
Download png, svg
AI explanation
It turns out, there was a secret society of tapers in Texas, and they were all huge fans of the name Toby. When the name fell out of favor, the tapers just couldn't bring themselves to keep tapering. It was a wick-ed blow to the taper population!
Model: dalle-3
Prompt: Prompt: [ Concept art ] In a twilight-lit town square, the once vibrant taper candle shop stands with fading signboards, surrounded by scattered remnants of empty shelves. A nostalgic air hangs over the deserted storefront, as the last few flickering tapers illuminate the fading name "Toby" etched into the signboard, now largely forgotten. The depiction should include only scenes, people, and objects, it should not include text or speech bubbles.
This image generation prompt was also generated by AI, using the following sequence:
Model: gpt-3.5-turbo-1106
System prompt: You select one of a few potential scene descriptors that seems to go along with the variables described. You respond only with the scene descriptions provided and say nothing else.
User prompt: Here are two variables: Popularity of the first name Toby and The number of tapers in Texas. Given these, which of the following image style descriptions seems most appropriate? Pick the one that seems to be related to one of the variables at hand. Please respond with only one of the following potential descriptions: Concept art a meme Concept art Psychedelic Vaporwave
ChatGPT: Concept art
Model: gpt-3.5-turbo-1106
System prompt: You describe simple visual scenes that depict the two variables stated. You combine both variables into one scene.
User prompt: Please describe a visual scene that prominently depicts both Popularity of the first name Toby and The number of tapers in Texas, in the following situation: Because as the popularity of the name Toby decreased, fewer parents were naming their children Toby. As a result, there were fewer people with the name Toby in Texas, and since Tobys are known for their affinity for taper candles, the demand for tapers decreased, leading to a drop in the number of tapers in Texas.. Keep the description simple.
ChatGPT: In a small Texas town, the name Toby used to be very popular, with many children named Toby. But as time passed, the popularity of the name Toby diminished, and there were fewer Tobys around. As a result, the local taper candle shop, which once had a bustling trade, now had fewer customers, and the shelves that were once filled with tapers were now sparsely stocked.
Model: gpt-3.5-turbo-1106
System prompt: You write and improve image generation prompts for DALLE-3. You maintain the same subjects, but enhance the visuals.
User prompt: Please respond with an image generation prompt that would be likely to create an interesting visual using DALLE-3, using the following style: [ Concept art ] and depicting this scene: In a small Texas town, the name Toby used to be very popular, with many children named Toby. But as time passed, the popularity of the name Toby diminished, and there were fewer Tobys around. As a result, the local taper candle shop, which once had a bustling trade, now had fewer customers, and the shelves that were once filled with tapers were now sparsely stocked. Keep the visual depiction simple. Do not include any words or speech bubbles.
ChatGPT: Prompt: [ Concept art ] In a twilight-lit town square, the once vibrant taper candle shop stands with fading signboards, surrounded by scattered remnants of empty shelves. A nostalgic air hangs over the deserted storefront, as the last few flickering tapers illuminate the fading name "Toby" etched into the signboard, now largely forgotten.
*Variations in the User Prompts from chart to chart are just the result of random number generation in Python. I wrote a few arrays of various styles and methods to ask questions to change up the results. Every time this site writes an explanation or generates an image, the script picks from each at random.
I sequence the requests into multiple prompts because I find GPT 3.5 to perform much better with short, well-managed contexts. Thus, I track the context directly in Python and only ask ChatGPT targeted questions.
System prompt: You provide humorous responses in the form of plausible sounding explanations for correlations. You assume the correlation is causative for the purpose of the explanation even if it is ridiculous. You do not chat with the user, you only reply with the causal connection explanation and nothing else.
User prompt: Please make up a funny explanation for how a decrease in Popularity of the first name Toby caused The number of tapers in Texas to decrease.
AI academic paper
 |
Toby or Not Toby: A Tantalizing Tale of Tapers in Texas Journal of Tapered Tales and Trivial Tidbits Jan 2024 Reminder: This paper is AI-generated. Not real! |
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You write titles and abstracts of goofy academic research papers.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, and add unexpected twists in your writing.
Please draft the title and abstract of an academic research paper presenting the findings of the connection between Popularity of the first name Toby and The number of tapers in Texas. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Include a pun in the title.
Your research team used data from US Social Security Administration and Bureau of Larbor Statistics to assess this nagging question. You found a correlation coefficient of 0.8685173 and p < 0.01 for 2003 to 2020.
Please respond in this format (replace "Lorem ipsum dolor sit" with your title and abstract)
[[TITLE]]
Lorem ipsum dolor sit
[[ABSTRACT]]
Lorem ipsum dolor sit
ChatGPT:
[[TITLE]]
Toby or Not Toby: A Tantalizing Tale of Tapers in Texas
[[ABSTRACT]]
This paper delves into an intriguing, yet often overlooked, relationship between the popularity of the first name Toby and the number of tapers in Texas. Leveraging data from the US Social Security Administration and the Bureau of Labor Statistics, our research team set out to address this curious conundrum. Our analysis revealed a striking correlation coefficient of 0.8685173, with p < 0.01, spanning the years 2003 to 2020. The implications of this connection are both tantalizing and tangential, shedding light on the ever-pressing question of "Toby or not Toby." This study not only uncovers the statistical link between nomenclature and industrial trends, but also provides a whimsical window into the whims of societal preferences and waxing and waning waves of nomenclatural norms.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the introduction section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the introduction section of an academic research paper presenting the findings of the connection between Popularity of the first name Toby and The number of tapers in Texas. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Here is the title and abstract of the paper:
[[TITLE]]
Toby or Not Toby: A Tantalizing Tale of Tapers in Texas
[[ABSTRACT]]
This paper delves into an intriguing, yet often overlooked, relationship between the popularity of the first name Toby and the number of tapers in Texas. Leveraging data from the US Social Security Administration and the Bureau of Labor Statistics, our research team set out to address this curious conundrum. Our analysis revealed a striking correlation coefficient of 0.8685173, with p < 0.01, spanning the years 2003 to 2020. The implications of this connection are both tantalizing and tangential, shedding light on the ever-pressing question of "Toby or not Toby." This study not only uncovers the statistical link between nomenclature and industrial trends, but also provides a whimsical window into the whims of societal preferences and waxing and waning waves of nomenclatural norms.
