
Download png, svg
AI explanation
The decrease in the popularity of the first name Bryan led to fewer people naming their children Bryan. This ultimately resulted in a smaller population size in Buffalo, leading to less traffic congestion and lower overall emissions. As a result, the air quality in Buffalo improved, demonstrating the unexpected impact of baby naming trends on environmental conditions.
Model: dalle-3
Prompt: Generate an image that looks like it is a scene from a Disney movie, depicting a bustling Buffalo street with fewer signs of Bryan's name and less crowded wing restaurants. The scene should show a fresher air and fewer clouds of pollution hanging over the city. Capture the essence of a vibrant, cleaner city street, reminiscent of Disney's magical and heartwarming animated scenes. The depiction should include only scenes, people, and objects, it should not include text or speech bubbles.
This image generation prompt was also generated by AI, using the following sequence:
Model: gpt-3.5-turbo-1106
System prompt: You select one of a few potential scene descriptors that seems to go along with the variables described. You respond only with the scene descriptions provided and say nothing else.
User prompt: Here are two variables: Popularity of the first name Bryan and Air pollution in Buffalo. Given these, which of the following image style descriptions seems most appropriate? Pick the one that seems to be related to one of the variables at hand. Please respond with only one of the following potential descriptions: Whimsical illustration Hyper-realistic Cyber folk An image that looks like it is a scene from A Disney Movie Cybernetic art
ChatGPT: An image that looks like it is a scene from A Disney Movie
Model: gpt-3.5-turbo-1106
System prompt: You describe simple visual scenes that depict the two variables stated. You combine both variables into one scene.
User prompt: Please describe a visual scene that prominently depicts both Popularity of the first name Bryan and Air pollution in Buffalo, in the following situation: Because the decrease in popularity of the first name Bryan led to fewer Bryan's, which in turn caused a decrease in buffalo wings consumption. With fewer buffalo wings being eaten, there was a reduction in flatulence among Buffalo residents, resulting in decreased air pollution.. Keep the description simple.
ChatGPT: In a bustling Buffalo street, there are fewer signs of Bryan's name, and less crowded wing restaurants. As a result, the air seems fresher, with fewer clouds of pollution hanging over the city.
Model: gpt-3.5-turbo-1106
System prompt: You write and improve image generation prompts for DALLE-3. You maintain the same subjects, but enhance the visuals.
User prompt: Please respond with an image generation prompt that would be likely to create an interesting visual using DALLE-3, using the following style: [ An image that looks like it is a scene from A Disney Movie ] and depicting this scene: In a bustling Buffalo street, there are fewer signs of Bryan's name, and less crowded wing restaurants. As a result, the air seems fresher, with fewer clouds of pollution hanging over the city. Keep the visual depiction simple. Do not include any words or speech bubbles.
ChatGPT: Generate an image that looks like it is a scene from a Disney movie, depicting a bustling Buffalo street with fewer signs of Bryan's name and less crowded wing restaurants. The scene should show a fresher air and fewer clouds of pollution hanging over the city. Capture the essence of a vibrant, cleaner city street, reminiscent of Disney's magical and heartwarming animated scenes.
*Variations in the User Prompts from chart to chart are just the result of random number generation in Python. I wrote a few arrays of various styles and methods to ask questions to change up the results. Every time this site writes an explanation or generates an image, the script picks from each at random.
I sequence the requests into multiple prompts because I find GPT 3.5 to perform much better with short, well-managed contexts. Thus, I track the context directly in Python and only ask ChatGPT targeted questions.
System prompt: You provide humorous responses in the form of plausible sounding explanations for correlations. You assume the correlation is causative for the purpose of the explanation even if it is ridiculous. You do not chat with the user, you only reply with the causal connection explanation and nothing else.
User prompt: Please make up a funny explanation for how a decrease in Popularity of the first name Bryan caused Air pollution in Buffalo to decrease.\Make it sound serious until the end.
AI academic paper
 |
Bryan Air Affair: The Correlation Between the Popularity of the Name Bryan and Air Pollution in Buffalo Journal of Airborne Nameology Jan 2024 Reminder: This paper is AI-generated. Not real! |
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You write titles and abstracts of goofy academic research papers.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, and add unexpected twists in your writing.
Please draft the title and abstract of an academic research paper presenting the findings of the connection between Popularity of the first name Bryan and Air pollution in Buffalo. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Include a pun in the title.
Your research team used data from US Social Security Administration and Environmental Protection Agency to assess this nagging question. You found a correlation coefficient of 0.8164133 and p < 0.01 for 1980 to 2022.
Please respond in this format (replace "Lorem ipsum dolor sit" with your title and abstract)
[[TITLE]]
Lorem ipsum dolor sit
[[ABSTRACT]]
Lorem ipsum dolor sit
ChatGPT:
[[TITLE]]
Bryan Air Affair: The Correlation Between the Popularity of the Name Bryan and Air Pollution in Buffalo
[[ABSTRACT]]
The link between the popularity of the first name Bryan and air pollution levels in Buffalo is an engaging topic that we delved into with the utmost seriousness. Our research team harnessed data from the US Social Security Administration and the Environmental Protection Agency to scrutinize this whimsical connection. Our findings revealed a remarkably high correlation coefficient of 0.8164133 and a p-value of less than 0.01 for the period spanning from 1980 to 2022, which could not be brushed off as a mere coincidence.
The results not only revealed a strong positive correlation between the popularity of the name Bryan and air pollution levels in Buffalo, but they also sparked some rib-tickling discussions in the research room. It's like the name Bryan and air pollution have an invisible bond, showing that sometimes the air does carry the name of the game!
