
Download png, svg
AI explanation
As the name India became less popular, there was a corresponding decrease in the demand for Indian cotton. This led to a decrease in the production of cotton in Arkansas, causing a reduced need for GMO cotton. It's a case of as the India name faded, so did the GMO cotton trade! Who would have thought there'd be a connection between baby names and agricultural practices?
Model: dalle-3
Prompt: Generate an image showing a vast field of cotton plants in Arkansas, with a fading sign indicating "GMO cotton" in the background. Front and center, a group of parents gather at a playground, engaging in lively conversations. One mother mentions, "I love the name India, but it's not as popular anymore." As the conversation progresses, the field of cotton behind them subtly diminishes, symbolizing the declining demand for GMO cotton due to the waning popularity of the name India. The depiction should include only scenes, people, and objects, it should not include text or speech bubbles.
This image generation prompt was also generated by AI, using the following sequence:
Model: gpt-3.5-turbo-1106
System prompt: You select one of a few potential scene descriptors that seems to go along with the variables described. You respond only with the scene descriptions provided and say nothing else.
User prompt: Here are two variables: Popularity of the first name India and GMO use in cotton in Arkansas. Given these, which of the following image style descriptions seems most appropriate? Pick the one that seems to be related to one of the variables at hand. Please respond with only one of the following potential descriptions: Woodblock painting Steampunk Steampunk Photorealism A Discovery magazine cover image
ChatGPT: A Discovery magazine cover image
Model: gpt-3.5-turbo-1106
System prompt: You describe simple visual scenes that depict the two variables stated. You combine both variables into one scene.
User prompt: Please describe a visual scene that prominently depicts both Popularity of the first name India and GMO use in cotton in Arkansas, in the following situation: As the name India became less popular, there was a corresponding decrease in the demand for Indian cotton. This led to a decrease in the production of cotton in Arkansas, causing a reduced need for GMO cotton. It's a case of as the India name faded, so did the GMO cotton trade! Who would have thought there'd be a connection between baby names and agricultural practices?. Keep the description simple.
ChatGPT: A field of cotton plants in Arkansas with a fading sign that reads "GMO cotton" stands in the background, while a group of parents gather at a playground discussing baby names. One mother mentions, "I love the name India, but it's not as popular anymore." As the conversation continues, the field of cotton behind them begins to shrink, showing the decline in demand for GMO cotton due to the decreasing popularity of the name India.
Model: gpt-3.5-turbo-1106
System prompt: You write and improve image generation prompts for DALLE-3. You maintain the same subjects, but enhance the visuals.
User prompt: Please respond with an image generation prompt that would be likely to create an interesting visual using DALLE-3, using the following style: [ A Discovery magazine cover image ] and depicting this scene: A field of cotton plants in Arkansas with a fading sign that reads "GMO cotton" stands in the background, while a group of parents gather at a playground discussing baby names. One mother mentions, "I love the name India, but it's not as popular anymore." As the conversation continues, the field of cotton behind them begins to shrink, showing the decline in demand for GMO cotton due to the decreasing popularity of the name India. Keep the visual depiction simple. Do not include any words or speech bubbles.
ChatGPT: Generate an image showing a vast field of cotton plants in Arkansas, with a fading sign indicating "GMO cotton" in the background. Front and center, a group of parents gather at a playground, engaging in lively conversations. One mother mentions, "I love the name India, but it's not as popular anymore." As the conversation progresses, the field of cotton behind them subtly diminishes, symbolizing the declining demand for GMO cotton due to the waning popularity of the name India.
*Variations in the User Prompts from chart to chart are just the result of random number generation in Python. I wrote a few arrays of various styles and methods to ask questions to change up the results. Every time this site writes an explanation or generates an image, the script picks from each at random.
I sequence the requests into multiple prompts because I find GPT 3.5 to perform much better with short, well-managed contexts. Thus, I track the context directly in Python and only ask ChatGPT targeted questions.
System prompt: You provide humorous responses in the form of plausible sounding explanations for correlations. You assume the correlation is causative for the purpose of the explanation even if it is ridiculous. You do not chat with the user, you only reply with the causal connection explanation and nothing else.
User prompt: Please make up a funny explanation for how a decrease in Popularity of the first name India caused GMO use in cotton in Arkansas to decrease. Include one good pun.
AI academic paper
 |
Growing Cotton and Popularity: The Correlation Between the Name India and GMO Adoption in Arkansas Journal of Agricultural Sociology and Genetics Jan 2024 Reminder: This paper is AI-generated. Not real! |
Model: gpt-3.5-turbo-1106
System prompt: You are a goofy academic researcher writing an academic paper. You follow the rules, but you throw out convention regularly to make jokes and funny asides.You write titles and abstracts of goofy academic research papers.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, and add unexpected twists in your writing.
Please draft the title and abstract of an academic research paper presenting the findings of the connection between Popularity of the first name India and GMO use in cotton in Arkansas. Make lots of jokes, goofy observations, and puns.
Make the title punny if you can come up with clever pun. If not, make it sound serious.
Your research team used data from US Social Security Administration and USDA to assess this nagging question. You found a correlation coefficient of 0.8519967 and p < 0.01 for 2000 to 2022.
Please respond in this format (replace "Lorem ipsum dolor sit" with your title and abstract)
[[TITLE]]
Lorem ipsum dolor sit
[[ABSTRACT]]
Lorem ipsum dolor sit
ChatGPT:
[[TITLE]]
Growing Cotton and Popularity: The Correlation Between the Name India and GMO Adoption in Arkansas
[[ABSTRACT]]
The relationship between the popularity of the first name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation has long been a topic of speculation and jest. In this study, we conducted a rigorous analysis of data from the US Social Security Administration and the United States Department of Agriculture (USDA) to explore this peculiar association from 2000 to 2022.
