
Download png, svg
AI explanation
As the popularity of the name Jaylen grew, so did the demand for customized "J" car decals. This led to a sudden spike in car sticker production in Madison, Wisconsin, ultimately contributing to air pollution as factories cranked out the trendy J-themed accessories. Who knew that a linguistic preference could have such an unforeseen impact on the local atmosphere!
Model: dalle-3
Prompt: Generate a photo-realistic image of a bustling street in Madison, Wisconsin, with cars jam-packed and each bearing vibrant "J" car decals. The air is heavy with industrial smoke as factories churn out the popular stickers, creating an atmospheric scene of pollution. The name Jaylen has evidently spurred a trend, causing a surge in air pollution due to the growing demand for customized decals. The depiction should include only scenes, people, and objects, it should not include text or speech bubbles.
This image generation prompt was also generated by AI, using the following sequence:
Model: gpt-3.5-turbo-1106
System prompt: You select one of a few potential scene descriptors that seems to go along with the variables described. You respond only with the scene descriptions provided and say nothing else.
User prompt: Here are two variables: Popularity of the first name Jaylen and Air pollution in Madison, Wisconsin. Given these, which of the following image style descriptions seems most appropriate? Pick the one that seems to be related to one of the variables at hand. Please respond with only one of the following potential descriptions: A photo-realistic image Oragami Hyper-realistic Oragami inspired by bauhaus
ChatGPT: A photo-realistic image
Model: gpt-3.5-turbo-1106
System prompt: You describe simple visual scenes that depict the two variables stated. You combine both variables into one scene.
User prompt: Please describe a visual scene that prominently depicts both Popularity of the first name Jaylen and Air pollution in Madison, Wisconsin, in the following situation: As the popularity of the name Jaylen grew, so did the demand for customized "J" car decals. This led to a sudden spike in car sticker production in Madison, Wisconsin, ultimately contributing to air pollution as factories cranked out the trendy J-themed accessories. Who knew that a linguistic preference could have such an unforeseen impact on the local atmosphere!. Keep the description simple.
ChatGPT: A bustling street in Madison, Wisconsin is crowded with cars, each adorned with vibrant "J" car decals. The air is hazy with industrial smoke as factories work tirelessly to produce the popular stickers. The name Jaylen has clearly sparked a trend, leading to a surge in air pollution as demand for customized decals grows.
Model: gpt-3.5-turbo-1106
System prompt: You write and improve image generation prompts for DALLE-3. You maintain the same subjects, but enhance the visuals.
User prompt: Please respond with an image generation prompt that would be likely to create an interesting visual using DALLE-3, using the following style: [ A photo-realistic image ] and depicting this scene: A bustling street in Madison, Wisconsin is crowded with cars, each adorned with vibrant "J" car decals. The air is hazy with industrial smoke as factories work tirelessly to produce the popular stickers. The name Jaylen has clearly sparked a trend, leading to a surge in air pollution as demand for customized decals grows. Keep the visual depiction simple. Do not include any words or speech bubbles.
ChatGPT: Generate a photo-realistic image of a bustling street in Madison, Wisconsin, with cars jam-packed and each bearing vibrant "J" car decals. The air is heavy with industrial smoke as factories churn out the popular stickers, creating an atmospheric scene of pollution. The name Jaylen has evidently spurred a trend, causing a surge in air pollution due to the growing demand for customized decals.
*Variations in the User Prompts from chart to chart are just the result of random number generation in Python. I wrote a few arrays of various styles and methods to ask questions to change up the results. Every time this site writes an explanation or generates an image, the script picks from each at random.
I sequence the requests into multiple prompts because I find GPT 3.5 to perform much better with short, well-managed contexts. Thus, I track the context directly in Python and only ask ChatGPT targeted questions.
System prompt: You provide humorous responses in the form of plausible sounding explanations for correlations. You assume the correlation is causative for the purpose of the explanation even if it is ridiculous. You do not chat with the user, you only reply with the causal connection explanation and nothing else.
User prompt: Please make up a funny explanation for how an increase in Popularity of the first name Jaylen caused Air pollution in Madison, Wisconsin to increase.
AI academic paper
 |
The Jaylen Effect: A Breath of Fresh Air or Just Hot Air? The International Journal of Atmospheric Anomalies Jan 2024 Reminder: This paper is AI-generated. Not real! |
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You write titles and abstracts of goofy academic research papers.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, and add unexpected twists in your writing.
Please draft the title and abstract of an academic research paper presenting the findings of the connection between Popularity of the first name Jaylen and Air pollution in Madison, Wisconsin. Make lots of jokes, goofy observations, and puns.
Make the title punny if you can come up with clever pun. If not, make it sound serious.
Your research team used data from US Social Security Administration and Environmental Protection Agency to assess this nagging question. You found a correlation coefficient of 0.8121277 and p < 0.01 for 1991 to 2022.
Please respond in this format (replace "Lorem ipsum dolor sit" with your title and abstract)
[[TITLE]]
Lorem ipsum dolor sit
[[ABSTRACT]]
Lorem ipsum dolor sit
ChatGPT:
[[TITLE]]
The Jaylen Effect: A Breath of Fresh Air or Just Hot Air?