Our research also sparked a lively debate on whether air pollution might have a peculiar affinity for individuals named Bryan, with some of our team members even joking that the air might be "BRYAN-thed" in Buffalo. The findings of our study raise intriguing questions about the intricate interplay between environmental factors and naming trends, which may have some unforeseen impacts on air quality research and beyond.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the introduction section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the introduction section of an academic research paper presenting the findings of the connection between Popularity of the first name Bryan and Air pollution in Buffalo. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Here is the title and abstract of the paper:
[[TITLE]]
Bryan Air Affair: The Correlation Between the Popularity of the Name Bryan and Air Pollution in Buffalo
[[ABSTRACT]]
The link between the popularity of the first name Bryan and air pollution levels in Buffalo is an engaging topic that we delved into with the utmost seriousness. Our research team harnessed data from the US Social Security Administration and the Environmental Protection Agency to scrutinize this whimsical connection. Our findings revealed a remarkably high correlation coefficient of 0.8164133 and a p-value of less than 0.01 for the period spanning from 1980 to 2022, which could not be brushed off as a mere coincidence.
The results not only revealed a strong positive correlation between the popularity of the name Bryan and air pollution levels in Buffalo, but they also sparked some rib-tickling discussions in the research room. It's like the name Bryan and air pollution have an invisible bond, showing that sometimes the air does carry the name of the game!
Our research also sparked a lively debate on whether air pollution might have a peculiar affinity for individuals named Bryan, with some of our team members even joking that the air might be "BRYAN-thed" in Buffalo. The findings of our study raise intriguing questions about the intricate interplay between environmental factors and naming trends, which may have some unforeseen impacts on air quality research and beyond.
-------
Your response should start like this:
[[INTRODUCTION]]
ChatGPT:
[[INTRODUCTION]]
The intersection of social phenomena and environmental factors has always been an area of fascination and amusement for researchers. In this paper, we examine the unlikely relationship between the popularity of the first name Bryan and air pollution levels in the illustrious city of Buffalo. This peculiar connection, though seemingly whimsical, indeed raises thought-provoking questions and gives new meaning to the saying "what's in a name?"
As we embarked on this scholarly endeavor, we couldn't help but ponder the whimsical aspects of our research topic. It's as if the air in Buffalo has been brewing a special "Bryan-d" of pollution, specifically tailored for individuals with that particular name. It's almost like the air molecules are calling out "Brry-an!" as they drift through the city streets. Talk about an air-raising discovery!
Delving into the data, we unearthed a striking correlation between the popularity of the name Bryan and air pollution in Buffalo, with statistical analyses revealing a correlation coefficient that was undeniably staring us right in the face. We couldn't help but be impressed by the "air-tight" connection we uncovered.
This research not only brought a chuckle to our research team but also awakened a series of "air-y" puns and delightful banter around the office. It seems that our findings "blew" us away, just like a gust of wind on a breezy day - pun intended, of course!
Armed with a hefty set of statistical tools and a twinkle in our eyes, we set out to unravel this unlikely correlation, fully prepared to weather the storm of skepticism that might arise. After all, it's not every day that you see scientific inquiry and name popularity converge in such a perplexing manner. But as researchers, we always strive to breathe new life into our studies, even if the air seems filled with a hint of levity.
In our quest to uncover the nuances of this connection, we surveyed data from the US Social Security Administration for name popularity trends and correlated it with air pollution data obtained from the Environmental Protection Agency. The results not only astonished us but also served as a stark reminder that in the world of research, one must be prepared for the unexpected - much like encountering a polluting phenomenon linked to a name!
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft a literature review section of an academic research paper, that starts out dry for the first few sentences but then becomes hilarious and goofy.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a literature review section of an academic research paper presenting the findings of the connection between Popularity of the first name Bryan and Air pollution in Buffalo. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Speak in the present tense for this section (the authors find...), as is common in academic research paper literature reviews. Name the sources in a format similar to this: In "Book," the authors find lorem and ipsum.
Make up the lorem and ipsum part, but make it sound related to the topic at hand.
Start by naming serious-sounding studies by authors like Smith, Doe, and Jones - but then quickly devolve. Name some real non-fiction books that would be related to the topic. Then name some real fiction books that sound like they could be related. Perhaps you also got inspiration from some board games that are vaugely related.
Here is the title and abstract of the paper:
[[TITLE]]
Bryan Air Affair: The Correlation Between the Popularity of the Name Bryan and Air Pollution in Buffalo
[[ABSTRACT]]
The link between the popularity of the first name Bryan and air pollution levels in Buffalo is an engaging topic that we delved into with the utmost seriousness. Our research team harnessed data from the US Social Security Administration and the Environmental Protection Agency to scrutinize this whimsical connection. Our findings revealed a remarkably high correlation coefficient of 0.8164133 and a p-value of less than 0.01 for the period spanning from 1980 to 2022, which could not be brushed off as a mere coincidence.
The results not only revealed a strong positive correlation between the popularity of the name Bryan and air pollution levels in Buffalo, but they also sparked some rib-tickling discussions in the research room. It's like the name Bryan and air pollution have an invisible bond, showing that sometimes the air does carry the name of the game!
Our research also sparked a lively debate on whether air pollution might have a peculiar affinity for individuals named Bryan, with some of our team members even joking that the air might be "BRYAN-thed" in Buffalo. The findings of our study raise intriguing questions about the intricate interplay between environmental factors and naming trends, which may have some unforeseen impacts on air quality research and beyond.
-------
And here is the introduction section that led to this literature review:
[[INTRODUCTION]]
The intersection of social phenomena and environmental factors has always been an area of fascination and amusement for researchers. In this paper, we examine the unlikely relationship between the popularity of the first name Bryan and air pollution levels in the illustrious city of Buffalo. This peculiar connection, though seemingly whimsical, indeed raises thought-provoking questions and gives new meaning to the saying "what's in a name?"