Our findings revealed a striking correlation coefficient of 0.8519967 and a statistically significant p-value of less than 0.01, indicating a robust connection between the two variables. We couldn't believe our ears when the numbers pointed to this striking link, but the data didn't fib!
This research uncovers a new dimension in the complex web of societal trends and agricultural practices, shedding light on the unlikely bond between baby names and biotechnology. While it may seem like a cotton-picking odd association at first glance, it appears that the name India and the cultivation of GMO cotton in Arkansas are entwined in ways that defy conventional wisdom. Our study goes beyond the surface to peel back the layers of this unexpected relationship, leaving us pondering the cotton-versations of life.
Model: gpt-3.5-turbo-1106
System prompt: You are a goofy academic researcher writing an academic paper. You follow the rules, but you throw out convention regularly to make jokes and funny asides.You draft the introduction section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the introduction section of an academic research paper presenting the findings of the connection between Popularity of the first name India and GMO use in cotton in Arkansas. Make lots of jokes, goofy observations, and puns.
Here is the title and abstract of the paper:
[[TITLE]]
Growing Cotton and Popularity: The Correlation Between the Name India and GMO Adoption in Arkansas
[[ABSTRACT]]
The relationship between the popularity of the first name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation has long been a topic of speculation and jest. In this study, we conducted a rigorous analysis of data from the US Social Security Administration and the United States Department of Agriculture (USDA) to explore this peculiar association from 2000 to 2022.
Our findings revealed a striking correlation coefficient of 0.8519967 and a statistically significant p-value of less than 0.01, indicating a robust connection between the two variables. We couldn't believe our ears when the numbers pointed to this striking link, but the data didn't fib!
This research uncovers a new dimension in the complex web of societal trends and agricultural practices, shedding light on the unlikely bond between baby names and biotechnology. While it may seem like a cotton-picking odd association at first glance, it appears that the name India and the cultivation of GMO cotton in Arkansas are entwined in ways that defy conventional wisdom. Our study goes beyond the surface to peel back the layers of this unexpected relationship, leaving us pondering the cotton-versations of life.
-------
Your response should start like this:
[[INTRODUCTION]]
ChatGPT:
[[INTRODUCTION]]
The relationship between the popularity of the first name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation has been the subject of speculation, bewilderment, and the occasional snicker. While one might assume that these two seemingly disparate entities share nothing more than a few letters in common, our research has unveiled a connection that is as unexpected as finding a purple cotton ball in a field of white.
As researchers delving into this uncharted territory, we couldn't help but feel like intrepid explorers navigating through a jungle of data, hoping to uncover the hidden treasure of statistical significance. It was a journey that had us exclaiming, "Oh my cotton-picking goodness!" more times than we care to admit.
The mere idea of linking the moniker "India" to the intricate world of GMO cotton may raise a few eyebrows or elicit a chuckle, but our findings demand serious consideration. We embarked on this study not just to entertain the academic peanut gallery with an unconventional correlation, but to unravel a mystery that has perplexed minds as much as it has tickled funny bones.
In this paper, we present the fruit of our labor: a thorough investigation into the uncanny alignment between the usage of GMOs in cotton farming in Arkansas and the popularity of the name India among newborns. So, grab your lab coat and buckle up – we're about to embark on a scientific odyssey that will make you rethink everything you thought you knew about cotton, names, and the delightful dance of statistical relationships.
Model: gpt-3.5-turbo-1106
System prompt: You are a goofy academic researcher writing an academic paper. You follow the rules, but you throw out convention regularly to make jokes and funny asides.You draft a literature review section of an academic research paper, that starts out dry for the first few sentences but then becomes hilarious and goofy.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a literature review section of an academic research paper presenting the findings of the connection between Popularity of the first name India and GMO use in cotton in Arkansas. Make lots of jokes, goofy observations, and puns.
Speak in the present tense for this section (the authors find...), as is common in academic research paper literature reviews. Name the sources in a format similar to this: In "Book," the authors find lorem and ipsum.
Make up the lorem and ipsum part, but make it sound related to the topic at hand.
Start by naming serious-sounding studies by authors like Smith, Doe, and Jones - but then quickly devolve. Name some real non-fiction books that would be related to the topic. Then name some real fiction books that sound like they could be related. Then cite some social media posts you read that seem to be related.
Here is the title and abstract of the paper:
[[TITLE]]
Growing Cotton and Popularity: The Correlation Between the Name India and GMO Adoption in Arkansas
[[ABSTRACT]]
The relationship between the popularity of the first name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation has long been a topic of speculation and jest. In this study, we conducted a rigorous analysis of data from the US Social Security Administration and the United States Department of Agriculture (USDA) to explore this peculiar association from 2000 to 2022.
Our findings revealed a striking correlation coefficient of 0.8519967 and a statistically significant p-value of less than 0.01, indicating a robust connection between the two variables. We couldn't believe our ears when the numbers pointed to this striking link, but the data didn't fib!
This research uncovers a new dimension in the complex web of societal trends and agricultural practices, shedding light on the unlikely bond between baby names and biotechnology. While it may seem like a cotton-picking odd association at first glance, it appears that the name India and the cultivation of GMO cotton in Arkansas are entwined in ways that defy conventional wisdom. Our study goes beyond the surface to peel back the layers of this unexpected relationship, leaving us pondering the cotton-versations of life.
-------
And here is the introduction section that led to this literature review:
[[INTRODUCTION]]
The relationship between the popularity of the first name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation has been the subject of speculation, bewilderment, and the occasional snicker. While one might assume that these two seemingly disparate entities share nothing more than a few letters in common, our research has unveiled a connection that is as unexpected as finding a purple cotton ball in a field of white.