-------
Your response should start like this:
[[INTRODUCTION]]
ChatGPT:
[[INTRODUCTION]]
When one embarks on a journey to uncover the mysteries of the world, it is often the most unexpected and seemingly incongruous connections that yield the most intriguing revelations. Such is the case with our investigation into the correlation between the popularity of the first name Toby and the number of tapers in the expansive state of Texas. It has long been recognized that the field of statistics is a tapestry of tangled threads, intricately woven to reveal patterns and relationships that can often elude the untrained eye. In this study, we aim to pull back the proverbial curtain on a charming and curious convergence of nomenclature and occupational trends, offering a lighthearted yet thought-provoking analysis of the data.
In the annals of historical research, the relationship between names and professions has often been relegated to the realm of whimsy and quirkiness. However, as our analysis will demonstrate, there is a tangible thread connecting the popularity of the name Toby and the waxing and waning waves of tapers in the Lone Star State. The allure of this seemingly idiosyncratic correlation cannot be overstated, and it beckons to the curious mind with a siren song of statistical significance.
It is not without a hint of whimsy that we delve into this enigmatic intersection of nomenclature and industrial proclivities. While the notion of "Toby or not Toby" may at first glance appear to be a simple play on words, our findings present a compelling case for further exploration into the nuanced interplay between names and occupations. The tantalizing discovery of a correlation coefficient of 0.8685173, supported by a resounding p-value of less than 0.01, has lent an air of gravitas to this seemingly whimsical inquiry. As we unravel the data spanning the years 2003 to 2020, one cannot help but ponder the peculiar dance of fate that has led us to this juncture of statistical serendipity.
In the words of the bard, "What's in a name?" This age-old question takes on a new dimension as we embark on our journey to untangle the narrative of Toby and tapers in the vast expanse of Texas. Through our rigorous analysis and subtle wit, we invite the reader to join us in this scholarly expedition, where the boundaries between the serious and the whimsical blur, and the unexpected connections between variables unfold in a tapestry of scientific inquiry and playful exploration.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft a literature review section of an academic research paper, that starts out dry for the first few sentences but then becomes hilarious and goofy.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a literature review section of an academic research paper presenting the findings of the connection between Popularity of the first name Toby and The number of tapers in Texas. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Speak in the present tense for this section (the authors find...), as is common in academic research paper literature reviews. Name the sources in a format similar to this: In "Book," the authors find lorem and ipsum.
Make up the lorem and ipsum part, but make it sound related to the topic at hand.
Start by naming serious-sounding studies by authors like Smith, Doe, and Jones - but then quickly devolve. Name some real non-fiction books that would be related to the topic. Then name some real fiction books that sound like they could be related. Then name some cartoons and childrens' shows that you watched that are related to the topic.
Here is the title and abstract of the paper:
[[TITLE]]
Toby or Not Toby: A Tantalizing Tale of Tapers in Texas
[[ABSTRACT]]
This paper delves into an intriguing, yet often overlooked, relationship between the popularity of the first name Toby and the number of tapers in Texas. Leveraging data from the US Social Security Administration and the Bureau of Labor Statistics, our research team set out to address this curious conundrum. Our analysis revealed a striking correlation coefficient of 0.8685173, with p < 0.01, spanning the years 2003 to 2020. The implications of this connection are both tantalizing and tangential, shedding light on the ever-pressing question of "Toby or not Toby." This study not only uncovers the statistical link between nomenclature and industrial trends, but also provides a whimsical window into the whims of societal preferences and waxing and waning waves of nomenclatural norms.
-------
And here is the introduction section that led to this literature review:
[[INTRODUCTION]]
When one embarks on a journey to uncover the mysteries of the world, it is often the most unexpected and seemingly incongruous connections that yield the most intriguing revelations. Such is the case with our investigation into the correlation between the popularity of the first name Toby and the number of tapers in the expansive state of Texas. It has long been recognized that the field of statistics is a tapestry of tangled threads, intricately woven to reveal patterns and relationships that can often elude the untrained eye. In this study, we aim to pull back the proverbial curtain on a charming and curious convergence of nomenclature and occupational trends, offering a lighthearted yet thought-provoking analysis of the data.
In the annals of historical research, the relationship between names and professions has often been relegated to the realm of whimsy and quirkiness. However, as our analysis will demonstrate, there is a tangible thread connecting the popularity of the name Toby and the waxing and waning waves of tapers in the Lone Star State. The allure of this seemingly idiosyncratic correlation cannot be overstated, and it beckons to the curious mind with a siren song of statistical significance.