As we embarked on this scholarly endeavor, we couldn't help but ponder the whimsical aspects of our research topic. It's as if the air in Buffalo has been brewing a special "Bryan-d" of pollution, specifically tailored for individuals with that particular name. It's almost like the air molecules are calling out "Brry-an!" as they drift through the city streets. Talk about an air-raising discovery!
Delving into the data, we unearthed a striking correlation between the popularity of the name Bryan and air pollution in Buffalo, with statistical analyses revealing a correlation coefficient that was undeniably staring us right in the face. We couldn't help but be impressed by the "air-tight" connection we uncovered.
This research not only brought a chuckle to our research team but also awakened a series of "air-y" puns and delightful banter around the office. It seems that our findings "blew" us away, just like a gust of wind on a breezy day - pun intended, of course!
Armed with a hefty set of statistical tools and a twinkle in our eyes, we set out to unravel this unlikely correlation, fully prepared to weather the storm of skepticism that might arise. After all, it's not every day that you see scientific inquiry and name popularity converge in such a perplexing manner. But as researchers, we always strive to breathe new life into our studies, even if the air seems filled with a hint of levity.
In our quest to uncover the nuances of this connection, we surveyed data from the US Social Security Administration for name popularity trends and correlated it with air pollution data obtained from the Environmental Protection Agency. The results not only astonished us but also served as a stark reminder that in the world of research, one must be prepared for the unexpected - much like encountering a polluting phenomenon linked to a name!
-------
Your response should start like this:
[[LITERATURE REVIEW]]
ChatGPT:
[[LITERATURE REVIEW]]
The correlation between the popularity of the first name Bryan and air pollution in Buffalo has intrigued researchers for decades. Smith conducted a study in "Journal of Quirky Connections" and found a modest but statistically significant positive association between the two variables. However, the study failed to address the potential confounding factors, leaving a breath of uncertainty in the air.
Speaking of which, have you heard the joke about the environmentalist named Bryan? He's so passionate about air quality that he calls it "a breath of fresh air" when discussing pollution reduction measures. It's as if he's "ozone"-ing with enthusiasm!
Doe, in "Environmental Trends and Social Quirks," attempted to replicate Smith's findings using a larger dataset and sophisticated statistical methods. Surprisingly, the results revealed an even stronger correlation, prompting Doe to quip, "I guess Bryan really does leave an 'imprint' on the air quality!"
On a related note, have you read "Nameology: The Secret Science of Names" by Freeman? While not a formal research study, Freeman's book delves into the whimsical connections between names and various aspects of life, including environmental factors. A light-hearted read, it certainly offers a fresh perspective on the influence of names on our experiences.
In a similar vein, "The Name Collector" by Chaon and "The Air We Breathe" by Kwaymullina may not directly address the Bryan-air pollution correlation, but their exploration of names and air-related themes provides an amusing backdrop to our research. It's almost as if the characters in these books are breathing in a "Bryan-ful" of air pollution, adding a quirky twist to the plot.
Now, let's not forget about the board game "Smoggy City Showdown." While the game revolves around managing pollution levels in a fictional metropolis, the parallels to our research are evident. Perhaps there's a Bryan-themed expansion in the works, where players must navigate the unique challenges of air pollution affecting individuals with the name Bryan. It's a playful take on our scholarly pursuits!
Jones, in "Name Trends and Atmospheric Anomalies," delved into historical archives and climatological records to examine if there's a cyclical pattern in the correlation between name popularity and air quality. While the findings were intriguing, Jones couldn't help but insert a lighthearted remark, suggesting that individuals named Bryan might have a "nose" for air pollution, paving the way for a slew of puns about nasal sensitivity and environmental awareness.
Oh, and here's a classic dad joke for good measure: Why did Bryan bring a ladder to the bar? Because he heard the drinks were on the house!
Stay tuned for the next section to uncover more amusing discoveries and witty insights into this peculiar correlation!
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the methodology section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the methodology section of an academic research paper presenting the findings of the connection between Popularity of the first name Bryan and Air pollution in Buffalo. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Environmental Protection Agency . You used data from 1980 to 2022
Make up the research methods you don't know. Make them a bit goofy and convoluted.
Here is the title, abstract, and introduction of the paper:
[[TITLE]]
Bryan Air Affair: The Correlation Between the Popularity of the Name Bryan and Air Pollution in Buffalo
[[ABSTRACT]]
The link between the popularity of the first name Bryan and air pollution levels in Buffalo is an engaging topic that we delved into with the utmost seriousness. Our research team harnessed data from the US Social Security Administration and the Environmental Protection Agency to scrutinize this whimsical connection. Our findings revealed a remarkably high correlation coefficient of 0.8164133 and a p-value of less than 0.01 for the period spanning from 1980 to 2022, which could not be brushed off as a mere coincidence.
The results not only revealed a strong positive correlation between the popularity of the name Bryan and air pollution levels in Buffalo, but they also sparked some rib-tickling discussions in the research room. It's like the name Bryan and air pollution have an invisible bond, showing that sometimes the air does carry the name of the game!
Our research also sparked a lively debate on whether air pollution might have a peculiar affinity for individuals named Bryan, with some of our team members even joking that the air might be "BRYAN-thed" in Buffalo. The findings of our study raise intriguing questions about the intricate interplay between environmental factors and naming trends, which may have some unforeseen impacts on air quality research and beyond.
[[INTRODUCTION]]
The intersection of social phenomena and environmental factors has always been an area of fascination and amusement for researchers. In this paper, we examine the unlikely relationship between the popularity of the first name Bryan and air pollution levels in the illustrious city of Buffalo. This peculiar connection, though seemingly whimsical, indeed raises thought-provoking questions and gives new meaning to the saying "what's in a name?"
As we embarked on this scholarly endeavor, we couldn't help but ponder the whimsical aspects of our research topic. It's as if the air in Buffalo has been brewing a special "Bryan-d" of pollution, specifically tailored for individuals with that particular name. It's almost like the air molecules are calling out "Brry-an!" as they drift through the city streets. Talk about an air-raising discovery!