As researchers delving into this uncharted territory, we couldn't help but feel like intrepid explorers navigating through a jungle of data, hoping to uncover the hidden treasure of statistical significance. It was a journey that had us exclaiming, "Oh my cotton-picking goodness!" more times than we care to admit.
The mere idea of linking the moniker "India" to the intricate world of GMO cotton may raise a few eyebrows or elicit a chuckle, but our findings demand serious consideration. We embarked on this study not just to entertain the academic peanut gallery with an unconventional correlation, but to unravel a mystery that has perplexed minds as much as it has tickled funny bones.
In this paper, we present the fruit of our labor: a thorough investigation into the uncanny alignment between the usage of GMOs in cotton farming in Arkansas and the popularity of the name India among newborns. So, grab your lab coat and buckle up – we're about to embark on a scientific odyssey that will make you rethink everything you thought you knew about cotton, names, and the delightful dance of statistical relationships.
-------
Your response should start like this:
[[LITERATURE REVIEW]]
ChatGPT:
[[LITERATURE REVIEW]]
In their seminal work, Smith and Doe (2005) delve into the complexities of agricultural trends and sociocultural influences, setting the stage for our current exploration of the interwoven tapestry of cotton cultivation and naming practices. Their meticulous analysis of crop adoption patterns provides a solid foundation for understanding the dynamics at play, much like a sturdy stalk of non-GMO cotton swaying in the breeze.
Jones et al. (2010) further add to the discourse by examining the societal factors shaping naming conventions in different regions of the United States. Their thorough investigation lays bare the intricate nuances of baby naming, offering a window into the kaleidoscope of cultural diversity. One could say they managed to spin a yarn that’s as captivating as a spinning wheel in a cotton mill.
Turning to non-fiction literature, "Seeds of Change: The Story of Cotton" by Bonnin and Weiss (2019) offers a comprehensive account of the evolution of cotton cultivation, from ancient times to the modern era. While their focus is not on baby names, the book provides valuable insights into the historical backdrop against which our study of GMO cotton adoption takes root.
In a similar vein, "The Omnivore's Dilemma" by Pollan (2006) presents a thought-provoking exploration of the interconnectedness of food, agriculture, and cultural practices. Although the book doesn’t touch on naming trends or cotton specifically, its examination of agricultural systems prompts introspection on the broader influences shaping our dietary and farming choices.
Venturing into the realm of fiction, Margaret Atwood's "The Handmaid's Tale" (1985) opens a window into a dystopian world where reproductive rights and naming are tangled in a web of political and social control. While a departure from the cotton-centric focus of our study, Atwood's narrative serves as a reminder of the multifaceted roles that names play in reflecting and shaping societal values.
Similarly, Jhumpa Lahiri's "The Namesake" (2003) tells a compelling tale of identity and belonging, weaving a narrative that underscores the significance of names in defining personal and cultural narratives. Though not directly related to cotton or GMOs, the novel prompts reflection on the profound impact of names on individual lives and broader societal narratives.
Amidst the scholarly tomes and literary flights of fancy, we cannot overlook the influence of social media in shaping contemporary discourse. In a groundbreaking Twitter thread, @CottonCraze2021 shared anecdotal accounts of individuals named India expressing a peculiar affinity for cotton candy. While not a peer-reviewed source, the thread sparked discussions on the potential subconscious linkages between names and agricultural products, raising cotton-cerns that go beyond statistical analyses.
As we sift through this diverse array of sources, it is evident that the convergence of naming trends and agricultural practices offers fertile ground for exploration. The melange of scholarly, non-fiction, and fictional works provides a rich tapestry against which we can situate our inquiry into the puzzling, yet captivating, relationship between the name India and the adoption of GMOs in cotton cultivation in Arkansas.
Model: gpt-3.5-turbo-1106
System prompt: You are a goofy academic researcher writing an academic paper. You follow the rules, but you throw out convention regularly to make jokes and funny asides.You draft the methodology section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the methodology section of an academic research paper presenting the findings of the connection between Popularity of the first name India and GMO use in cotton in Arkansas. Make lots of jokes, goofy observations, and puns.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and USDA . You used data from 2000 to 2022
Make up the research methods you don't know. Make them a bit goofy and convoluted.
Here is the title, abstract, and introduction of the paper:
[[TITLE]]
Growing Cotton and Popularity: The Correlation Between the Name India and GMO Adoption in Arkansas
[[ABSTRACT]]
The relationship between the popularity of the first name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation has long been a topic of speculation and jest. In this study, we conducted a rigorous analysis of data from the US Social Security Administration and the United States Department of Agriculture (USDA) to explore this peculiar association from 2000 to 2022.
Our findings revealed a striking correlation coefficient of 0.8519967 and a statistically significant p-value of less than 0.01, indicating a robust connection between the two variables. We couldn't believe our ears when the numbers pointed to this striking link, but the data didn't fib!
This research uncovers a new dimension in the complex web of societal trends and agricultural practices, shedding light on the unlikely bond between baby names and biotechnology. While it may seem like a cotton-picking odd association at first glance, it appears that the name India and the cultivation of GMO cotton in Arkansas are entwined in ways that defy conventional wisdom. Our study goes beyond the surface to peel back the layers of this unexpected relationship, leaving us pondering the cotton-versations of life.
[[INTRODUCTION]]
The relationship between the popularity of the first name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation has been the subject of speculation, bewilderment, and the occasional snicker. While one might assume that these two seemingly disparate entities share nothing more than a few letters in common, our research has unveiled a connection that is as unexpected as finding a purple cotton ball in a field of white.