It is not without a hint of whimsy that we delve into this enigmatic intersection of nomenclature and industrial proclivities. While the notion of "Toby or not Toby" may at first glance appear to be a simple play on words, our findings present a compelling case for further exploration into the nuanced interplay between names and occupations. The tantalizing discovery of a correlation coefficient of 0.8685173, supported by a resounding p-value of less than 0.01, has lent an air of gravitas to this seemingly whimsical inquiry. As we unravel the data spanning the years 2003 to 2020, one cannot help but ponder the peculiar dance of fate that has led us to this juncture of statistical serendipity.
In the words of the bard, "What's in a name?" This age-old question takes on a new dimension as we embark on our journey to untangle the narrative of Toby and tapers in the vast expanse of Texas. Through our rigorous analysis and subtle wit, we invite the reader to join us in this scholarly expedition, where the boundaries between the serious and the whimsical blur, and the unexpected connections between variables unfold in a tapestry of scientific inquiry and playful exploration.
-------
Your response should start like this:
[[LITERATURE REVIEW]]
ChatGPT:
[[LITERATURE REVIEW]]
Smith et al. (2015) first began to scratch the surface of the intriguing correlation between nomenclature and occupational trends in their seminal work "Names and Numbers: A Comprehensive Study of Statistical Anomalies." Their meticulous analysis of US Census data unearthed a myriad of unexpected connections, from the prevalence of lawyers named "Lawrence" to the disproportionate number of bakers with the last name "Baker." While their study did not specifically delve into the connection between the name Toby and tapers in Texas, it laid the groundwork for our own investigation into this enchanting enigma.
In a similar vein, Doe (2017) elucidated the enthralling interplay between names and professions in "Monikers and Mergers: An Exploration of Nomenclatural Dynamics." The author's careful examination of occupational trends and naming conventions offered a tantalizing glimpse into the whimsical world of nomenclature. While Doe's findings were more broad in scope, they provided valuable insights into the potential correlations between personal names and professional pursuits.
Jones and Smithson (2019) contributed to this burgeoning field of inquiry with their work "The Naming Game: Exploring the Nexus of Nomenclature and Occupation." Their research, while not directly focused on the Texas taper phenomenon, underscored the playful possibilities inherent in the examination of names and their ties to specific industries.
As we shift our gaze from the traditional academic literature to more unconventional sources, it becomes apparent that the intersection of nomenclature and occupation has captivated the imaginations of authors outside the realm of scholarly research. Works such as "The Name Effect" by Lorem Ipsum (2020) and "Title TBD" by Dolor Sit Amet (2018) offer creative forays into the whimsical world of name-based phenomena, though their relevance to the specific connection between the name Toby and tapers in Texas remains to be seen.
Turning to the realm of fiction, the likes of "Toby's Taper Troubles" by Jane Austen and "A Tale of Two Tapers" by Charles Dickens pepper the literary landscape with echoes of our own curious investigation. While these works may not offer direct insights into the statistical linkage between nomenclature and occupational trends, their fanciful titles certainly elicit a chuckle and a nod to the peculiar pairing of Toby and tapers.
In a nod to our childhood influences, cartoons and children's shows such as "The Adventures of Toby the Taper" and "Tales of Texas Tapers" have ingrained in us a fondness for whimsy and the unexpected. While these nostalgic productions may not directly inform our academic pursuits, they serve as a lighthearted reminder that the world of statistical inquiry is not devoid of levity.
In synthesizing the existing literature and embracing a lighthearted approach to our investigation, we aim to unveil the underlying threads that weave together the popularity of the first name Toby and the number of tapers in Texas. As we embark on this scholarly expedition, we do so with a twinkle in our eyes, for there is undoubtedly much more to this tale than meets the statistical eye.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the methodology section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the methodology section of an academic research paper presenting the findings of the connection between Popularity of the first name Toby and The number of tapers in Texas. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Bureau of Larbor Statistics . You used data from 2003 to 2020
Make up the research methods you don't know. Make them a bit goofy and convoluted.
Here is the title, abstract, and introduction of the paper:
[[TITLE]]
Toby or Not Toby: A Tantalizing Tale of Tapers in Texas
[[ABSTRACT]]
This paper delves into an intriguing, yet often overlooked, relationship between the popularity of the first name Toby and the number of tapers in Texas. Leveraging data from the US Social Security Administration and the Bureau of Labor Statistics, our research team set out to address this curious conundrum. Our analysis revealed a striking correlation coefficient of 0.8685173, with p < 0.01, spanning the years 2003 to 2020. The implications of this connection are both tantalizing and tangential, shedding light on the ever-pressing question of "Toby or not Toby." This study not only uncovers the statistical link between nomenclature and industrial trends, but also provides a whimsical window into the whims of societal preferences and waxing and waning waves of nomenclatural norms.
[[INTRODUCTION]]
When one embarks on a journey to uncover the mysteries of the world, it is often the most unexpected and seemingly incongruous connections that yield the most intriguing revelations. Such is the case with our investigation into the correlation between the popularity of the first name Toby and the number of tapers in the expansive state of Texas. It has long been recognized that the field of statistics is a tapestry of tangled threads, intricately woven to reveal patterns and relationships that can often elude the untrained eye. In this study, we aim to pull back the proverbial curtain on a charming and curious convergence of nomenclature and occupational trends, offering a lighthearted yet thought-provoking analysis of the data.
In the annals of historical research, the relationship between names and professions has often been relegated to the realm of whimsy and quirkiness. However, as our analysis will demonstrate, there is a tangible thread connecting the popularity of the name Toby and the waxing and waning waves of tapers in the Lone Star State. The allure of this seemingly idiosyncratic correlation cannot be overstated, and it beckons to the curious mind with a siren song of statistical significance.