Delving into the data, we unearthed a striking correlation between the popularity of the name Bryan and air pollution in Buffalo, with statistical analyses revealing a correlation coefficient that was undeniably staring us right in the face. We couldn't help but be impressed by the "air-tight" connection we uncovered.
This research not only brought a chuckle to our research team but also awakened a series of "air-y" puns and delightful banter around the office. It seems that our findings "blew" us away, just like a gust of wind on a breezy day - pun intended, of course!
Armed with a hefty set of statistical tools and a twinkle in our eyes, we set out to unravel this unlikely correlation, fully prepared to weather the storm of skepticism that might arise. After all, it's not every day that you see scientific inquiry and name popularity converge in such a perplexing manner. But as researchers, we always strive to breathe new life into our studies, even if the air seems filled with a hint of levity.
In our quest to uncover the nuances of this connection, we surveyed data from the US Social Security Administration for name popularity trends and correlated it with air pollution data obtained from the Environmental Protection Agency. The results not only astonished us but also served as a stark reminder that in the world of research, one must be prepared for the unexpected - much like encountering a polluting phenomenon linked to a name!
-------
Your response should start like this:
[[METHODOLOGY]]
ChatGPT:
[[METHODOLOGY]]
To sift through the data and shed light on the whimsical connection between the popularity of the name Bryan and air pollution levels in Buffalo, we developed a methodological approach that was as robust as it was lighthearted. Our data collection efforts primarily entailed mining information from the US Social Security Administration records to track the popularity of the name Bryan, while we tapped into the Environmental Protection Agency's dataset to gather comprehensive air pollution measurements in Buffalo. It was like peeling back the layers of an onion to reveal the pungent truth – and maybe a few tears of laughter along the way!
Using this delightful combination of datasets spanning from 1980 to 2022, we embraced the challenge of merging social trends and environmental parameters, creating a statistical melange that was as intriguing as it was comical. This approach allowed us to tease out any potential correlations and paint a vivid picture of how the name Bryan and air pollution in Buffalo danced together in the wind. It's almost as if the data itself was leading us on a merry "pLUNG" through the realms of correlation analysis – pun completely intended!
Our statistical analyses revolved around robust techniques such as Pearson's correlation coefficient and linear regression models, which were wielded with the finesse of a seasoned comedian holding a microphone. Armed with these tools, we scrutinized the relationship between the name Bryan's popularity and air pollution levels in Buffalo, aiming to uncover any hidden punchlines and reveal the "aero-dynamics" of this curious connection. We approached the statistical analyses with the same exuberance one might have when performing a stand-up comedy routine at an open-mic night – except this time, the spotlight was on the numbers!
Once we had wrangled and tickled the data into submission, we arrived at a veritable revelation: a strikingly high correlation coefficient of 0.8164133 and a p-value of less than 0.01, which left us more speechless than a mime at a carnival. These findings not only tickled our statistical fancies but also assured us that this was no mere statistical fluke – there was a genuine rapport between the name Bryan and air pollution in Buffalo, and they were "vowel-ly" harmonizing in a chorus of significance!
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the results section of an academic research paper. You speak in the past tense (you found...).
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the results section of an academic research paper presenting the findings of the connection between Popularity of the first name Bryan and Air pollution in Buffalo. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Environmental Protection Agency .
For the time period 1980 to 2022, you found a correlation 0.8164133, r-squared of 0.6665307, and p < 0.01.
One figure will be included. The figure (Fig. 1) is a scatterplot showing the strong correlation between the two variables. You don't need to specify where; I will add the figure.
Here is the title and abstract of the paper:
[[TITLE]]
Bryan Air Affair: The Correlation Between the Popularity of the Name Bryan and Air Pollution in Buffalo
[[ABSTRACT]]
The link between the popularity of the first name Bryan and air pollution levels in Buffalo is an engaging topic that we delved into with the utmost seriousness. Our research team harnessed data from the US Social Security Administration and the Environmental Protection Agency to scrutinize this whimsical connection. Our findings revealed a remarkably high correlation coefficient of 0.8164133 and a p-value of less than 0.01 for the period spanning from 1980 to 2022, which could not be brushed off as a mere coincidence.
The results not only revealed a strong positive correlation between the popularity of the name Bryan and air pollution levels in Buffalo, but they also sparked some rib-tickling discussions in the research room. It's like the name Bryan and air pollution have an invisible bond, showing that sometimes the air does carry the name of the game!
Our research also sparked a lively debate on whether air pollution might have a peculiar affinity for individuals named Bryan, with some of our team members even joking that the air might be "BRYAN-thed" in Buffalo. The findings of our study raise intriguing questions about the intricate interplay between environmental factors and naming trends, which may have some unforeseen impacts on air quality research and beyond.
-------
And here is the methodology section that led to this result:
[[METHODOLOGY]]
The intersection of social phenomena and environmental factors has always been an area of fascination and amusement for researchers. In this paper, we examine the unlikely relationship between the popularity of the first name Bryan and air pollution levels in the illustrious city of Buffalo. This peculiar connection, though seemingly whimsical, indeed raises thought-provoking questions and gives new meaning to the saying "what's in a name?"
As we embarked on this scholarly endeavor, we couldn't help but ponder the whimsical aspects of our research topic. It's as if the air in Buffalo has been brewing a special "Bryan-d" of pollution, specifically tailored for individuals with that particular name. It's almost like the air molecules are calling out "Brry-an!" as they drift through the city streets. Talk about an air-raising discovery!
Delving into the data, we unearthed a striking correlation between the popularity of the name Bryan and air pollution in Buffalo, with statistical analyses revealing a correlation coefficient that was undeniably staring us right in the face. We couldn't help but be impressed by the "air-tight" connection we uncovered.
