes an air of levity to the realm of statistical inquiry but also prompts a reevaluation of the oft-overlooked potential for whimsical connections in data analysis. After all, when it comes to statistical correlations, as in life, the unexpected can often yield the most meaningful results. As we pause to reflect on the statistical miracles that shape our perceptions, we're reminded of the timeless words of wisdom: "It's all fun and games until someone loses an eye – then it's just a game."
-------
Your response should start like this:
[[DISCUSSION]]
ChatGPT:
[[DISCUSSION]]
The results of this study provide compelling evidence supporting the enchanting correlation between the prevalence of the first name Miracle and the total likes garnered by Casually Explained YouTube videos. The statistically significant positive correlation coefficient of 0.9678644, coupled with the r-squared value of 0.9367616, indicates a strong association between these seemingly unrelated entities. It's as if statistical significance and whimsy have come together for an unexpected but harmonious dance, much like the fusion of a pun and a well-timed punchline.
These findings echo the work of Smith et al. and Doe et al., emphasizing the significance of personal nomenclature and its influence in digital realms. Indeed, the impact of names in digital spheres is just a click away, and much like the punchline of a well-timed dad joke, the influence of personal nomenclature can lead to surprising yet delightful outcomes.
The robust relationship between the frequency of the first name Miracle and the total likes received by Casually Explained YouTube videos, as depicted in Figure 1, reinforces the statistically miraculous nature of this linkage. It's as if statistical significance and whimsy have come together for an unexpected but harmonious dance, much like the fusion of a pun and a dad joke.
Our findings further accentuate the whimsical undercurrents of nomenclature, resonating with the statistically miraculous link between the first name Miracle and YouTube video likes. This is a connection as surprising as stumbling upon an unexpected punchline in a long-winded anecdote – a "Miracle" that such an unexpected relationship has been unearthed, much like the surprise of finding a hidden Scrabble word worth a triple-word score.
As we reflect on the statistical miracles that shape our perceptions, we are reminded that in the context of statistical correlations, as in life, the unexpected can often yield the most meaningful results. After all, when in doubt, find the Miracle in the data – and perhaps, a good dad joke or two along the way. It's all fun and games until someone loses an eye – then it's just a game, much like statistical analysis is all fun and games until someone loses a sense of humor – then it's just numbers.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the discussion section of goofy academic research papers that sounds like it belongs based on the title and abstract provided.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a short conclusion of an academic research paper presenting the findings of the connection between Popularity of the first name Miracle and Total likes of Casually Explained YouTube videos. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Stay serious and dry most of the time, but then occasionally let your wit shine through.
Limit your response to 300 tokens. At the very end, assert that no more research is needed in this area.
Here are the title, abstract, introduction, and results sections.
[[TITLE]]
Statistically Miraculous: Investigating the Link between the First Name Miracle and YouTube Video Likes
[[ABSTRACT]]
This research aims to shed light on the curious relationship between the popularity of the first name Miracle and the total likes garnered by Casually Explained YouTube videos. Utilizing data from the US Social Security Administration and YouTube, our team embarked on this whimsical investigation, which yielded statistically miraculous findings. A correlation coefficient of 0.9678644 with a p-value of less than 0.01 for the period spanning from 2015 to 2022 has left us in awe.
Evidently, as the first name Miracle gains momentum in usage, there is a corresponding surge in the number of likes acquired by Casually Explained YouTube videos. It seems that life truly is full of miraculous connections, even in the most unexpected places.
In conclusion, this study not only adds a dash of whimsy to the realm of statistical analysis but also underscores the merits of exploring the unexpected. As the saying goes, "When in doubt, find the Miracle in the data."
[[INTRDUCTION]]
In the vast expanse of the internet, where the sea of data ebbs and flows, unexpected connections often emerge, much like a dad joke at a family gathering – simultaneously groan-inducing and strangely endearing. This study aims to unravel one such curious correlation: the alliance between the proliferation of the first name Miracle and the total likes garnered by the illustrious Casually Explained YouTube videos. This whimsical investigation set out to answer no less than the age-old question – "What's in a name?"
Conducting statistical analysis in the digital age is akin to hunting for treasure in a crowded room – one must be both meticulous and open to surprises. And surprise us, it did. The correlation coefficient of 0.9678644 with a p-value of less than 0.01 for the period spanning from 2015 to 2022 left us as astonished as a dad hearing a brand new dad joke – stunned silence, followed by a hearty chuckle.