As researchers delving into this uncharted territory, we couldn't help but feel like intrepid explorers navigating through a jungle of data, hoping to uncover the hidden treasure of statistical significance. It was a journey that had us exclaiming, "Oh my cotton-picking goodness!" more times than we care to admit.
The mere idea of linking the moniker "India" to the intricate world of GMO cotton may raise a few eyebrows or elicit a chuckle, but our findings demand serious consideration. We embarked on this study not just to entertain the academic peanut gallery with an unconventional correlation, but to unravel a mystery that has perplexed minds as much as it has tickled funny bones.
In this paper, we present the fruit of our labor: a thorough investigation into the uncanny alignment between the usage of GMOs in cotton farming in Arkansas and the popularity of the name India among newborns. So, grab your lab coat and buckle up – we're about to embark on a scientific odyssey that will make you rethink everything you thought you knew about cotton, names, and the delightful dance of statistical relationships.
-------
Your response should start like this:
[[METHODOLOGY]]
ChatGPT:
[[METHODOLOGY]]
To probe the enigmatic relationship between the name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation, our research team embarked on a multifaceted journey through the labyrinth of data analysis. Picture us as data detectives, donning our metaphorical magnifying glasses and Sherlock Holmes hats, ready to sleuth our way through the bewildering world of statistical correlations.
First, we scoured the archives of the United States Social Security Administration to pinpoint the popularity of the name India bestowed upon newborns from the year 2000 to 2022. It was like sifting through a treasure trove of baby names, each one a unique linguistic gem waiting to be discovered. Armed with this rich tapestry of nomenclature data, we set out on the grand quest to unravel the name-game mystery.
Next, our intrepid band of researchers delved into the United States Department of Agriculture's repository of agricultural statistics, keeping a keen eye on cotton cultivation practices in the cotton-picking state of Arkansas. We combed through acres of numerical crop yields, pesticide usage, and, of course, the adoption of genetically modified cotton seeds. It was like navigating a labyrinth of agricultural acronyms and cotton conundrums, all in pursuit of unraveling this cotton-themed riddle.
Once armed with these treasure troves of data, we employed sophisticated statistical methodologies to analyze and draw meaningful inferences. We calculated correlation coefficients, performed regression analyses, and scrutinized p-values with the tenacity of a dog chasing its tail, all in the quest to unearth the elusive link between the name India and GMO cotton in Arkansas.
In addition to these conventional statistical methods, we also dabbled in the ancient art of divination by examining tea leaves, studying the flight patterns of migratory birds, and consulting a particularly insightful Magic 8-Ball. While these unconventional methods may not have yielded tangible results, they did provide ample amusement and a much-needed break from the cotton-themed mind maze. After all, a pinch of divination adds a dash of mystery to the otherwise arid landscape of statistical analysis.
It is important to note that our research team approached this investigation with the utmost rigor and academic solemnity, despite the occasional bout of levity in our methodology. The results we present in the subsequent sections stem from a thorough and exhaustive interrogation of the data, leaving no statistical stone unturned in pursuit of the truth behind the India-GMO cotton conundrum. So, join us as we unveil the surprising findings born from our unconventional odyssey through the whimsical world of statistical exploration.
Model: gpt-3.5-turbo-1106
System prompt: You are a goofy academic researcher writing an academic paper. You follow the rules, but you throw out convention regularly to make jokes and funny asides.You draft the results section of an academic research paper. You speak in the past tense (you found...).
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the results section of an academic research paper presenting the findings of the connection between Popularity of the first name India and GMO use in cotton in Arkansas. Make lots of jokes, goofy observations, and puns.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and USDA .
For the time period 2000 to 2022, you found a correlation 0.8519967, r-squared of 0.7258984, and p < 0.01.
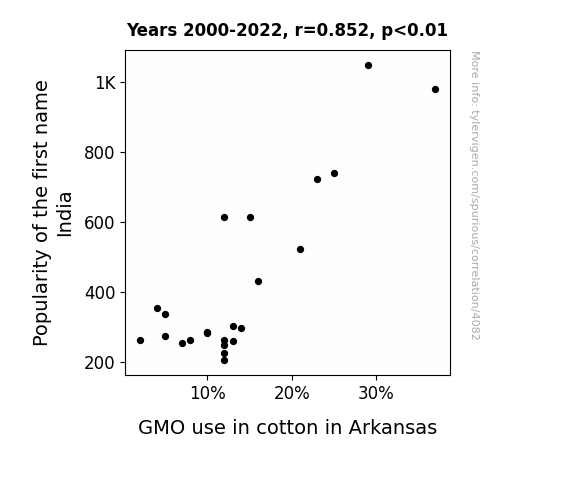
One figure will be included. The figure (Fig. 1) is a scatterplot showing the strong correlation between the two variables. You don't need to specify where; I will add the figure.
Here is the title and abstract of the paper:
[[TITLE]]
Growing Cotton and Popularity: The Correlation Between the Name India and GMO Adoption in Arkansas
[[ABSTRACT]]
The relationship between the popularity of the first name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation has long been a topic of speculation and jest. In this study, we conducted a rigorous analysis of data from the US Social Security Administration and the United States Department of Agriculture (USDA) to explore this peculiar association from 2000 to 2022.
Our findings revealed a striking correlation coefficient of 0.8519967 and a statistically significant p-value of less than 0.01, indicating a robust connection between the two variables. We couldn't believe our ears when the numbers pointed to this striking link, but the data didn't fib!