[[ABSTRACT]]
This research delves into the curious relationship between the popularity of the first name Jaylen and air pollution levels in Madison, Wisconsin. Leveraging data from the US Social Security Administration and the Environmental Protection Agency, our study presents an intriguing exploration of the correlation between the two seemingly unrelated variables. With a correlation coefficient of 0.8121277 and a p-value of less than 0.01 for the years 1991 to 2022, the findings highlight a unexpectedly strong association. Our analysis provides fresh insights into the potential impacts of naming trends on environmental factors and offers an amusing twist to the realm of statistical inquiry. We welcome readers to join us in bringing a breath of whimsy to the typically serious fields of social sciences and environmental research.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the introduction section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the introduction section of an academic research paper presenting the findings of the connection between Popularity of the first name Jaylen and Air pollution in Madison, Wisconsin. Make lots of jokes, goofy observations, and puns.
Here is the title and abstract of the paper:
[[TITLE]]
The Jaylen Effect: A Breath of Fresh Air or Just Hot Air?
[[ABSTRACT]]
This research delves into the curious relationship between the popularity of the first name Jaylen and air pollution levels in Madison, Wisconsin. Leveraging data from the US Social Security Administration and the Environmental Protection Agency, our study presents an intriguing exploration of the correlation between the two seemingly unrelated variables. With a correlation coefficient of 0.8121277 and a p-value of less than 0.01 for the years 1991 to 2022, the findings highlight a unexpectedly strong association. Our analysis provides fresh insights into the potential impacts of naming trends on environmental factors and offers an amusing twist to the realm of statistical inquiry. We welcome readers to join us in bringing a breath of whimsy to the typically serious fields of social sciences and environmental research.
-------
Your response should start like this:
[[INTRODUCTION]]
ChatGPT:
Introducing the Jaylen Effect: The Air We Breathe and the Name We Cheer
As we take a deep breath and dive into the realm of curious correlations and whimsical wonders, we aim to unravel the mysterious relationship between the popularity of the first name Jaylen and the air pollution levels in the vibrant city of Madison, Wisconsin. What prompts us to explore such an offbeat association, you ask? Well, it all started with a whimsical conversation at the water cooler about the intriguing nature of statistical anomalies. We couldn't help but wonder if there lay a gust of fresh insight in the gusts of air pollution, and that's where our journey began.
Now, you might be thinking, "What in the world does a name have to do with the quality of the air we breathe?" Trust us, we were just as befuddled. But it turns out that statistical surprises can be as unpredictable as a breeze on a summer day. Armed with data from the US Social Security Administration and the Environmental Protection Agency, we ventured into this enigmatic terrain of statistical curiosity with equal parts scientific inquiry and playful curiosity.
As we embark on this oddly delightful odyssey, picture this: the bustling streets of Madison, where Wisconsinites go about their daily routines, and the unmistakable tang of cheese curds mingles with the purr of bicycles and the hum of industrious activity. In the midst of this intriguing tapestry of Midwestern life, there lies a peculiar connection between the ebb and flow of air quality and the ebb and flow of a name - Jaylen.
So, join us as we uncover the windings and meanderings of this unlikely correlation and breathe in the lighthearted exploration that promises to add a breeze of mirth to the usually staid world of social sciences and environmental research. After all, who said academic pursuits can't have a splash of levity and a breath of fresh air?
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft a literature review section of an academic research paper, that starts out dry for the first few sentences but then becomes hilarious and goofy.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a literature review section of an academic research paper presenting the findings of the connection between Popularity of the first name Jaylen and Air pollution in Madison, Wisconsin. Make lots of jokes, goofy observations, and puns.
Speak in the present tense for this section (the authors find...), as is common in academic research paper literature reviews. Name the sources in a format similar to this: In "Book," the authors find lorem and ipsum.
Make up the lorem and ipsum part, but make it sound related to the topic at hand.
Start by naming serious-sounding studies by authors like Smith, Doe, and Jones - but then quickly devolve. Name some real non-fiction books that would be related to the topic. Then name some real fiction books that sound like they could be related. Then you might move on to cartoons and children's shows that you watched for research.
Here is the title and abstract of the paper:
[[TITLE]]
The Jaylen Effect: A Breath of Fresh Air or Just Hot Air?
[[ABSTRACT]]
This research delves into the curious relationship between the popularity of the first name Jaylen and air pollution levels in Madison, Wisconsin. Leveraging data from the US Social Security Administration and the Environmental Protection Agency, our study presents an intriguing exploration of the correlation between the two seemingly unrelated variables. With a correlation coefficient of 0.8121277 and a p-value of less than 0.01 for the years 1991 to 2022, the findings highlight a unexpectedly strong association. Our analysis provides fresh insights into the potential impacts of naming trends on environmental factors and offers an amusing twist to the realm of statistical inquiry. We welcome readers to join us in bringing a breath of whimsy to the typically serious fields of social sciences and environmental research.
-------
And here is the introduction section that led to this literature review:
[[INTRODUCTION]]
Introducing the Jaylen Effect: The Air We Breathe and the Name We Cheer
As we take a deep breath and dive into the realm of curious correlations and whimsical wonders, we aim to unravel the mysterious relationship between the popularity of the first name Jaylen and the air pollution levels in the vibrant city of Madison, Wisconsin. What prompts us to explore such an offbeat association, you ask? Well, it all started with a whimsical conversation at the water cooler about the intriguing nature of statistical anomalies. We couldn't help but wonder if there lay a gust of fresh insight in the gusts of air pollution, and that's where our journey began.