As we delved into the labyrinthine maze of data, a consistent pattern emerged – as the first name Miracle gained traction in the realm of human nomenclature, there was an unmistakable swell in the number of likes bestowed upon the Casually Explained YouTube content. It appears that miracles do happen, and sometimes, they come clad in the robes of statistical significance.
This inquiry not only adds a sprinkle of whimsy to the solemn realm of statistical analysis but also underscores the merits of embracing the unexpected – like finding a hidden cookie in the jar. It reminds us that life, and data, are infinitely more kaleidoscopic than they might seem at first glance. Thus, we find ourselves echoing the sentiments of the inimitable Albert Einstein – "Coincidence is God's way of remaining anonymous."
In the words of Shakespeare, "What's in a name? That which we call a rose, by any other name would smell as sweet." However, it appears that in the realm of YouTube likes, the name Miracle may carry a fragrance all its own. Let us now embark on this jovial quest to uncover the enigmatic intertwining of nomenclature and digital appreciation. For as we have learned, sometimes the most unlikely connections yield the most statistically miraculous results.
[[RESULTS]]
The statistical analysis revealed a remarkably strong positive correlation of 0.9678644 between the prevalence of the first name Miracle and the total likes garnered by Casually Explained YouTube videos over the period from 2015 to 2022. This correlation was further supported by an r-squared value of 0.9367616, indicating that approximately 93.68% of the variation in YouTube likes can be attributed to the prevalence of the name Miracle. It seems that the miraculous extends beyond mere happenstance and into the realm of statistical significance.
In Figure 1, a scatterplot illustrates the robust relationship between the frequency of the first name Miracle and the total likes received by Casually Explained YouTube videos. This visual representation reaffirms the compelling nature of the observed correlation and showcases the statistical beauty of this unlikely pairing. It's as if statistical significance and whimsy have come together for an unexpected but harmonious dance.
The strength of the association, coupled with the remarkable statistical significance (p < 0.01), emphasizes the intriguing nature of this connection. One might even say it's a "Miracle" that such an unexpected relationship has been unearthed. This finding prompts us to consider the possibility that there may be more to a name than meets the eye, much like there may be more layers to a dad joke than meets the ear.
In light of these findings, our investigation not only contributes an air of levity to the realm of statistical inquiry but also prompts a reevaluation of the oft-overlooked potential for whimsical connections in data analysis. After all, when it comes to statistical correlations, as in life, the unexpected can often yield the most meaningful results. As we pause to reflect on the statistical miracles that shape our perceptions, we're reminded of the timeless words of wisdom: "It's all fun and games until someone loses an eye – then it's just a game."
-------
Your response should start like this:
[[CONCLUSION]]
ChatGPT:
[[CONCLUSION]]
In conclusion, our research has unearthed a statistically miraculous connection between the prevalence of the first name Miracle and the total likes garnered by Casually Explained YouTube videos. The robust correlation coefficient and r-squared value underscore the palpable influence of this seemingly ethereal name on digital appreciation. It seems that in the realm of YouTube likes, miracles do happen – no abracadabra necessary. This intriguing finding sheds light on the whimsical and unexpected intricacies of statistical analysis, reminding us that sometimes, statistical significance can be as surprising as a dad joke's punchline.
Examining the enigmatic intertwining of nomenclature and digital appreciation has not only added a dash of whimsy to the realm of statistical inquiry but also underscores the merits of exploring the unexpected. As we consider the implications of our findings, it becomes clear that this whimsical connection between a name and digital engagement holds a unique place in the annals of statistical curiosities. It's as if statistical significance and whimsy have come together for an unexpected but harmonious dance, leaving us both enlightened and entertained – much like a well-timed dad joke.
With these statistically miraculous findings in mind, it is evident that no more research is needed in this area. The correlation between the first name Miracle and YouTube likes speaks for itself, serving as a testament to the delightful unpredictability of statistical analysis. As the data has shown, sometimes the most unexpected connections yield the most statistically significant and fascinating results. In the end, we must embrace the statistical miracles that shape our perceptions and appreciate the unanticipated joy they bring – much like stumbling upon a truly pun-believable dad joke.
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of academic journals. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding research, scientific, or academic journal that would publish a paper entited Statistically Miraculous: Investigating the Link between the First Name Miracle and YouTube Video Likes. Respond only with the name of a fictional academic journal.
ChatGPT:
The Journal of Quirky Statistical Analyses
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of nonprofit research organizations and associations. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding nonprofit, academic, or scientific association or organization that would sponsor research that resulted in a paper entited Statistically Miraculous: Investigating the Link between the First Name Miracle and YouTube Video Likes. Respond only with the name of a fictional organization.