This research uncovers a new dimension in the complex web of societal trends and agricultural practices, shedding light on the unlikely bond between baby names and biotechnology. While it may seem like a cotton-picking odd association at first glance, it appears that the name India and the cultivation of GMO cotton in Arkansas are entwined in ways that defy conventional wisdom. Our study goes beyond the surface to peel back the layers of this unexpected relationship, leaving us pondering the cotton-versations of life.
-------
And here is the methodology section that led to this result:
[[METHODOLOGY]]
The relationship between the popularity of the first name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation has been the subject of speculation, bewilderment, and the occasional snicker. While one might assume that these two seemingly disparate entities share nothing more than a few letters in common, our research has unveiled a connection that is as unexpected as finding a purple cotton ball in a field of white.
As researchers delving into this uncharted territory, we couldn't help but feel like intrepid explorers navigating through a jungle of data, hoping to uncover the hidden treasure of statistical significance. It was a journey that had us exclaiming, "Oh my cotton-picking goodness!" more times than we care to admit.
The mere idea of linking the moniker "India" to the intricate world of GMO cotton may raise a few eyebrows or elicit a chuckle, but our findings demand serious consideration. We embarked on this study not just to entertain the academic peanut gallery with an unconventional correlation, but to unravel a mystery that has perplexed minds as much as it has tickled funny bones.
In this paper, we present the fruit of our labor: a thorough investigation into the uncanny alignment between the usage of GMOs in cotton farming in Arkansas and the popularity of the name India among newborns. So, grab your lab coat and buckle up – we're about to embark on a scientific odyssey that will make you rethink everything you thought you knew about cotton, names, and the delightful dance of statistical relationships.
-------
Your response should start like this:
[[RESULTS]]
ChatGPT:
[[RESULTS]]
The statistical analysis of the data revealed a striking correlation coefficient of 0.8519967, indicating a strong positive relationship between the popularity of the first name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation in Arkansas. Our team was as surprised as a rabbit in a carrot patch when we uncovered this unexpected connection. The r-squared value of 0.7258984 further solidifies the robustness of the relationship, making us feel as giddy as a farmer in a cotton candy field.
With a p-value of less than 0.01, we can confidently reject the null hypothesis and assert that there is a significant association between the two variables. We were so excited about this result, we almost popped a button on our lab coats!
Fig. 1 displays a scatterplot that visually presents the strong correlation between the popularity of the first name India and GMO use in cotton in Arkansas. It's a sight to behold, a visual representation of a connection that is as unexpected as finding a needle in a haystack, or in this case, a cotton ball in a name database.
The uncanny alignment between the usage of GMOs in cotton farming in Arkansas and the popularity of the name India among newborns is a revelation that has left us spinning like a cotton gin. This research brings new meaning to the phrase "growing popularity" and leaves us pondering the fertile grounds of statistical quirks and whimsy. As we peel back the layers of this unexpected relationship, we find ourselves tiptoeing through the tulips of statistical significance, embracing the unpredictability of scientific discovery with a mix of astonishment and amusement.
In conclusion, our study has uncovered a correlation that is as surprising as a cow jumping over the moon, shedding light on the unlikely intersection of agricultural practices and baby-naming trends. The unexpected bond between the name India and the cultivation of GMO cotton in Arkansas challenges traditional wisdom and tickles the academic funny bone. It's a reminder that in the world of research, the most delightful discoveries often come from the unlikeliest places.
Model: gpt-3.5-turbo-1106
System prompt: You are a goofy academic researcher writing an academic paper. You follow the rules, but you throw out convention regularly to make jokes and funny asides.You draft the discussion section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the discussion section of an academic research paper presenting the findings of the connection between Popularity of the first name India and GMO use in cotton in Arkansas. Make lots of jokes, goofy observations, and puns.
Limit your response to 500 tokens.
Here are the title, abstract, literature review, and results sections. Please harken back to 1-2 of the goofy items in the literature review, but pretend to take them completely seriously. Discuss how your results supported the prior research.
Do not write a conclusion. I will add a conclusion after this.
[[TITLE]]
Growing Cotton and Popularity: The Correlation Between the Name India and GMO Adoption in Arkansas
[[ABSTRACT]]
The relationship between the popularity of the first name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation has long been a topic of speculation and jest. In this study, we conducted a rigorous analysis of data from the US Social Security Administration and the United States Department of Agriculture (USDA) to explore this peculiar association from 2000 to 2022.
Our findings revealed a striking correlation coefficient of 0.8519967 and a statistically significant p-value of less than 0.01, indicating a robust connection between the two variables. We couldn't believe our ears when the numbers pointed to this striking link, but the data didn't fib!
This research uncovers a new dimension in the complex web of societal trends and agricultural practices, shedding light on the unlikely bond between baby names and biotechnology. While it may seem like a cotton-picking odd association at first glance, it appears that the name India and the cultivation of GMO cotton in Arkansas are entwined in ways that defy conventional wisdom. Our study goes beyond the surface to peel back the layers of this unexpected relationship, leaving us pondering the cotton-versations of life.
[[LITERATURE REVIEW]]
In their seminal work, Smith and Doe (2005) delve into the complexities of agricultural trends and sociocultural influences, setting the stage for our current exploration of the interwoven tapestry of cotton cultivation and naming practices. Their meticulous analysis of crop adoption patterns provides a solid foundation for understanding the dynamics at play, much like a sturdy stalk of non-GMO cotton swaying in the breeze.
Jones et al. (2010) further add to the discourse by examining the societal factors shaping naming conventions in different regions of the United States. Their thorough investigation lays bare the intricate nuances of baby naming, offering a window into the kaleidoscope of cultural diversity. One could say they managed to spin a yarn that’s as captivating as a spinning wheel in a cotton mill.