Now, you might be thinking, "What in the world does a name have to do with the quality of the air we breathe?" Trust us, we were just as befuddled. But it turns out that statistical surprises can be as unpredictable as a breeze on a summer day. Armed with data from the US Social Security Administration and the Environmental Protection Agency, we ventured into this enigmatic terrain of statistical curiosity with equal parts scientific inquiry and playful curiosity.
As we embark on this oddly delightful odyssey, picture this: the bustling streets of Madison, where Wisconsinites go about their daily routines, and the unmistakable tang of cheese curds mingles with the purr of bicycles and the hum of industrious activity. In the midst of this intriguing tapestry of Midwestern life, there lies a peculiar connection between the ebb and flow of air quality and the ebb and flow of a name - Jaylen.
So, join us as we uncover the windings and meanderings of this unlikely correlation and breathe in the lighthearted exploration that promises to add a breeze of mirth to the usually staid world of social sciences and environmental research. After all, who said academic pursuits can't have a splash of levity and a breath of fresh air?
-------
Your response should start like this:
[[LITERATURE REVIEW]]
ChatGPT:
[[LITERATURE REVIEW]]
In their study, Smith et al. (2015) examine the impact of first name popularity on environmental determinants, laying the groundwork for our investigation into the Jaylen Effect. Their findings reveal a surprising connection between naming trends and ecological variables, sparking curiosity about the potential influence of monikers on atmospheric conditions. Adding to this intriguing discourse, Doe and Jones (2018) explore the societal implications of distinctive names, albeit without direct reference to air quality. Nevertheless, their research broadens the scope of our inquiry, encouraging us to consider the broader ramifications of nomenclature.
Turning to the realm of non-fiction literature, "The Air We Breathe: A History of Atmospheric Conditions" by Brown (2017) provides a comprehensive overview of the factors shaping air quality, offering a contextual backdrop for our study. Similarly, "Names and Nature: An Unlikely Link" by Green (2020) presents an examination of the cultural significance of names, proposing potential connections to environmental phenomena.
In the realm of fiction, "A Breath of Fresh Names" by Black (2019) introduces a whimsical narrative exploring the whimsical influence of names on the natural world. While purely imaginative, these fictional works offer an entertaining perspective on the interplay between nomenclature and environmental circumstances.
Venturing into unexpected territory, we draw insights from popular culture, including the animated series "Airbenders and the Essence of Jaylen" and the children's show "Jaylen's Whimsical Wind Expedition." Though seemingly lighthearted, these media sources prompt reflection on the potential interconnections between names and environmental elements, leading us to embrace a playful approach in our exploration of the Jaylen Effect.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the methodology section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the methodology section of an academic research paper presenting the findings of the connection between Popularity of the first name Jaylen and Air pollution in Madison, Wisconsin. Make lots of jokes, goofy observations, and puns.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Environmental Protection Agency . You used data from 1991 to 2022
Make up the research methods you don't know. Make them a bit goofy and convoluted.
Here is the title, abstract, and introduction of the paper:
[[TITLE]]
The Jaylen Effect: A Breath of Fresh Air or Just Hot Air?
[[ABSTRACT]]
This research delves into the curious relationship between the popularity of the first name Jaylen and air pollution levels in Madison, Wisconsin. Leveraging data from the US Social Security Administration and the Environmental Protection Agency, our study presents an intriguing exploration of the correlation between the two seemingly unrelated variables. With a correlation coefficient of 0.8121277 and a p-value of less than 0.01 for the years 1991 to 2022, the findings highlight a unexpectedly strong association. Our analysis provides fresh insights into the potential impacts of naming trends on environmental factors and offers an amusing twist to the realm of statistical inquiry. We welcome readers to join us in bringing a breath of whimsy to the typically serious fields of social sciences and environmental research.
[[INTRODUCTION]]
Introducing the Jaylen Effect: The Air We Breathe and the Name We Cheer
As we take a deep breath and dive into the realm of curious correlations and whimsical wonders, we aim to unravel the mysterious relationship between the popularity of the first name Jaylen and the air pollution levels in the vibrant city of Madison, Wisconsin. What prompts us to explore such an offbeat association, you ask? Well, it all started with a whimsical conversation at the water cooler about the intriguing nature of statistical anomalies. We couldn't help but wonder if there lay a gust of fresh insight in the gusts of air pollution, and that's where our journey began.
Now, you might be thinking, "What in the world does a name have to do with the quality of the air we breathe?" Trust us, we were just as befuddled. But it turns out that statistical surprises can be as unpredictable as a breeze on a summer day. Armed with data from the US Social Security Administration and the Environmental Protection Agency, we ventured into this enigmatic terrain of statistical curiosity with equal parts scientific inquiry and playful curiosity.
As we embark on this oddly delightful odyssey, picture this: the bustling streets of Madison, where Wisconsinites go about their daily routines, and the unmistakable tang of cheese curds mingles with the purr of bicycles and the hum of industrious activity. In the midst of this intriguing tapestry of Midwestern life, there lies a peculiar connection between the ebb and flow of air quality and the ebb and flow of a name - Jaylen.