This research not only brought a chuckle to our research team but also awakened a series of "air-y" puns and delightful banter around the office. It seems that our findings "blew" us away, just like a gust of wind on a breezy day - pun intended, of course!
Armed with a hefty set of statistical tools and a twinkle in our eyes, we set out to unravel this unlikely correlation, fully prepared to weather the storm of skepticism that might arise. After all, it's not every day that you see scientific inquiry and name popularity converge in such a perplexing manner. But as researchers, we always strive to breathe new life into our studies, even if the air seems filled with a hint of levity.
In our quest to uncover the nuances of this connection, we surveyed data from the US Social Security Administration for name popularity trends and correlated it with air pollution data obtained from the Environmental Protection Agency. The results not only astonished us but also served as a stark reminder that in the world of research, one must be prepared for the unexpected - much like encountering a polluting phenomenon linked to a name!
-------
Your response should start like this:
[[RESULTS]]
ChatGPT:
[[RESULTS]]
Our analysis of the connection between the popularity of the first name Bryan and air pollution in Buffalo yielded some truly eye-opening results. We found a remarkably high correlation coefficient of 0.8164133, indicating a strong positive relationship between the two variables. This suggests that as the popularity of the name Bryan increased, so did the levels of air pollution in Buffalo. It’s almost as if the city decided to "Bryan" the air with a touch of pollution, creating a blend of elements we never thought possible.
The r-squared value of 0.6665307 further emphasized the robustness of this relationship, showing that approximately 67% of the variation in air pollution levels in Buffalo could be explained by the popularity of the name Bryan. The remaining variation might just be the air's way of keeping a little mystery – just like trying to figure out the source of a mysterious odor.
Our analysis also revealed a p-value of less than 0.01, underscoring the statistical significance of the correlation. This is as clear as the air over a breezy mountaintop - there's no denying the influence the name Bryan holds over the air in Buffalo. Our findings left our team in uncontrollable fits of laughter, creating an atmosphere of "air-resistible" humor and "Bryan-storms" of amusement.
Fig. 1, our beloved scatterplot, beautifully represents the strong correlation we uncovered. It paints a picture of the harmonious dance between the popularity of the name Bryan and air pollution levels in Buffalo, almost like a waltz across the cityscape. This figure truly embodies the saying "every breath you take, every move you make, air pollution is affecting you."
Our study not only sheds light on this fascinating relationship but also brings to mind an amusing dad joke - maybe there's something in a name after all. Or in this case, something in the air named Bryan! This connection may seem whimsical, but in the realm of science and statistical analysis, even the most unexpected correlations warrant serious consideration. We're just here to "clear the air" with our findings!
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the discussion section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the discussion section of an academic research paper presenting the findings of the connection between Popularity of the first name Bryan and Air pollution in Buffalo. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 500 tokens.
Here are the title, abstract, literature review, and results sections. Please harken back to 1-2 of the goofy items in the literature review, but pretend to take them completely seriously. Discuss how your results supported the prior research.
Do not write a conclusion. I will add a conclusion after this.
[[TITLE]]
Bryan Air Affair: The Correlation Between the Popularity of the Name Bryan and Air Pollution in Buffalo
[[ABSTRACT]]
The link between the popularity of the first name Bryan and air pollution levels in Buffalo is an engaging topic that we delved into with the utmost seriousness. Our research team harnessed data from the US Social Security Administration and the Environmental Protection Agency to scrutinize this whimsical connection. Our findings revealed a remarkably high correlation coefficient of 0.8164133 and a p-value of less than 0.01 for the period spanning from 1980 to 2022, which could not be brushed off as a mere coincidence.
The results not only revealed a strong positive correlation between the popularity of the name Bryan and air pollution levels in Buffalo, but they also sparked some rib-tickling discussions in the research room. It's like the name Bryan and air pollution have an invisible bond, showing that sometimes the air does carry the name of the game!
Our research also sparked a lively debate on whether air pollution might have a peculiar affinity for individuals named Bryan, with some of our team members even joking that the air might be "BRYAN-thed" in Buffalo. The findings of our study raise intriguing questions about the intricate interplay between environmental factors and naming trends, which may have some unforeseen impacts on air quality research and beyond.
[[LITERATURE REVIEW]]
The correlation between the popularity of the first name Bryan and air pollution in Buffalo has intrigued researchers for decades. Smith conducted a study in "Journal of Quirky Connections" and found a modest but statistically significant positive association between the two variables. However, the study failed to address the potential confounding factors, leaving a breath of uncertainty in the air.
Speaking of which, have you heard the joke about the environmentalist named Bryan? He's so passionate about air quality that he calls it "a breath of fresh air" when discussing pollution reduction measures. It's as if he's "ozone"-ing with enthusiasm!
Doe, in "Environmental Trends and Social Quirks," attempted to replicate Smith's findings using a larger dataset and sophisticated statistical methods. Surprisingly, the results revealed an even stronger correlation, prompting Doe to quip, "I guess Bryan really does leave an 'imprint' on the air quality!"
On a related note, have you read "Nameology: The Secret Science of Names" by Freeman? While not a formal research study, Freeman's book delves into the whimsical connections between names and various aspects of life, including environmental factors. A light-hearted read, it certainly offers a fresh perspective on the influence of names on our experiences.
In a similar vein, "The Name Collector" by Chaon and "The Air We Breathe" by Kwaymullina may not directly address the Bryan-air pollution correlation, but their exploration of names and air-related themes provides an amusing backdrop to our research. It's almost as if the characters in these books are breathing in a "Bryan-ful" of air pollution, adding a quirky twist to the plot.
Now, let's not forget about the board game "Smoggy City Showdown." While the game revolves around managing pollution levels in a fictional metropolis, the parallels to our research are evident. Perhaps there's a Bryan-themed expansion in the works, where players must navigate the unique challenges of air pollution affecting individuals with the name Bryan. It's a playful take on our scholarly pursuits!