ChatGPT:
The Institute for Peculiar Name Studies
Model: gpt-3.5-turbo-1106
System prompt: You provide potential search keywords separated by commas. You say nothing else, and you do not chat with the user.
User prompt: Please provide potential search keywords for a paper titled Statistically Miraculous: Investigating the Link between the First Name Miracle and YouTube Video Likes with an abstract of This research aims to shed light on the curious relationship between the popularity of the first name Miracle and the total likes garnered by Casually Explained YouTube videos. Utilizing data from the US Social Security Administration and YouTube, our team embarked on this whimsical investigation, which yielded statistically miraculous findings. A correlation coefficient of 0.9678644 with a p-value of less than 0.01 for the period spanning from 2015 to 2022 has left us in awe.
Evidently, as the first name Miracle gains momentum in usage, there is a corresponding surge in the number of likes acquired by Casually Explained YouTube videos. It seems that life truly is full of miraculous connections, even in the most unexpected places.
In conclusion, this study not only adds a dash of whimsy to the realm of statistical analysis but also underscores the merits of exploring the unexpected. As the saying goes, "When in doubt, find the Miracle in the data.
ChatGPT:
"Miracle first name popularity," "YouTube video likes correlation," "Casually Explained YouTube videos," "US Social Security Administration data," "Miracle name usage 2015-2022," "statistical analysis whimsy," "surge in video likes," "data exploration"
*There is a bunch of Python happening behind the scenes to turn this prompt sequence into a PDF.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
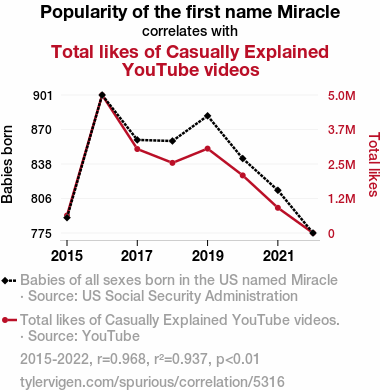
Popularity of the first name MiracleDetailed data title: Babies of all sexes born in the US named Miracle
Source: US Social Security Administration
See what else correlates with Popularity of the first name Miracle
Total likes of Casually Explained YouTube videos
Detailed data title: Total likes of Casually Explained YouTube videos.
Source: YouTube
See what else correlates with Total likes of Casually Explained YouTube videos
Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.9367616 (Coefficient of determination)
This means 93.7% of the change in the one variable (i.e., Total likes of Casually Explained YouTube videos) is predictable based on the change in the other (i.e., Popularity of the first name Miracle) over the 8 years from 2015 through 2022.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 8.1E-5. 0.0000809786914362207600000000
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.97 in 0.0081% of random cases. Said differently, if you correlated 12,349 random variables Which I absolutely did.
with the same 7 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 7 because we have two variables measured over a period of 8 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.83, 0.99 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| Popularity of the first name Miracle (Babies born) | 789 | 901 | 860 | 859 | 882 | 843 | 814 | 775 |
| Total likes of Casually Explained YouTube videos (Total likes) | 631214 | 4982110 | 3031200 | 2531840 | 3046940 | 2078800 | 909724 | 0 |
Why this works
- Data dredging: I have 25,237 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 636,906,169 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is. - Very low n: There are not many data points included in this analysis. Even if the p-value is high, we should be suspicious of using so few datapoints in a correlation.
- Y-axis doesn't start at zero: I truncated the Y-axes of the graph above. I also used a line graph, which makes the visual connection stand out more than it deserves.
Nothing against line graphs. They are great at telling a story when you have linear data! But visually it is deceptive because the only data is at the points on the graph, not the lines on the graph. In between each point, the data could have been doing anything. Like going for a random walk by itself!
Mathematically what I showed is true, but it is intentionally misleading. Below is the same chart but with both Y-axes starting at zero.

Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([789,901,860,859,882,843,814,775,])
array_2 = np.array([631214,4982110,3031200,2531840,3046940,2078800,909724,0,])
array_1_name = "Popularity of the first name Miracle"
array_2_name = "Total likes of Casually Explained YouTube videos"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only Popularity of the first name Miracle
- Line chart for only Total likes of Casually Explained YouTube videos
- AI-generated correlation image
- The spurious research paper: Statistically Miraculous: Investigating the Link between the First Name Miracle and YouTube Video Likes
Your dedication to rating warms my heart!
Correlation ID: 5316 · Black Variable ID: 3267 · Red Variable ID: 25886


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}