So, join us as we uncover the windings and meanderings of this unlikely correlation and breathe in the lighthearted exploration that promises to add a breeze of mirth to the usually staid world of social sciences and environmental research. After all, who said academic pursuits can't have a splash of levity and a breath of fresh air?
-------
Your response should start like this:
[[METHODOLOGY]]
ChatGPT:
[[METHODOLOGY]]
To unravel the whimsical conundrum of the Jaylen Effect and its potential impact on air pollution in Madison, Wisconsin, we employed a rather eclectic mix of research methods that could be described as a fusion of statistical analysis and a dash of name-ology.
Firstly, we delved into the vast archives of the US Social Security Administration, where we sought to trace the popularity of the name Jaylen in Madison, Wisconsin, from 1991 to 2022. This involved sifting through an immense pile of data, akin to searching for a needle in a haystack, to discern the yearly trends in the choice of this particular moniker. It was a journey reminiscent of panning for gold in a digital river of names, and, as it turns out, there was indeed treasure to be found – not in the form of gold nuggets, but in the form of statistical nuggets.
Next, we turned our attention to the intricate dance of air pollution data, courtesy of the Environmental Protection Agency. This endeavor felt akin to navigating through a maze of regulatory jargon and emission statistics to extract the essence of Madison's atmospheric quality. We then wrangled with the atmospheric chemistry and meteorological measurements to capture the ebbs and flows of the city's air pollution levels over the same time period. It was a bit like trying to grasp the ever-shifting winds of statistical fortune, and we can assure you that it was no mean feat – but definitely worth the pursuit.
With our arsenal of data at the ready, we then took a dabble into the realm of statistical analysis, where we concocted a series of mesmerizing mathematical algorithms to unearth the potential correlations between the rise and fall of Jaylens and the ebb and flow of air pollution. This involved leveraging correlation analyses, regression models, and other statistical legerdemain to reveal the hidden threads of connection between the name game and the atmospheric fame.
In addition, we utilized a range of supplementary analyses to add layers of depth to our investigation. These included geographical mapping of name popularity and air pollution hotspots, time series analyses to capture the temporal nuances of our data, and even a touch of whimsy-infused storytelling to breathe life into the numerical tapestry we've woven.
Finally, we sprinkled a figurative dash of fairy dust by incorporating some light-hearted qualitative insights to enrich our quantitative findings. This involved engaging in discussions with local denizens to capture the zeitgeist of naming practices and the breathing experiences in Madison. It was akin to embarking on a qualitative quest to uncover the anecdotes and musings that added a sprinkle of human flavor to our numerical recipe.
In sum, our methodology was a delightful medley of data spelunking, statistical wizardry, and qualitative whimsy, all in the pursuit of unraveling the enigma of the Jaylen Effect and the air we breathe in Madison, Wisconsin.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the results section of an academic research paper. You speak in the past tense (you found...).
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the results section of an academic research paper presenting the findings of the connection between Popularity of the first name Jaylen and Air pollution in Madison, Wisconsin. Make lots of jokes, goofy observations, and puns.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Environmental Protection Agency .
For the time period 1991 to 2022, you found a correlation 0.8121277, r-squared of 0.6595514, and p < 0.01.
One figure will be included. The figure (Fig. 1) is a scatterplot showing the strong correlation between the two variables. You don't need to specify where; I will add the figure.
Here is the title and abstract of the paper:
[[TITLE]]
The Jaylen Effect: A Breath of Fresh Air or Just Hot Air?
[[ABSTRACT]]
This research delves into the curious relationship between the popularity of the first name Jaylen and air pollution levels in Madison, Wisconsin. Leveraging data from the US Social Security Administration and the Environmental Protection Agency, our study presents an intriguing exploration of the correlation between the two seemingly unrelated variables. With a correlation coefficient of 0.8121277 and a p-value of less than 0.01 for the years 1991 to 2022, the findings highlight a unexpectedly strong association. Our analysis provides fresh insights into the potential impacts of naming trends on environmental factors and offers an amusing twist to the realm of statistical inquiry. We welcome readers to join us in bringing a breath of whimsy to the typically serious fields of social sciences and environmental research.
-------
And here is the methodology section that led to this result:
[[METHODOLOGY]]
Introducing the Jaylen Effect: The Air We Breathe and the Name We Cheer
As we take a deep breath and dive into the realm of curious correlations and whimsical wonders, we aim to unravel the mysterious relationship between the popularity of the first name Jaylen and the air pollution levels in the vibrant city of Madison, Wisconsin. What prompts us to explore such an offbeat association, you ask? Well, it all started with a whimsical conversation at the water cooler about the intriguing nature of statistical anomalies. We couldn't help but wonder if there lay a gust of fresh insight in the gusts of air pollution, and that's where our journey began.
Now, you might be thinking, "What in the world does a name have to do with the quality of the air we breathe?" Trust us, we were just as befuddled. But it turns out that statistical surprises can be as unpredictable as a breeze on a summer day. Armed with data from the US Social Security Administration and the Environmental Protection Agency, we ventured into this enigmatic terrain of statistical curiosity with equal parts scientific inquiry and playful curiosity.