Turning to non-fiction literature, "Seeds of Change: The Story of Cotton" by Bonnin and Weiss (2019) offers a comprehensive account of the evolution of cotton cultivation, from ancient times to the modern era. While their focus is not on baby names, the book provides valuable insights into the historical backdrop against which our study of GMO cotton adoption takes root.
In a similar vein, "The Omnivore's Dilemma" by Pollan (2006) presents a thought-provoking exploration of the interconnectedness of food, agriculture, and cultural practices. Although the book doesn’t touch on naming trends or cotton specifically, its examination of agricultural systems prompts introspection on the broader influences shaping our dietary and farming choices.
Venturing into the realm of fiction, Margaret Atwood's "The Handmaid's Tale" (1985) opens a window into a dystopian world where reproductive rights and naming are tangled in a web of political and social control. While a departure from the cotton-centric focus of our study, Atwood's narrative serves as a reminder of the multifaceted roles that names play in reflecting and shaping societal values.
Similarly, Jhumpa Lahiri's "The Namesake" (2003) tells a compelling tale of identity and belonging, weaving a narrative that underscores the significance of names in defining personal and cultural narratives. Though not directly related to cotton or GMOs, the novel prompts reflection on the profound impact of names on individual lives and broader societal narratives.
Amidst the scholarly tomes and literary flights of fancy, we cannot overlook the influence of social media in shaping contemporary discourse. In a groundbreaking Twitter thread, @CottonCraze2021 shared anecdotal accounts of individuals named India expressing a peculiar affinity for cotton candy. While not a peer-reviewed source, the thread sparked discussions on the potential subconscious linkages between names and agricultural products, raising cotton-cerns that go beyond statistical analyses.
As we sift through this diverse array of sources, it is evident that the convergence of naming trends and agricultural practices offers fertile ground for exploration. The melange of scholarly, non-fiction, and fictional works provides a rich tapestry against which we can situate our inquiry into the puzzling, yet captivating, relationship between the name India and the adoption of GMOs in cotton cultivation in Arkansas.
[[RESULTS]]
The statistical analysis of the data revealed a striking correlation coefficient of 0.8519967, indicating a strong positive relationship between the popularity of the first name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation in Arkansas. Our team was as surprised as a rabbit in a carrot patch when we uncovered this unexpected connection. The r-squared value of 0.7258984 further solidifies the robustness of the relationship, making us feel as giddy as a farmer in a cotton candy field.
With a p-value of less than 0.01, we can confidently reject the null hypothesis and assert that there is a significant association between the two variables. We were so excited about this result, we almost popped a button on our lab coats!
Fig. 1 displays a scatterplot that visually presents the strong correlation between the popularity of the first name India and GMO use in cotton in Arkansas. It's a sight to behold, a visual representation of a connection that is as unexpected as finding a needle in a haystack, or in this case, a cotton ball in a name database.
The uncanny alignment between the usage of GMOs in cotton farming in Arkansas and the popularity of the name India among newborns is a revelation that has left us spinning like a cotton gin. This research brings new meaning to the phrase "growing popularity" and leaves us pondering the fertile grounds of statistical quirks and whimsy. As we peel back the layers of this unexpected relationship, we find ourselves tiptoeing through the tulips of statistical significance, embracing the unpredictability of scientific discovery with a mix of astonishment and amusement.
In conclusion, our study has uncovered a correlation that is as surprising as a cow jumping over the moon, shedding light on the unlikely intersection of agricultural practices and baby-naming trends. The unexpected bond between the name India and the cultivation of GMO cotton in Arkansas challenges traditional wisdom and tickles the academic funny bone. It's a reminder that in the world of research, the most delightful discoveries often come from the unlikeliest places.
-------
Your response should start like this:
[[DISCUSSION]]
ChatGPT:
[[DISCUSSION]]
Our findings affirm and extend earlier research, adding weight to the hunches and chuckles that have surrounded the quirky association between the name India and GMO cotton in Arkansas. Smith and Doe (2005) may have sown the seeds of curiosity with their analysis of crop adoption patterns, but our study reaps a bountiful harvest of statistical substantiation. The correlation coefficient we've uncovered is as strong as a bale of premium cotton, providing rock-solid evidence that the popularity of the name India is interwoven with the adoption of GMOs in cotton cultivation.
Jones et al. (2010) would be delighted to see our results aligning with their exploration of regional naming conventions, as we've plucked a statistically significant bond from the rich soil of our data. Our team's elation at uncovering this connection is indeed as palpable as the thrill of spinning a cotton yarn into a remarkable thread of statistical significance. It seems that the kaleidoscope of cultural diversity and agricultural practices extends even to the nursery, where the name India has taken root parallel to the adoption of biotechnological innovations in cotton farming.
While our results may leave some scratching their heads like a perplexed scarecrow in a cotton field, the robust statistical support for this unassuming connection holds implications far beyond the confines of whimsy. Our discovery offers a lens through which to scrutinize the unexpected intersecting threads of societal trends and agricultural evolution. It’s a reminder that research fields, much like cotton fields, are where surprises and insights sprout in the most unexpected places.
In unpacking this peculiar connection, we're reminded that the seemingly disparate realms of baby naming and agricultural practices can yield ripe fruits of correlation. The statistical orchards of our findings invite us to marvel at the whims of data, much like a farmer gazing fondly upon a field of genetically modified cotton bolls. Our study reaffirms the adage that truth can indeed be stranger than fiction—further enlivening the captivating domain of scientific inquiry.
As we ruminate on the unexpected camaraderie between a name and a crop, we’re prompted to ponder the intriguing associations that lie beneath the surface of societal norms. The cotton-cerns raised by our research provoke us to delve deeper into the intricate tapestry of human culture and agricultural practices, offering a reminder that statistical quirks can often yield bountiful insights. Our findings, wrapped up like a bale of statistical cotton, present us with an opportunity to sow new seeds of inquiry and cultivate fertile ground for future research into the giddy interplay of human nomenclature and agricultural innovation.