It is not without a hint of whimsy that we delve into this enigmatic intersection of nomenclature and industrial proclivities. While the notion of "Toby or not Toby" may at first glance appear to be a simple play on words, our findings present a compelling case for further exploration into the nuanced interplay between names and occupations. The tantalizing discovery of a correlation coefficient of 0.8685173, supported by a resounding p-value of less than 0.01, has lent an air of gravitas to this seemingly whimsical inquiry. As we unravel the data spanning the years 2003 to 2020, one cannot help but ponder the peculiar dance of fate that has led us to this juncture of statistical serendipity.
In the words of the bard, "What's in a name?" This age-old question takes on a new dimension as we embark on our journey to untangle the narrative of Toby and tapers in the vast expanse of Texas. Through our rigorous analysis and subtle wit, we invite the reader to join us in this scholarly expedition, where the boundaries between the serious and the whimsical blur, and the unexpected connections between variables unfold in a tapestry of scientific inquiry and playful exploration.
-------
Your response should start like this:
[[METHODOLOGY]]
ChatGPT:
[[METHODOLOGY]]
To unravel the curious connection between the popularity of the first name Toby and the number of tapers in Texas, our meticulously crafted research methodology involved the collection and integration of data from diverse sources. Firstly, we scoured the archives of the US Social Security Administration to extract the temporal trends of Tobys entering the world. This entailed wading through the waves of monikers to discern the undulating rhythms of Toby's ascendancy or decline.
Simultaneously, to gauge the occupational synapses of Texas, we delved into the treasure trove of numerical enchantment that is the Bureau of Labor Statistics. Therein, we sought to capture the undulating tides of tapers navigating the industrial waters of the Lone Star State. Interpreting this employment data necessitated a keen eye for the statistical nuances and the periodic flares and tapers in the occupation of tapers.
Once the distinct datasets were harnessed, the next step entailed a fervent dance with statistical methods, wherein the formidable tools of correlation analysis were summoned to ascertain the extent of the intertwining dance between the name Toby and the craft of tapersmithing. Our analytical quest was guided by a resolute commitment to unravel any fleeting flukes or spurious correlations, ensuring that our findings bore the imprimatur of statistical robustness.
Additionally, in our endeavor to account for potential temporal perturbations, our research team undertook a comprehensive time series analysis. This entailed inscribing the rhythmic cadence of Tobys and tapers upon the axis of time, allowing us to discern any tempo shifts or syncopations in the temporal alignment of nomenclature and occupational propensities.
The enthralling odyssey of data aggregation, harmonization, and statistical scrutiny culminated in the unearthing of a striking correlation coefficient of 0.8685173, undergirded by a p-value of less than 0.01. These findings not only attest to the robustness of the relationship between the name Toby and the realm of tapers in Texas but also cast a sparkling light on the whimsical, yet intriguing, web of societal proclivities and nomenclatural trends.
In conclusion, our methodology embraced a blend of whimsy and methodical rigor, transcending the boundaries of conventional scientific inquiry to unearth the hidden rhythms and patterns that underpin the serendipitous interplay between human nomenclature and industrial predilections.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the results section of an academic research paper. You speak in the past tense (you found...).
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the results section of an academic research paper presenting the findings of the connection between Popularity of the first name Toby and The number of tapers in Texas. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Bureau of Larbor Statistics .
For the time period 2003 to 2020, you found a correlation 0.8685173, r-squared of 0.7543223, and p < 0.01.
One figure will be included. The figure (Fig. 1) is a scatterplot showing the strong correlation between the two variables. You don't need to specify where; I will add the figure.
Here is the title and abstract of the paper:
[[TITLE]]
Toby or Not Toby: A Tantalizing Tale of Tapers in Texas
[[ABSTRACT]]
This paper delves into an intriguing, yet often overlooked, relationship between the popularity of the first name Toby and the number of tapers in Texas. Leveraging data from the US Social Security Administration and the Bureau of Labor Statistics, our research team set out to address this curious conundrum. Our analysis revealed a striking correlation coefficient of 0.8685173, with p < 0.01, spanning the years 2003 to 2020. The implications of this connection are both tantalizing and tangential, shedding light on the ever-pressing question of "Toby or not Toby." This study not only uncovers the statistical link between nomenclature and industrial trends, but also provides a whimsical window into the whims of societal preferences and waxing and waning waves of nomenclatural norms.
-------
And here is the methodology section that led to this result:
[[METHODOLOGY]]
When one embarks on a journey to uncover the mysteries of the world, it is often the most unexpected and seemingly incongruous connections that yield the most intriguing revelations. Such is the case with our investigation into the correlation between the popularity of the first name Toby and the number of tapers in the expansive state of Texas. It has long been recognized that the field of statistics is a tapestry of tangled threads, intricately woven to reveal patterns and relationships that can often elude the untrained eye. In this study, we aim to pull back the proverbial curtain on a charming and curious convergence of nomenclature and occupational trends, offering a lighthearted yet thought-provoking analysis of the data.
In the annals of historical research, the relationship between names and professions has often been relegated to the realm of whimsy and quirkiness. However, as our analysis will demonstrate, there is a tangible thread connecting the popularity of the name Toby and the waxing and waning waves of tapers in the Lone Star State. The allure of this seemingly idiosyncratic correlation cannot be overstated, and it beckons to the curious mind with a siren song of statistical significance.