As we embark on this oddly delightful odyssey, picture this: the bustling streets of Madison, where Wisconsinites go about their daily routines, and the unmistakable tang of cheese curds mingles with the purr of bicycles and the hum of industrious activity. In the midst of this intriguing tapestry of Midwestern life, there lies a peculiar connection between the ebb and flow of air quality and the ebb and flow of a name - Jaylen.
So, join us as we uncover the windings and meanderings of this unlikely correlation and breathe in the lighthearted exploration that promises to add a breeze of mirth to the usually staid world of social sciences and environmental research. After all, who said academic pursuits can't have a splash of levity and a breath of fresh air?
-------
Your response should start like this:
[[RESULTS]]
ChatGPT:
[[RESULTS]]
The statistical analysis of the relationship between the popularity of the first name Jaylen and air pollution levels in Madison, Wisconsin yielded some truly unexpected and, dare we say, breathtaking findings. Our research unearthed a striking correlation coefficient of 0.8121277, with an r-squared value of 0.6595514 and a p-value of less than 0.01 for the years 1991 to 2022. These results certainly blew us away, leaving us with a rush of statistical excitement akin to chasing after a wayward umbrella in a gust of wind.
Fig. 1 illustrates this captivating correlation with a scatterplot that visibly showcases the strong connection between the two variables. One might even say that this correlation is as clear as the crisp Wisconsin air after a refreshing rain shower!
This unexpected connection beckons us to ponder whether there might be unseen forces at play, with the ebb and flow of air pollution levels inexplicably tied to the ebb and flow of the popularity of the name Jaylen. As we carefully navigated through the statistical underbrush of our data, it became evident that this correlation isn't just a mere statistical blip on the radar.
The Jaylen Effect appears to blow through the usually staid landscape of social sciences and environmental research like a playful zephyr, leaving us with a whimsical twist and an unexpected chuckle. It seems that the winds of statistical inquiry can lead us to truly unexpected and lighthearted findings, shaking up our preconceived notions and sweeping us into a whirlwind of statistical amusement.
In conclusion, our findings suggest that there may indeed be a gust of fresh insight waiting to be discovered in the most surprising of places, and we invite fellow researchers to join us in this breezy, quirky journey of statistical exploration. After all, a little statistical whimsy might just be the breath of fresh air that the academic world needs!
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the discussion section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the discussion section of an academic research paper presenting the findings of the connection between Popularity of the first name Jaylen and Air pollution in Madison, Wisconsin. Make lots of jokes, goofy observations, and puns.
Limit your response to 500 tokens.
Here are the title, abstract, literature review, and results sections. Please harken back to 1-2 of the goofy items in the literature review, but pretend to take them completely seriously. Discuss how your results supported the prior research.
Do not write a conclusion. I will add a conclusion after this.
[[TITLE]]
The Jaylen Effect: A Breath of Fresh Air or Just Hot Air?
[[ABSTRACT]]
This research delves into the curious relationship between the popularity of the first name Jaylen and air pollution levels in Madison, Wisconsin. Leveraging data from the US Social Security Administration and the Environmental Protection Agency, our study presents an intriguing exploration of the correlation between the two seemingly unrelated variables. With a correlation coefficient of 0.8121277 and a p-value of less than 0.01 for the years 1991 to 2022, the findings highlight a unexpectedly strong association. Our analysis provides fresh insights into the potential impacts of naming trends on environmental factors and offers an amusing twist to the realm of statistical inquiry. We welcome readers to join us in bringing a breath of whimsy to the typically serious fields of social sciences and environmental research.
[[LITERATURE REVIEW]]
In their study, Smith et al. (2015) examine the impact of first name popularity on environmental determinants, laying the groundwork for our investigation into the Jaylen Effect. Their findings reveal a surprising connection between naming trends and ecological variables, sparking curiosity about the potential influence of monikers on atmospheric conditions. Adding to this intriguing discourse, Doe and Jones (2018) explore the societal implications of distinctive names, albeit without direct reference to air quality. Nevertheless, their research broadens the scope of our inquiry, encouraging us to consider the broader ramifications of nomenclature.
Turning to the realm of non-fiction literature, "The Air We Breathe: A History of Atmospheric Conditions" by Brown (2017) provides a comprehensive overview of the factors shaping air quality, offering a contextual backdrop for our study. Similarly, "Names and Nature: An Unlikely Link" by Green (2020) presents an examination of the cultural significance of names, proposing potential connections to environmental phenomena.
In the realm of fiction, "A Breath of Fresh Names" by Black (2019) introduces a whimsical narrative exploring the whimsical influence of names on the natural world. While purely imaginative, these fictional works offer an entertaining perspective on the interplay between nomenclature and environmental circumstances.
Venturing into unexpected territory, we draw insights from popular culture, including the animated series "Airbenders and the Essence of Jaylen" and the children's show "Jaylen's Whimsical Wind Expedition." Though seemingly lighthearted, these media sources prompt reflection on the potential interconnections between names and environmental elements, leading us to embrace a playful approach in our exploration of the Jaylen Effect.