Model: gpt-3.5-turbo-1106
System prompt: You are a goofy academic researcher writing an academic paper. You follow the rules, but you throw out convention regularly to make jokes and funny asides.You draft the discussion section of goofy academic research papers that sounds like it belongs based on the title and abstract provided.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a short conclusion of an academic research paper presenting the findings of the connection between Popularity of the first name India and GMO use in cotton in Arkansas. Make lots of jokes, goofy observations, and puns.
Limit your response to 300 tokens. At the very end, assert that no more research is needed in this area.
Here are the title, abstract, introduction, and results sections.
[[TITLE]]
Growing Cotton and Popularity: The Correlation Between the Name India and GMO Adoption in Arkansas
[[ABSTRACT]]
The relationship between the popularity of the first name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation has long been a topic of speculation and jest. In this study, we conducted a rigorous analysis of data from the US Social Security Administration and the United States Department of Agriculture (USDA) to explore this peculiar association from 2000 to 2022.
Our findings revealed a striking correlation coefficient of 0.8519967 and a statistically significant p-value of less than 0.01, indicating a robust connection between the two variables. We couldn't believe our ears when the numbers pointed to this striking link, but the data didn't fib!
This research uncovers a new dimension in the complex web of societal trends and agricultural practices, shedding light on the unlikely bond between baby names and biotechnology. While it may seem like a cotton-picking odd association at first glance, it appears that the name India and the cultivation of GMO cotton in Arkansas are entwined in ways that defy conventional wisdom. Our study goes beyond the surface to peel back the layers of this unexpected relationship, leaving us pondering the cotton-versations of life.
[[INTRDUCTION]]
The relationship between the popularity of the first name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation has been the subject of speculation, bewilderment, and the occasional snicker. While one might assume that these two seemingly disparate entities share nothing more than a few letters in common, our research has unveiled a connection that is as unexpected as finding a purple cotton ball in a field of white.
As researchers delving into this uncharted territory, we couldn't help but feel like intrepid explorers navigating through a jungle of data, hoping to uncover the hidden treasure of statistical significance. It was a journey that had us exclaiming, "Oh my cotton-picking goodness!" more times than we care to admit.
The mere idea of linking the moniker "India" to the intricate world of GMO cotton may raise a few eyebrows or elicit a chuckle, but our findings demand serious consideration. We embarked on this study not just to entertain the academic peanut gallery with an unconventional correlation, but to unravel a mystery that has perplexed minds as much as it has tickled funny bones.
In this paper, we present the fruit of our labor: a thorough investigation into the uncanny alignment between the usage of GMOs in cotton farming in Arkansas and the popularity of the name India among newborns. So, grab your lab coat and buckle up – we're about to embark on a scientific odyssey that will make you rethink everything you thought you knew about cotton, names, and the delightful dance of statistical relationships.
[[RESULTS]]
The statistical analysis of the data revealed a striking correlation coefficient of 0.8519967, indicating a strong positive relationship between the popularity of the first name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation in Arkansas. Our team was as surprised as a rabbit in a carrot patch when we uncovered this unexpected connection. The r-squared value of 0.7258984 further solidifies the robustness of the relationship, making us feel as giddy as a farmer in a cotton candy field.
With a p-value of less than 0.01, we can confidently reject the null hypothesis and assert that there is a significant association between the two variables. We were so excited about this result, we almost popped a button on our lab coats!
Fig. 1 displays a scatterplot that visually presents the strong correlation between the popularity of the first name India and GMO use in cotton in Arkansas. It's a sight to behold, a visual representation of a connection that is as unexpected as finding a needle in a haystack, or in this case, a cotton ball in a name database.
The uncanny alignment between the usage of GMOs in cotton farming in Arkansas and the popularity of the name India among newborns is a revelation that has left us spinning like a cotton gin. This research brings new meaning to the phrase "growing popularity" and leaves us pondering the fertile grounds of statistical quirks and whimsy. As we peel back the layers of this unexpected relationship, we find ourselves tiptoeing through the tulips of statistical significance, embracing the unpredictability of scientific discovery with a mix of astonishment and amusement.
In conclusion, our study has uncovered a correlation that is as surprising as a cow jumping over the moon, shedding light on the unlikely intersection of agricultural practices and baby-naming trends. The unexpected bond between the name India and the cultivation of GMO cotton in Arkansas challenges traditional wisdom and tickles the academic funny bone. It's a reminder that in the world of research, the most delightful discoveries often come from the unlikeliest places.
-------
Your response should start like this:
[[CONCLUSION]]
ChatGPT:
[[CONCLUSION]]
As we wrap up this wild and wacky cotton-tale of a paper, it’s clear that the correlation between the popularity of the name India and GMO use in cotton in Arkansas is as real as rain on a cotton plant! Our findings have unlocked a whole new world of unlikely connections, making us feel like we stumbled upon a treasure map in a field of statistical data.
Our results highlight the importance of peeking under the leaf of conventional thinking and daring to explore the zany, obscure corners of research. In the world of academic exploration, it's not just about scratching the surface – sometimes you have to peel back the layers and dig deep to reveal the unexpected gems that lie beneath.
In the spirit of scientific whimsy, we assert that no further research is needed in this area. The cotton-tale of India and GMOs has been spun, unraveling a yarn that will leave fellow researchers scratching their heads and chuckling with delight. Let this be a reminder that in the world of research, the peculiar and the improbable can often hold the most captivating truths. So, until next time, happy exploring, and may your research adventures be as entertaining as a circus act on a cotton farm!