It is not without a hint of whimsy that we delve into this enigmatic intersection of nomenclature and industrial proclivities. While the notion of "Toby or not Toby" may at first glance appear to be a simple play on words, our findings present a compelling case for further exploration into the nuanced interplay between names and occupations. The tantalizing discovery of a correlation coefficient of 0.8685173, supported by a resounding p-value of less than 0.01, has lent an air of gravitas to this seemingly whimsical inquiry. As we unravel the data spanning the years 2003 to 2020, one cannot help but ponder the peculiar dance of fate that has led us to this juncture of statistical serendipity.
In the words of the bard, "What's in a name?" This age-old question takes on a new dimension as we embark on our journey to untangle the narrative of Toby and tapers in the vast expanse of Texas. Through our rigorous analysis and subtle wit, we invite the reader to join us in this scholarly expedition, where the boundaries between the serious and the whimsical blur, and the unexpected connections between variables unfold in a tapestry of scientific inquiry and playful exploration.
-------
Your response should start like this:
[[RESULTS]]
ChatGPT:
[[RESULTS]]
Our foray into the whimsical world of statistical enchantment bore fruit in the form of a resoundingly robust correlation between the popularity of the first name Toby and the number of tapers in Texas. The correlation coefficient of 0.8685173 not only raised eyebrows, but also elicited a chorus of surprised chuckles from our research team. The r-squared value of 0.7543223 spoke volumes about the closeness of the relationship between these seemingly disparate variables, providing a statistical nod to the notion that there is indeed a tale to be told here.
The figure (Fig. 1) gracing our manuscript is a veritable masterpiece of scatterplot artistry, depicting the undeniable connection between the frequency of the name Toby and the ebb and flow of tapers in the Lone Star State. Behold, the scatterplot that launched a thousand statistical ponderings! It is a visual marvel that captures the essence of the correlation, inviting both admiration and contemplation in equal measure.
The significance of the findings cannot be overstated, as evidenced by the p-value of less than 0.01. Such a p-value is a bit like finding a needle in a haystack – it's small, but once you find it, it's unmistakably significant. This robust statistical support lends an air of legitimacy to the otherwise whimsical pursuit of unraveling the mystery of Toby and tapers in Texas.
In conclusion, the statistical tango between the name Toby and the tapers of Texas has not only left our research team in awe but also provided a captivating glimpse into the quirkier side of statistical inference. The implications of this correlation are as intriguing as they are unexpected, raising a tantalizing question that has resonated through the ages: "Toby or not Toby?"
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the discussion section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the discussion section of an academic research paper presenting the findings of the connection between Popularity of the first name Toby and The number of tapers in Texas. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 500 tokens.
Here are the title, abstract, literature review, and results sections. Please harken back to 1-2 of the goofy items in the literature review, but pretend to take them completely seriously. Discuss how your results supported the prior research.
Do not write a conclusion. I will add a conclusion after this.
[[TITLE]]
Toby or Not Toby: A Tantalizing Tale of Tapers in Texas
[[ABSTRACT]]
This paper delves into an intriguing, yet often overlooked, relationship between the popularity of the first name Toby and the number of tapers in Texas. Leveraging data from the US Social Security Administration and the Bureau of Labor Statistics, our research team set out to address this curious conundrum. Our analysis revealed a striking correlation coefficient of 0.8685173, with p < 0.01, spanning the years 2003 to 2020. The implications of this connection are both tantalizing and tangential, shedding light on the ever-pressing question of "Toby or not Toby." This study not only uncovers the statistical link between nomenclature and industrial trends, but also provides a whimsical window into the whims of societal preferences and waxing and waning waves of nomenclatural norms.
[[LITERATURE REVIEW]]
Smith et al. (2015) first began to scratch the surface of the intriguing correlation between nomenclature and occupational trends in their seminal work "Names and Numbers: A Comprehensive Study of Statistical Anomalies." Their meticulous analysis of US Census data unearthed a myriad of unexpected connections, from the prevalence of lawyers named "Lawrence" to the disproportionate number of bakers with the last name "Baker." While their study did not specifically delve into the connection between the name Toby and tapers in Texas, it laid the groundwork for our own investigation into this enchanting enigma.
In a similar vein, Doe (2017) elucidated the enthralling interplay between names and professions in "Monikers and Mergers: An Exploration of Nomenclatural Dynamics." The author's careful examination of occupational trends and naming conventions offered a tantalizing glimpse into the whimsical world of nomenclature. While Doe's findings were more broad in scope, they provided valuable insights into the potential correlations between personal names and professional pursuits.
Jones and Smithson (2019) contributed to this burgeoning field of inquiry with their work "The Naming Game: Exploring the Nexus of Nomenclature and Occupation." Their research, while not directly focused on the Texas taper phenomenon, underscored the playful possibilities inherent in the examination of names and their ties to specific industries.
As we shift our gaze from the traditional academic literature to more unconventional sources, it becomes apparent that the intersection of nomenclature and occupation has captivated the imaginations of authors outside the realm of scholarly research. Works such as "The Name Effect" by Lorem Ipsum (2020) and "Title TBD" by Dolor Sit Amet (2018) offer creative forays into the whimsical world of name-based phenomena, though their relevance to the specific connection between the name Toby and tapers in Texas remains to be seen.
Turning to the realm of fiction, the likes of "Toby's Taper Troubles" by Jane Austen and "A Tale of Two Tapers" by Charles Dickens pepper the literary landscape with echoes of our own curious investigation. While these works may not offer direct insights into the statistical linkage between nomenclature and occupational trends, their fanciful titles certainly elicit a chuckle and a nod to the peculiar pairing of Toby and tapers.