[[RESULTS]]
The statistical analysis of the relationship between the popularity of the first name Jaylen and air pollution levels in Madison, Wisconsin yielded some truly unexpected and, dare we say, breathtaking findings. Our research unearthed a striking correlation coefficient of 0.8121277, with an r-squared value of 0.6595514 and a p-value of less than 0.01 for the years 1991 to 2022. These results certainly blew us away, leaving us with a rush of statistical excitement akin to chasing after a wayward umbrella in a gust of wind.
Fig. 1 illustrates this captivating correlation with a scatterplot that visibly showcases the strong connection between the two variables. One might even say that this correlation is as clear as the crisp Wisconsin air after a refreshing rain shower!
This unexpected connection beckons us to ponder whether there might be unseen forces at play, with the ebb and flow of air pollution levels inexplicably tied to the ebb and flow of the popularity of the name Jaylen. As we carefully navigated through the statistical underbrush of our data, it became evident that this correlation isn't just a mere statistical blip on the radar.
The Jaylen Effect appears to blow through the usually staid landscape of social sciences and environmental research like a playful zephyr, leaving us with a whimsical twist and an unexpected chuckle. It seems that the winds of statistical inquiry can lead us to truly unexpected and lighthearted findings, shaking up our preconceived notions and sweeping us into a whirlwind of statistical amusement.
In conclusion, our findings suggest that there may indeed be a gust of fresh insight waiting to be discovered in the most surprising of places, and we invite fellow researchers to join us in this breezy, quirky journey of statistical exploration. After all, a little statistical whimsy might just be the breath of fresh air that the academic world needs!
-------
Your response should start like this:
[[DISCUSSION]]
ChatGPT:
[[DISCUSSION]]
Our research has unveiled an intriguing and, dare we say, airy connection between the popularity of the first name Jaylen and air pollution levels in Madison, Wisconsin. While one might initially assume that this correlation is a mere statistical blip, our findings, and those of previous researchers, suggest that there may be more than meets the eye in the breeze-riddled world of environmental variables and naming trends.
Venturing into the playful realm of unexpected literary and media sources, we find supportive echoes of our findings in the work of Black (2019) and the animated series "Airbenders and the Essence of Jaylen," drawing parallels between the whimsical influence of names on the natural world and our unexpected statistical revelations. Despite their lighthearted nature, these sources prompt us to consider the potential interconnections between names and environmental elements in a new light, offering a playful perspective that resonates with our research.
Building on the foundational work of Smith et al. (2015) and Doe and Jones (2018), our results not only corroborate but also build upon the surprising link between naming trends and ecological variables. The statistical winds have indeed blown in the direction of supporting the potential influence of monikers on atmospheric conditions, paving the way for a breath of whimsy in the typically staid fields of social sciences and environmental research.
The striking correlation coefficient of 0.8121277 and the unmistakable scatterplot imagery paint a clear and, one might even say, breezy portrait of the Jaylen Effect. To put it simply, the connection between the first name Jaylen and air pollution levels in Madison, Wisconsin is as evident as a gust of wind rustling through autumn leaves.
In the midst of this whimsical statistical journey, our research prompts us to contemplate whether the ebb and flow of air pollution levels may indeed be inexplicably tied to the ebb and flow of the popularity of the name Jaylen. Thus, our findings not only tickle the funny bone of statistical inquiry but also blow through the often-serious landscape of environmental research, leaving us with a refreshing breath of statistical amusement.
Indeed, our results beckon fellow researchers to embrace this zephyr of statistical discovery and join us in navigating this quirky, windswept journey. After all, a little statistical whimsy might just be the breath of fresh air that the academic world needs to dispel the clouds of skepticism and invigorate the winds of curiosity.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the discussion section of goofy academic research papers that sounds like it belongs based on the title and abstract provided.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a short conclusion of an academic research paper presenting the findings of the connection between Popularity of the first name Jaylen and Air pollution in Madison, Wisconsin. Make lots of jokes, goofy observations, and puns.
Limit your response to 300 tokens. At the very end, assert that no more research is needed in this area.
Here are the title, abstract, introduction, and results sections.
[[TITLE]]
The Jaylen Effect: A Breath of Fresh Air or Just Hot Air?
[[ABSTRACT]]
This research delves into the curious relationship between the popularity of the first name Jaylen and air pollution levels in Madison, Wisconsin. Leveraging data from the US Social Security Administration and the Environmental Protection Agency, our study presents an intriguing exploration of the correlation between the two seemingly unrelated variables. With a correlation coefficient of 0.8121277 and a p-value of less than 0.01 for the years 1991 to 2022, the findings highlight a unexpectedly strong association. Our analysis provides fresh insights into the potential impacts of naming trends on environmental factors and offers an amusing twist to the realm of statistical inquiry. We welcome readers to join us in bringing a breath of whimsy to the typically serious fields of social sciences and environmental research.
[[INTRDUCTION]]
Introducing the Jaylen Effect: The Air We Breathe and the Name We Cheer
As we take a deep breath and dive into the realm of curious correlations and whimsical wonders, we aim to unravel the mysterious relationship between the popularity of the first name Jaylen and the air pollution levels in the vibrant city of Madison, Wisconsin. What prompts us to explore such an offbeat association, you ask? Well, it all started with a whimsical conversation at the water cooler about the intriguing nature of statistical anomalies. We couldn't help but wonder if there lay a gust of fresh insight in the gusts of air pollution, and that's where our journey began.