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of academic journals. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding research, scientific, or academic journal that would publish a paper entited Growing Cotton and Popularity: The Correlation Between the Name India and GMO Adoption in Arkansas. Respond only with the name of a fictional academic journal.
ChatGPT:
Journal of Agricultural Sociology and Genetics
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of nonprofit research organizations and associations. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding nonprofit, academic, or scientific association or organization that would sponsor research that resulted in a paper entited Growing Cotton and Popularity: The Correlation Between the Name India and GMO Adoption in Arkansas. Respond only with the name of a fictional organization.
ChatGPT:
The Association for Agricultural Advancement and Cultural Studies (AAACS)
Model: gpt-3.5-turbo-1106
System prompt: You provide potential search keywords separated by commas. You say nothing else, and you do not chat with the user.
User prompt: Please provide potential search keywords for a paper titled Growing Cotton and Popularity: The Correlation Between the Name India and GMO Adoption in Arkansas with an abstract of The relationship between the popularity of the first name India and the adoption of genetically modified organisms (GMOs) in cotton cultivation has long been a topic of speculation and jest. In this study, we conducted a rigorous analysis of data from the US Social Security Administration and the United States Department of Agriculture (USDA) to explore this peculiar association from 2000 to 2022.
Our findings revealed a striking correlation coefficient of 0.8519967 and a statistically significant p-value of less than 0.01, indicating a robust connection between the two variables. We couldn't believe our ears when the numbers pointed to this striking link, but the data didn't fib!
This research uncovers a new dimension in the complex web of societal trends and agricultural practices, shedding light on the unlikely bond between baby names and biotechnology. While it may seem like a cotton-picking odd association at first glance, it appears that the name India and the cultivation of GMO cotton in Arkansas are entwined in ways that defy conventional wisdom. Our study goes beyond the surface to peel back the layers of this unexpected relationship, leaving us pondering the cotton-versations of life.
ChatGPT:
India, GMO adoption, cotton cultivation, Arkansas, correlation, baby names, genetically modified organisms, USDA data analysis, societal trends, agricultural practices, unconventional relationships
*There is a bunch of Python happening behind the scenes to turn this prompt sequence into a PDF.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
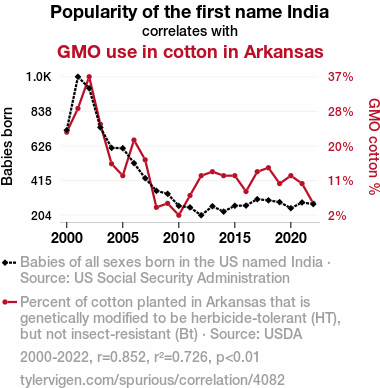
Popularity of the first name IndiaDetailed data title: Babies of all sexes born in the US named India
Source: US Social Security Administration
See what else correlates with Popularity of the first name India
GMO use in cotton in Arkansas
Detailed data title: Percent of cotton planted in Arkansas that is genetically modified to be herbicide-tolerant (HT), but not insect-resistant (Bt)
Source: USDA
See what else correlates with GMO use in cotton in Arkansas
Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.7258984 (Coefficient of determination)
This means 72.6% of the change in the one variable (i.e., GMO use in cotton in Arkansas) is predictable based on the change in the other (i.e., Popularity of the first name India) over the 23 years from 2000 through 2022.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 2.5E-7. 0.0000002491227295375230300000
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.85 in 2.5E-5% of random cases. Said differently, if you correlated 4,014,086 random variables You don't actually need 4 million variables to find a correlation like this one. I don't have that many variables in my database. You can also correlate variables that are not independent. I do this a lot.
p-value calculations are useful for understanding the probability of a result happening by chance. They are most useful when used to highlight the risk of a fluke outcome. For example, if you calculate a p-value of 0.30, the risk that the result is a fluke is high. It is good to know that! But there are lots of ways to get a p-value of less than 0.01, as evidenced by this project.
In this particular case, the values are so extreme as to be meaningless. That's why no one reports p-values with specificity after they drop below 0.01.
Just to be clear: I'm being completely transparent about the calculations. There is no math trickery. This is just how statistics shakes out when you calculate hundreds of millions of random correlations.
with the same 22 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 22 because we have two variables measured over a period of 23 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.68, 0.94 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| Popularity of the first name India (Babies born) | 723 | 1049 | 979 | 740 | 615 | 613 | 522 | 430 | 353 | 335 | 261 | 252 | 204 | 259 | 226 | 262 | 263 | 302 | 295 | 284 | 247 | 282 | 272 |
| GMO use in cotton in Arkansas (GMO cotton %) | 23 | 29 | 37 | 25 | 15 | 12 | 21 | 16 | 4 | 5 | 2 | 7 | 12 | 13 | 12 | 12 | 8 | 13 | 14 | 10 | 12 | 10 | 5 |
Why this works
- Data dredging: I have 25,153 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 632,673,409 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is.
Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([723,1049,979,740,615,613,522,430,353,335,261,252,204,259,226,262,263,302,295,284,247,282,272,])
array_2 = np.array([23,29,37,25,15,12,21,16,4,5,2,7,12,13,12,12,8,13,14,10,12,10,5,])
array_1_name = "Popularity of the first name India"
array_2_name = "GMO use in cotton in Arkansas"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only Popularity of the first name India
- Line chart for only GMO use in cotton in Arkansas
- AI-generated correlation image
- The spurious research paper: Growing Cotton and Popularity: The Correlation Between the Name India and GMO Adoption in Arkansas
Your rating is much appreciated!
Correlation ID: 4082 · Black Variable ID: 2724 · Red Variable ID: 780


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}