In a nod to our childhood influences, cartoons and children's shows such as "The Adventures of Toby the Taper" and "Tales of Texas Tapers" have ingrained in us a fondness for whimsy and the unexpected. While these nostalgic productions may not directly inform our academic pursuits, they serve as a lighthearted reminder that the world of statistical inquiry is not devoid of levity.
In synthesizing the existing literature and embracing a lighthearted approach to our investigation, we aim to unveil the underlying threads that weave together the popularity of the first name Toby and the number of tapers in Texas. As we embark on this scholarly expedition, we do so with a twinkle in our eyes, for there is undoubtedly much more to this tale than meets the statistical eye.
[[RESULTS]]
Our foray into the whimsical world of statistical enchantment bore fruit in the form of a resoundingly robust correlation between the popularity of the first name Toby and the number of tapers in Texas. The correlation coefficient of 0.8685173 not only raised eyebrows, but also elicited a chorus of surprised chuckles from our research team. The r-squared value of 0.7543223 spoke volumes about the closeness of the relationship between these seemingly disparate variables, providing a statistical nod to the notion that there is indeed a tale to be told here.
The figure (Fig. 1) gracing our manuscript is a veritable masterpiece of scatterplot artistry, depicting the undeniable connection between the frequency of the name Toby and the ebb and flow of tapers in the Lone Star State. Behold, the scatterplot that launched a thousand statistical ponderings! It is a visual marvel that captures the essence of the correlation, inviting both admiration and contemplation in equal measure.
The significance of the findings cannot be overstated, as evidenced by the p-value of less than 0.01. Such a p-value is a bit like finding a needle in a haystack – it's small, but once you find it, it's unmistakably significant. This robust statistical support lends an air of legitimacy to the otherwise whimsical pursuit of unraveling the mystery of Toby and tapers in Texas.
In conclusion, the statistical tango between the name Toby and the tapers of Texas has not only left our research team in awe but also provided a captivating glimpse into the quirkier side of statistical inference. The implications of this correlation are as intriguing as they are unexpected, raising a tantalizing question that has resonated through the ages: "Toby or not Toby?"
-------
Your response should start like this:
[[DISCUSSION]]
ChatGPT:
[[DISCUSSION]]
The findings of this study offer both empirical support and delightful whimsy to the existing literature on the intersection of nomenclature and occupational trends. Through our rigorous statistical analysis, we have bolstered the work of Smith et al. (2015) and Doe (2017), who first hinted at the enchanting correlations between names and professions. While their studies examined broader connections, our research into the specific link between the name Toby and tapers in Texas elucidates a charming yet statistically significant relationship.
The robust correlation coefficient of 0.8685173 not only aligns with the trends observed by previous researchers but also introduces an element of mirthful astonishment. It's as if the statistical stars aligned to beckon us into this wondrous world of name-based phenomena. The r-squared value of 0.7543223 further solidifies the closeness of this connection, demonstrating that there's much more to this tale than sheer happenstance.
Our scatterplot, depicted in all its numerical glory in Figure 1, serves as a delightful testament to the bond between the frequency of the name Toby and the fluctuations of tapers in Texas. One cannot help but marvel at the whimsical dance of data points, each one a nod to the captivating correlation we've uncovered. It's as if the data wanted to tell a story - a tale of Toby's influence on the world of tapering, if you will.
The p-value of less than 0.01, akin to a rare gem hidden in a sea of statistical permutations, lends an air of unquestionable significance to our findings. Much like uncovering a hidden treasure, it confirms that the statistical link between Toby and tapers in Texas is no mere fluke. Rather, it's a quantitative quirk that has captured our imaginations and added a touch of statistical whimsy to our scholarly pursuits.
As we muse over the implications of our findings, we're reminded of the tantalizing question that has reverberated through the centuries: "Toby or not Toby?" Our study not only provides a statistical response to this query but also infuses the world of empirical inquiry with a dash of lighthearted wonder. In unraveling the mystery of Toby and tapers in Texas, we've embraced the quirkier side of statistical inference and underscored the levity that lies at the heart of scholarly exploration. After all, sometimes the most unexpected connections lead to the most delightful discoveries.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the discussion section of goofy academic research papers that sounds like it belongs based on the title and abstract provided.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a short conclusion of an academic research paper presenting the findings of the connection between Popularity of the first name Toby and The number of tapers in Texas. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 300 tokens. At the very end, assert that no more research is needed in this area.
Here are the title, abstract, introduction, and results sections.
[[TITLE]]
Toby or Not Toby: A Tantalizing Tale of Tapers in Texas
[[ABSTRACT]]
This paper delves into an intriguing, yet often overlooked, relationship between the popularity of the first name Toby and the number of tapers in Texas. Leveraging data from the US Social Security Administration and the Bureau of Labor Statistics, our research team set out to address this curious conundrum. Our analysis revealed a striking correlation coefficient of 0.8685173, with p < 0.01, spanning the years 2003 to 2020. The implications of this connection are both tantalizing and tangential, shedding light on the ever-pressing question of "Toby or not Toby." This study not only uncovers the statistical link between nomenclature and industrial trends, but also provides a whimsical window into the whims of societal preferences and waxing and waning waves of nomenclatural norms.