Now, you might be thinking, "What in the world does a name have to do with the quality of the air we breathe?" Trust us, we were just as befuddled. But it turns out that statistical surprises can be as unpredictable as a breeze on a summer day. Armed with data from the US Social Security Administration and the Environmental Protection Agency, we ventured into this enigmatic terrain of statistical curiosity with equal parts scientific inquiry and playful curiosity.
As we embark on this oddly delightful odyssey, picture this: the bustling streets of Madison, where Wisconsinites go about their daily routines, and the unmistakable tang of cheese curds mingles with the purr of bicycles and the hum of industrious activity. In the midst of this intriguing tapestry of Midwestern life, there lies a peculiar connection between the ebb and flow of air quality and the ebb and flow of a name - Jaylen.
So, join us as we uncover the windings and meanderings of this unlikely correlation and breathe in the lighthearted exploration that promises to add a breeze of mirth to the usually staid world of social sciences and environmental research. After all, who said academic pursuits can't have a splash of levity and a breath of fresh air?
[[RESULTS]]
The statistical analysis of the relationship between the popularity of the first name Jaylen and air pollution levels in Madison, Wisconsin yielded some truly unexpected and, dare we say, breathtaking findings. Our research unearthed a striking correlation coefficient of 0.8121277, with an r-squared value of 0.6595514 and a p-value of less than 0.01 for the years 1991 to 2022. These results certainly blew us away, leaving us with a rush of statistical excitement akin to chasing after a wayward umbrella in a gust of wind.
Fig. 1 illustrates this captivating correlation with a scatterplot that visibly showcases the strong connection between the two variables. One might even say that this correlation is as clear as the crisp Wisconsin air after a refreshing rain shower!
This unexpected connection beckons us to ponder whether there might be unseen forces at play, with the ebb and flow of air pollution levels inexplicably tied to the ebb and flow of the popularity of the name Jaylen. As we carefully navigated through the statistical underbrush of our data, it became evident that this correlation isn't just a mere statistical blip on the radar.
The Jaylen Effect appears to blow through the usually staid landscape of social sciences and environmental research like a playful zephyr, leaving us with a whimsical twist and an unexpected chuckle. It seems that the winds of statistical inquiry can lead us to truly unexpected and lighthearted findings, shaking up our preconceived notions and sweeping us into a whirlwind of statistical amusement.
In conclusion, our findings suggest that there may indeed be a gust of fresh insight waiting to be discovered in the most surprising of places, and we invite fellow researchers to join us in this breezy, quirky journey of statistical exploration. After all, a little statistical whimsy might just be the breath of fresh air that the academic world needs!
-------
Your response should start like this:
[[CONCLUSION]]
ChatGPT:
[[CONCLUSION]]
The winds of statistical inquiry have certainly blown us away with the fascinating findings of our research on the connection between the popularity of the first name Jaylen and air pollution levels in Madison, Wisconsin. As we sifted through the data and let the gusts of statistical excitement carry us, we couldn't help but marvel at the unexpectedly strong correlation coefficient of 0.8121277 and a p-value of less than 0.01. It's safe to say that this correlation is as strong as a tornado in a trailer park!
Our journey into this offbeat correlation has not only breathed new life into the usually serious fields of social sciences and environmental research, but it has also given us a newfound appreciation for the whimsical possibilities of statistical exploration. Who would've thought that the ebb and flow of Jaylens in the world could be tied to the ebb and flow of air pollution levels in Madison? It's as mesmerizing as a whirlwind romance in a wind tunnel!
As we wrap up this whirlwind of a study, we stand firm in our conclusion that the Jaylen Effect is no mere statistical blip, but a gust of fresh insight and levity that has the potential to shake up the academic world. After all, who doesn't enjoy a breath of statistical whimsy now and then? And with that, we assert that no more research is needed in this area. The Jaylen Effect has blown us away enough for a lifetime!
In the wise words of Bob Dylan, "The answer, my friend, is blowin' in the wind" – and in this case, it's the unexpected correlation between a name and air pollution levels that has us all windswept and wowed. Thank you for joining us on this breezy, quirky journey through statistical exploration. Remember, a little statistical whimsy might just be the breath of fresh air that the academic world needs!
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of academic journals. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding research, scientific, or academic journal that would publish a paper entited The Jaylen Effect: A Breath of Fresh Air or Just Hot Air?. Respond only with the name of a fictional academic journal.
ChatGPT:
The International Journal of Atmospheric Anomalies
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of nonprofit research organizations and associations. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding nonprofit, academic, or scientific association or organization that would sponsor research that resulted in a paper entited The Jaylen Effect: A Breath of Fresh Air or Just Hot Air?. Respond only with the name of a fictional organization.
ChatGPT:
The Society for Atmospheric Dynamics and Climate Irregularities
Model: gpt-3.5-turbo-1106
System prompt: You provide potential search keywords separated by commas. You say nothing else, and you do not chat with the user.