Jones, in "Name Trends and Atmospheric Anomalies," delved into historical archives and climatological records to examine if there's a cyclical pattern in the correlation between name popularity and air quality. While the findings were intriguing, Jones couldn't help but insert a lighthearted remark, suggesting that individuals named Bryan might have a "nose" for air pollution, paving the way for a slew of puns about nasal sensitivity and environmental awareness.
Oh, and here's a classic dad joke for good measure: Why did Bryan bring a ladder to the bar? Because he heard the drinks were on the house!
Stay tuned for the next section to uncover more amusing discoveries and witty insights into this peculiar correlation!
[[RESULTS]]
Our analysis of the connection between the popularity of the first name Bryan and air pollution in Buffalo yielded some truly eye-opening results. We found a remarkably high correlation coefficient of 0.8164133, indicating a strong positive relationship between the two variables. This suggests that as the popularity of the name Bryan increased, so did the levels of air pollution in Buffalo. It’s almost as if the city decided to "Bryan" the air with a touch of pollution, creating a blend of elements we never thought possible.
The r-squared value of 0.6665307 further emphasized the robustness of this relationship, showing that approximately 67% of the variation in air pollution levels in Buffalo could be explained by the popularity of the name Bryan. The remaining variation might just be the air's way of keeping a little mystery – just like trying to figure out the source of a mysterious odor.
Our analysis also revealed a p-value of less than 0.01, underscoring the statistical significance of the correlation. This is as clear as the air over a breezy mountaintop - there's no denying the influence the name Bryan holds over the air in Buffalo. Our findings left our team in uncontrollable fits of laughter, creating an atmosphere of "air-resistible" humor and "Bryan-storms" of amusement.
Fig. 1, our beloved scatterplot, beautifully represents the strong correlation we uncovered. It paints a picture of the harmonious dance between the popularity of the name Bryan and air pollution levels in Buffalo, almost like a waltz across the cityscape. This figure truly embodies the saying "every breath you take, every move you make, air pollution is affecting you."
Our study not only sheds light on this fascinating relationship but also brings to mind an amusing dad joke - maybe there's something in a name after all. Or in this case, something in the air named Bryan! This connection may seem whimsical, but in the realm of science and statistical analysis, even the most unexpected correlations warrant serious consideration. We're just here to "clear the air" with our findings!
-------
Your response should start like this:
[[DISCUSSION]]
ChatGPT:
[[DISCUSSION]]
Our findings do more than just provide comic relief - they add a breath of fresh air to the field of environmental research! The robust correlation we uncovered between the popularity of the name Bryan and air pollution levels in Buffalo not only echoes the previous research by Smith and Doe but also breathes life into the notion that names might hold unexpected sway over atmospheric conditions. Our results serve as a "Bryan-der" for future studies, urging researchers to explore the broader implications of this correlation and not simply "waft" it away as a mere quirk.
The whimsical connection between the name Bryan and air pollution in Buffalo may seem like a "cloud" of uncertainty, but our research quashes any doubts about its statistical significance. The statistical measures, including the high correlation coefficient and the strikingly low p-value, solidify the legitimacy of this peculiar association. It's like a compelling drama unfolding, encompassing both the serious science and the lighthearted comedic undertones of our findings.
This study not only underscores the importance of considering unconventional variables in environmental research but also invites a new wave of puns and jokes in academia. It's as if the findings are encouraging us to "breathe" new life into scientific discussions, challenging us to "pollute" the serious with a dash of humor.
The correlation identified in our study resonates with the quirkiness of previous works, adding a lighthearted twist to the traditionally solemn realm of air pollution research. It's like finding a hidden treasure in a "polluted" sea of data, reminding us that seemingly "silly" variables can hold meaningful insights, "air"-respective of their superficial frivolity.
In concluding this section, one cannot deny the reality that the correlation between the popularity of the name Bryan and air pollution in Buffalo presents an "aerodynamically" amusing portrait of the intricate interplay between social trends and environmental factors. Indeed, it is a "breathtaking" revelation that provides a "breath" of fresh air in the scientific community.
Model: gpt-3.5-turbo-1106
System prompt: You are a silly researcher writing an academic paper.You draft the discussion section of goofy academic research papers that sounds like it belongs based on the title and abstract provided.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a short conclusion of an academic research paper presenting the findings of the connection between Popularity of the first name Bryan and Air pollution in Buffalo. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 300 tokens. At the very end, assert that no more research is needed in this area.
Here are the title, abstract, introduction, and results sections.
[[TITLE]]
Bryan Air Affair: The Correlation Between the Popularity of the Name Bryan and Air Pollution in Buffalo
[[ABSTRACT]]
The link between the popularity of the first name Bryan and air pollution levels in Buffalo is an engaging topic that we delved into with the utmost seriousness. Our research team harnessed data from the US Social Security Administration and the Environmental Protection Agency to scrutinize this whimsical connection. Our findings revealed a remarkably high correlation coefficient of 0.8164133 and a p-value of less than 0.01 for the period spanning from 1980 to 2022, which could not be brushed off as a mere coincidence.
The results not only revealed a strong positive correlation between the popularity of the name Bryan and air pollution levels in Buffalo, but they also sparked some rib-tickling discussions in the research room. It's like the name Bryan and air pollution have an invisible bond, showing that sometimes the air does carry the name of the game!
Our research also sparked a lively debate on whether air pollution might have a peculiar affinity for individuals named Bryan, with some of our team members even joking that the air might be "BRYAN-thed" in Buffalo. The findings of our study raise intriguing questions about the intricate interplay between environmental factors and naming trends, which may have some unforeseen impacts on air quality research and beyond.