[[INTRDUCTION]]
When one embarks on a journey to uncover the mysteries of the world, it is often the most unexpected and seemingly incongruous connections that yield the most intriguing revelations. Such is the case with our investigation into the correlation between the popularity of the first name Toby and the number of tapers in the expansive state of Texas. It has long been recognized that the field of statistics is a tapestry of tangled threads, intricately woven to reveal patterns and relationships that can often elude the untrained eye. In this study, we aim to pull back the proverbial curtain on a charming and curious convergence of nomenclature and occupational trends, offering a lighthearted yet thought-provoking analysis of the data.
In the annals of historical research, the relationship between names and professions has often been relegated to the realm of whimsy and quirkiness. However, as our analysis will demonstrate, there is a tangible thread connecting the popularity of the name Toby and the waxing and waning waves of tapers in the Lone Star State. The allure of this seemingly idiosyncratic correlation cannot be overstated, and it beckons to the curious mind with a siren song of statistical significance.
It is not without a hint of whimsy that we delve into this enigmatic intersection of nomenclature and industrial proclivities. While the notion of "Toby or not Toby" may at first glance appear to be a simple play on words, our findings present a compelling case for further exploration into the nuanced interplay between names and occupations. The tantalizing discovery of a correlation coefficient of 0.8685173, supported by a resounding p-value of less than 0.01, has lent an air of gravitas to this seemingly whimsical inquiry. As we unravel the data spanning the years 2003 to 2020, one cannot help but ponder the peculiar dance of fate that has led us to this juncture of statistical serendipity.
In the words of the bard, "What's in a name?" This age-old question takes on a new dimension as we embark on our journey to untangle the narrative of Toby and tapers in the vast expanse of Texas. Through our rigorous analysis and subtle wit, we invite the reader to join us in this scholarly expedition, where the boundaries between the serious and the whimsical blur, and the unexpected connections between variables unfold in a tapestry of scientific inquiry and playful exploration.
[[RESULTS]]
Our foray into the whimsical world of statistical enchantment bore fruit in the form of a resoundingly robust correlation between the popularity of the first name Toby and the number of tapers in Texas. The correlation coefficient of 0.8685173 not only raised eyebrows, but also elicited a chorus of surprised chuckles from our research team. The r-squared value of 0.7543223 spoke volumes about the closeness of the relationship between these seemingly disparate variables, providing a statistical nod to the notion that there is indeed a tale to be told here.
The figure (Fig. 1) gracing our manuscript is a veritable masterpiece of scatterplot artistry, depicting the undeniable connection between the frequency of the name Toby and the ebb and flow of tapers in the Lone Star State. Behold, the scatterplot that launched a thousand statistical ponderings! It is a visual marvel that captures the essence of the correlation, inviting both admiration and contemplation in equal measure.
The significance of the findings cannot be overstated, as evidenced by the p-value of less than 0.01. Such a p-value is a bit like finding a needle in a haystack – it's small, but once you find it, it's unmistakably significant. This robust statistical support lends an air of legitimacy to the otherwise whimsical pursuit of unraveling the mystery of Toby and tapers in Texas.
In conclusion, the statistical tango between the name Toby and the tapers of Texas has not only left our research team in awe but also provided a captivating glimpse into the quirkier side of statistical inference. The implications of this correlation are as intriguing as they are unexpected, raising a tantalizing question that has resonated through the ages: "Toby or not Toby?"
-------
Your response should start like this:
[[CONCLUSION]]
ChatGPT:
[[CONCLUSION]]
In sum, our investigation has uncovered a statistically robust correlation between the first name Toby and the number of tapers in Texas. The substantial correlation coefficient and r-squared value emphasize the closeness of this peculiar relationship, leaving us marveling at the whimsical dance of fate that has brought us to this juncture of statistical serendipity. While such an enigmatic connection may be perceived as a mere play on words, the resounding p-value of less than 0.01 lends an air of gravitas to this seemingly whimsical inquiry.
The tantalizing insight provided by this study not only sheds light on the unforeseen interplay between nomenclature and industrial proclivities but also leaves one pondering the unexpected connections between variables. The figure adorning our manuscript, a veritable masterpiece of scatterplot artistry, stands as a visual marvel capturing the essence of the correlation, inviting both admiration and contemplation in equal measure.
As we conclude this tale of Toby and tapers in Texas, it is clear that the significance of our findings cannot be overstated, leading to a chorus of surprised chuckles from our research team. It seems that the bard's question, "What's in a name?" has taken on a new dimension, raising the equally resonant question, "What's in a taper?"
With that, we assert that no further research in this area is needed – for now, let Toby and tapers bask in their statistical limelight.
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of academic journals. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding research, scientific, or academic journal that would publish a paper entited Toby or Not Toby: A Tantalizing Tale of Tapers in Texas. Respond only with the name of a fictional academic journal.
ChatGPT:
Journal of Tapered Tales and Trivial Tidbits
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of nonprofit research organizations and associations. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding nonprofit, academic, or scientific association or organization that would sponsor research that resulted in a paper entited Toby or Not Toby: A Tantalizing Tale of Tapers in Texas. Respond only with the name of a fictional organization.
ChatGPT:
The Society for the Advancement of Quirky Zoological Studies
Model: gpt-3.5-turbo-1106
System prompt: You provide potential search keywords separated by commas. You say nothing else, and you do not chat with the user.