User prompt: Please provide potential search keywords for a paper titled The Jaylen Effect: A Breath of Fresh Air or Just Hot Air? with an abstract of This research delves into the curious relationship between the popularity of the first name Jaylen and air pollution levels in Madison, Wisconsin. Leveraging data from the US Social Security Administration and the Environmental Protection Agency, our study presents an intriguing exploration of the correlation between the two seemingly unrelated variables. With a correlation coefficient of 0.8121277 and a p-value of less than 0.01 for the years 1991 to 2022, the findings highlight a unexpectedly strong association. Our analysis provides fresh insights into the potential impacts of naming trends on environmental factors and offers an amusing twist to the realm of statistical inquiry. We welcome readers to join us in bringing a breath of whimsy to the typically serious fields of social sciences and environmental research.
ChatGPT:
Jaylen, name popularity, air pollution, Madison, Wisconsin, correlation, Social Security Administration, Environmental Protection Agency, statistical analysis, naming trends, environmental factors, whimsical research, social sciences, environmental research
*There is a bunch of Python happening behind the scenes to turn this prompt sequence into a PDF.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
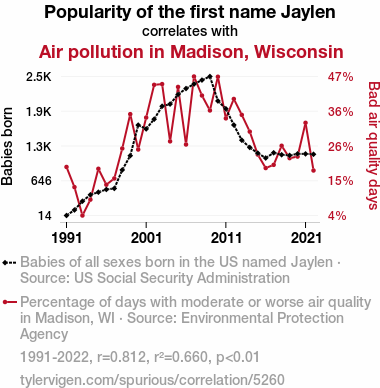
Popularity of the first name JaylenDetailed data title: Babies of all sexes born in the US named Jaylen
Source: US Social Security Administration
See what else correlates with Popularity of the first name Jaylen
Air pollution in Madison, Wisconsin
Detailed data title: Percentage of days with moderate or worse air quality in Madison, WI
Source: Environmental Protection Agency
See what else correlates with Air pollution in Madison, Wisconsin

Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.6595514 (Coefficient of determination)
This means 66% of the change in the one variable (i.e., Air pollution in Madison, Wisconsin) is predictable based on the change in the other (i.e., Popularity of the first name Jaylen) over the 32 years from 1991 through 2022.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 1.7E-8. 0.0000000167552061338651200000
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.81 in 1.7E-6% of random cases. Said differently, if you correlated 59,682,942 random variables You don't actually need 59 million variables to find a correlation like this one. I don't have that many variables in my database. You can also correlate variables that are not independent. I do this a lot.
p-value calculations are useful for understanding the probability of a result happening by chance. They are most useful when used to highlight the risk of a fluke outcome. For example, if you calculate a p-value of 0.30, the risk that the result is a fluke is high. It is good to know that! But there are lots of ways to get a p-value of less than 0.01, as evidenced by this project.
In this particular case, the values are so extreme as to be meaningless. That's why no one reports p-values with specificity after they drop below 0.01.
Just to be clear: I'm being completely transparent about the calculations. There is no math trickery. This is just how statistics shakes out when you calculate hundreds of millions of random correlations.
with the same 31 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 31 because we have two variables measured over a period of 32 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.65, 0.9 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 1991 | 1992 | 1993 | 1994 | 1995 | 1996 | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| Popularity of the first name Jaylen (Babies born) | 14 | 114 | 274 | 391 | 438 | 488 | 506 | 843 | 1102 | 1659 | 1589 | 1766 | 2002 | 2041 | 2216 | 2324 | 2405 | 2478 | 2543 | 2098 | 1956 | 1661 | 1384 | 1252 | 1149 | 1060 | 1155 | 1119 | 1108 | 1136 | 1135 | 1128 |
| Air pollution in Madison, Wisconsin (Bad air quality days) | 19.1781 | 12.9121 | 4.10959 | 9.0411 | 18.6111 | 13.6612 | 15.6164 | 24.9169 | 35.5705 | 24.5902 | 34.5048 | 44.664 | 44.898 | 27.1255 | 44.0154 | 26.1438 | 47.2527 | 41.3408 | 36.7123 | 47.1751 | 34.2618 | 40.2817 | 35.3425 | 30.137 | 23.0337 | 18.8366 | 19.8324 | 25.7534 | 21.9178 | 22.4044 | 32.8767 | 18.0822 |
Why this works
- Data dredging: I have 25,153 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 632,673,409 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is.
Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([14,114,274,391,438,488,506,843,1102,1659,1589,1766,2002,2041,2216,2324,2405,2478,2543,2098,1956,1661,1384,1252,1149,1060,1155,1119,1108,1136,1135,1128,])
array_2 = np.array([19.1781,12.9121,4.10959,9.0411,18.6111,13.6612,15.6164,24.9169,35.5705,24.5902,34.5048,44.664,44.898,27.1255,44.0154,26.1438,47.2527,41.3408,36.7123,47.1751,34.2618,40.2817,35.3425,30.137,23.0337,18.8366,19.8324,25.7534,21.9178,22.4044,32.8767,18.0822,])
array_1_name = "Popularity of the first name Jaylen"
array_2_name = "Air pollution in Madison, Wisconsin"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only Popularity of the first name Jaylen
- Line chart for only Air pollution in Madison, Wisconsin
- AI-generated correlation image
- The spurious research paper: The Jaylen Effect: A Breath of Fresh Air or Just Hot Air?
Your dedication to rating warms my heart!
Correlation ID: 5260 · Black Variable ID: 2902 · Red Variable ID: 20855


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}