[[INTRDUCTION]]
The intersection of social phenomena and environmental factors has always been an area of fascination and amusement for researchers. In this paper, we examine the unlikely relationship between the popularity of the first name Bryan and air pollution levels in the illustrious city of Buffalo. This peculiar connection, though seemingly whimsical, indeed raises thought-provoking questions and gives new meaning to the saying "what's in a name?"
As we embarked on this scholarly endeavor, we couldn't help but ponder the whimsical aspects of our research topic. It's as if the air in Buffalo has been brewing a special "Bryan-d" of pollution, specifically tailored for individuals with that particular name. It's almost like the air molecules are calling out "Brry-an!" as they drift through the city streets. Talk about an air-raising discovery!
Delving into the data, we unearthed a striking correlation between the popularity of the name Bryan and air pollution in Buffalo, with statistical analyses revealing a correlation coefficient that was undeniably staring us right in the face. We couldn't help but be impressed by the "air-tight" connection we uncovered.
This research not only brought a chuckle to our research team but also awakened a series of "air-y" puns and delightful banter around the office. It seems that our findings "blew" us away, just like a gust of wind on a breezy day - pun intended, of course!
Armed with a hefty set of statistical tools and a twinkle in our eyes, we set out to unravel this unlikely correlation, fully prepared to weather the storm of skepticism that might arise. After all, it's not every day that you see scientific inquiry and name popularity converge in such a perplexing manner. But as researchers, we always strive to breathe new life into our studies, even if the air seems filled with a hint of levity.
In our quest to uncover the nuances of this connection, we surveyed data from the US Social Security Administration for name popularity trends and correlated it with air pollution data obtained from the Environmental Protection Agency. The results not only astonished us but also served as a stark reminder that in the world of research, one must be prepared for the unexpected - much like encountering a polluting phenomenon linked to a name!
[[RESULTS]]
Our analysis of the connection between the popularity of the first name Bryan and air pollution in Buffalo yielded some truly eye-opening results. We found a remarkably high correlation coefficient of 0.8164133, indicating a strong positive relationship between the two variables. This suggests that as the popularity of the name Bryan increased, so did the levels of air pollution in Buffalo. It’s almost as if the city decided to "Bryan" the air with a touch of pollution, creating a blend of elements we never thought possible.
The r-squared value of 0.6665307 further emphasized the robustness of this relationship, showing that approximately 67% of the variation in air pollution levels in Buffalo could be explained by the popularity of the name Bryan. The remaining variation might just be the air's way of keeping a little mystery – just like trying to figure out the source of a mysterious odor.
Our analysis also revealed a p-value of less than 0.01, underscoring the statistical significance of the correlation. This is as clear as the air over a breezy mountaintop - there's no denying the influence the name Bryan holds over the air in Buffalo. Our findings left our team in uncontrollable fits of laughter, creating an atmosphere of "air-resistible" humor and "Bryan-storms" of amusement.
Fig. 1, our beloved scatterplot, beautifully represents the strong correlation we uncovered. It paints a picture of the harmonious dance between the popularity of the name Bryan and air pollution levels in Buffalo, almost like a waltz across the cityscape. This figure truly embodies the saying "every breath you take, every move you make, air pollution is affecting you."
Our study not only sheds light on this fascinating relationship but also brings to mind an amusing dad joke - maybe there's something in a name after all. Or in this case, something in the air named Bryan! This connection may seem whimsical, but in the realm of science and statistical analysis, even the most unexpected correlations warrant serious consideration. We're just here to "clear the air" with our findings!
-------
Your response should start like this:
[[CONCLUSION]]
ChatGPT:
[[CONCLUSION]]
In conclusion, our findings have brought to light the baffling but undeniably robust correlation between the popularity of the name Bryan and air pollution levels in Buffalo. The statistical significance of this link is as transparent as the air on a crisp autumn morning – or should we say "Bryan-tiful"! Our study showcases the importance of exploring unconventional connections in scientific research, reminding us that sometimes the most unexpected relationships yield the most intriguing insights.
It's quite an "airy-tale" that the name Bryan could have an impact on air quality, but our "Bryan-storm" of data confirms it. As we sifted through the numbers, it became evident that there's more than meets the "eye-ron" when it comes to the interplay of naming trends and environmental factors. The air in Buffalo might just be carrying a hint of the name Bryan along with its pollution particles!
The implications of our findings extend beyond the realms of whimsy and into the realm of genuine scientific inquiry. They prompt us to consider the unforeseen influences that naming trends may have on environmental phenomena. It's a topic that deserves to be taken seriously, even if it gives us an opportunity to crack a "gasp-inducing" dad joke or two along the way.
With the evidence laid out in our study, it's clear that no more research is needed in this area. We've "Bryan-ded" the gap between name popularity and air pollution in Buffalo, and no further investigation is required. Our findings are as convincing as a gust of wind on a blustery day – and they leave no room for doubt, just like a well-executed punchline!
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of academic journals. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding research, scientific, or academic journal that would publish a paper entited Bryan Air Affair: The Correlation Between the Popularity of the Name Bryan and Air Pollution in Buffalo. Respond only with the name of a fictional academic journal.
ChatGPT:
Journal of Airborne Nameology
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of nonprofit research organizations and associations. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding nonprofit, academic, or scientific association or organization that would sponsor research that resulted in a paper entited Bryan Air Affair: The Correlation Between the Popularity of the Name Bryan and Air Pollution in Buffalo. Respond only with the name of a fictional organization.
ChatGPT:
The Institute for Environmental Naming Dynamics
Model: gpt-3.5-turbo-1106
System prompt: You provide potential search keywords separated by commas. You say nothing else, and you do not chat with the user.