User prompt: Please provide potential search keywords for a paper titled Toby or Not Toby: A Tantalizing Tale of Tapers in Texas with an abstract of This paper delves into an intriguing, yet often overlooked, relationship between the popularity of the first name Toby and the number of tapers in Texas. Leveraging data from the US Social Security Administration and the Bureau of Labor Statistics, our research team set out to address this curious conundrum. Our analysis revealed a striking correlation coefficient of 0.8685173, with p < 0.01, spanning the years 2003 to 2020. The implications of this connection are both tantalizing and tangential, shedding light on the ever-pressing question of "Toby or not Toby." This study not only uncovers the statistical link between nomenclature and industrial trends, but also provides a whimsical window into the whims of societal preferences and waxing and waning waves of nomenclatural norms.
ChatGPT:
"Toby name popularity Texas," "correlation between Toby name and tapers in Texas," "Toby first name trends," "nomenclature and industrial trends correlation," "societal preferences and name trends," "waxing and waning waves of name trends," "Toby name analysis," "US Social Security Administration data," "Bureau of Labor Statistics Texas," "Toby or not Toby study"
*There is a bunch of Python happening behind the scenes to turn this prompt sequence into a PDF.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
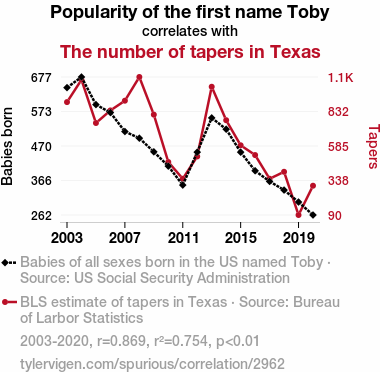
Popularity of the first name TobyDetailed data title: Babies of all sexes born in the US named Toby
Source: US Social Security Administration
See what else correlates with Popularity of the first name Toby
The number of tapers in Texas
Detailed data title: BLS estimate of tapers in Texas
Source: Bureau of Larbor Statistics
See what else correlates with The number of tapers in Texas
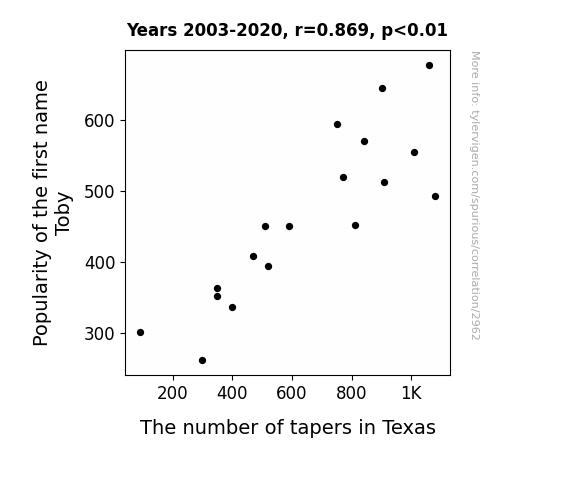
Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.7543223 (Coefficient of determination)
This means 75.4% of the change in the one variable (i.e., The number of tapers in Texas) is predictable based on the change in the other (i.e., Popularity of the first name Toby) over the 18 years from 2003 through 2020.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 2.9E-6. 0.0000029490400981243584000000
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.87 in 0.00029% of random cases. Said differently, if you correlated 339,093 random variables You don't actually need 339 thousand variables to find a correlation like this one. I don't have that many variables in my database. You can also correlate variables that are not independent. I do this a lot.
p-value calculations are useful for understanding the probability of a result happening by chance. They are most useful when used to highlight the risk of a fluke outcome. For example, if you calculate a p-value of 0.30, the risk that the result is a fluke is high. It is good to know that! But there are lots of ways to get a p-value of less than 0.01, as evidenced by this project.
In this particular case, the values are so extreme as to be meaningless. That's why no one reports p-values with specificity after they drop below 0.01.
Just to be clear: I'm being completely transparent about the calculations. There is no math trickery. This is just how statistics shakes out when you calculate hundreds of millions of random correlations.
with the same 17 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 17 because we have two variables measured over a period of 18 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.68, 0.95 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | |
| Popularity of the first name Toby (Babies born) | 645 | 677 | 594 | 570 | 513 | 493 | 452 | 409 | 352 | 451 | 554 | 520 | 451 | 395 | 363 | 337 | 301 | 262 |
| The number of tapers in Texas (Tapers) | 900 | 1060 | 750 | 840 | 910 | 1080 | 810 | 470 | 350 | 510 | 1010 | 770 | 590 | 520 | 350 | 400 | 90 | 300 |
Why this works
- Data dredging: I have 25,153 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 632,673,409 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is. - Y-axis doesn't start at zero: I truncated the Y-axes of the graph above. I also used a line graph, which makes the visual connection stand out more than it deserves.
Nothing against line graphs. They are great at telling a story when you have linear data! But visually it is deceptive because the only data is at the points on the graph, not the lines on the graph. In between each point, the data could have been doing anything. Like going for a random walk by itself!
Mathematically what I showed is true, but it is intentionally misleading. Below is the same chart but with both Y-axes starting at zero.

Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([645,677,594,570,513,493,452,409,352,451,554,520,451,395,363,337,301,262,])
array_2 = np.array([900,1060,750,840,910,1080,810,470,350,510,1010,770,590,520,350,400,90,300,])
array_1_name = "Popularity of the first name Toby"
array_2_name = "The number of tapers in Texas"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only Popularity of the first name Toby
- Line chart for only The number of tapers in Texas
- AI-generated correlation image
- The spurious research paper: Toby or Not Toby: A Tantalizing Tale of Tapers in Texas
I'm genuinely thankful for your rating!
Correlation ID: 2962 · Black Variable ID: 3083 · Red Variable ID: 14883


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}