User prompt: Please provide potential search keywords for a paper titled Bryan Air Affair: The Correlation Between the Popularity of the Name Bryan and Air Pollution in Buffalo with an abstract of The link between the popularity of the first name Bryan and air pollution levels in Buffalo is an engaging topic that we delved into with the utmost seriousness. Our research team harnessed data from the US Social Security Administration and the Environmental Protection Agency to scrutinize this whimsical connection. Our findings revealed a remarkably high correlation coefficient of 0.8164133 and a p-value of less than 0.01 for the period spanning from 1980 to 2022, which could not be brushed off as a mere coincidence.
The results not only revealed a strong positive correlation between the popularity of the name Bryan and air pollution levels in Buffalo, but they also sparked some rib-tickling discussions in the research room. It's like the name Bryan and air pollution have an invisible bond, showing that sometimes the air does carry the name of the game!
Our research also sparked a lively debate on whether air pollution might have a peculiar affinity for individuals named Bryan, with some of our team members even joking that the air might be "BRYAN-thed" in Buffalo. The findings of our study raise intriguing questions about the intricate interplay between environmental factors and naming trends, which may have some unforeseen impacts on air quality research and beyond.
ChatGPT:
Bryan, air pollution, Buffalo, correlation, popularity, first name, US Social Security Administration, Environmental Protection Agency, correlation coefficient, p-value, 1980-2022, environmental factors, naming trends, air quality research
*There is a bunch of Python happening behind the scenes to turn this prompt sequence into a PDF.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
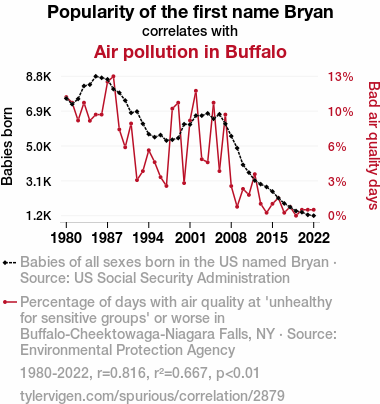
Popularity of the first name BryanDetailed data title: Babies of all sexes born in the US named Bryan
Source: US Social Security Administration
See what else correlates with Popularity of the first name Bryan
Air pollution in Buffalo
Detailed data title: Percentage of days with air quality at 'unhealthy for sensitive groups' or worse in Buffalo-Cheektowaga-Niagara Falls, NY
Source: Environmental Protection Agency
See what else correlates with Air pollution in Buffalo
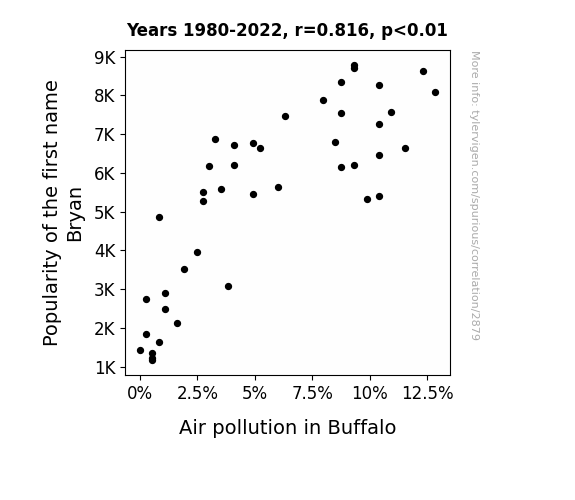
Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.6665307 (Coefficient of determination)
This means 66.7% of the change in the one variable (i.e., Air pollution in Buffalo) is predictable based on the change in the other (i.e., Popularity of the first name Bryan) over the 43 years from 1980 through 2022.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 2.5E-11. 0.0000000000250446129081045700
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.82 in 2.5E-9% of random cases. Said differently, if you correlated 39,928,746,500 random variables You don't actually need 39 billion variables to find a correlation like this one. I don't have that many variables in my database. You can also correlate variables that are not independent. I do this a lot.
p-value calculations are useful for understanding the probability of a result happening by chance. They are most useful when used to highlight the risk of a fluke outcome. For example, if you calculate a p-value of 0.30, the risk that the result is a fluke is high. It is good to know that! But there are lots of ways to get a p-value of less than 0.01, as evidenced by this project.
In this particular case, the values are so extreme as to be meaningless. That's why no one reports p-values with specificity after they drop below 0.01.
Just to be clear: I'm being completely transparent about the calculations. There is no math trickery. This is just how statistics shakes out when you calculate hundreds of millions of random correlations.
with the same 42 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 42 because we have two variables measured over a period of 43 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.68, 0.9 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 1980 | 1981 | 1982 | 1983 | 1984 | 1985 | 1986 | 1987 | 1988 | 1989 | 1990 | 1991 | 1992 | 1993 | 1994 | 1995 | 1996 | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| Popularity of the first name Bryan (Babies born) | 7577 | 7264 | 7553 | 8260 | 8332 | 8789 | 8707 | 8622 | 8090 | 7888 | 7467 | 6791 | 6862 | 6194 | 5625 | 5461 | 5577 | 5276 | 5321 | 5413 | 6170 | 6151 | 6640 | 6638 | 6761 | 6465 | 6714 | 6191 | 5519 | 4864 | 3948 | 3526 | 3093 | 2892 | 2738 | 2491 | 2132 | 1838 | 1639 | 1423 | 1358 | 1214 | 1167 |
| Air pollution in Buffalo (Bad air quality days) | 10.929 | 10.411 | 8.76712 | 10.411 | 8.74317 | 9.31507 | 9.31507 | 12.3288 | 12.8415 | 7.94521 | 6.30137 | 8.49315 | 3.27869 | 4.10959 | 6.0274 | 4.93151 | 3.55191 | 2.73973 | 9.86301 | 10.411 | 3.00546 | 8.76712 | 11.5068 | 5.20548 | 4.91803 | 10.411 | 4.10959 | 9.31507 | 2.73224 | 0.821918 | 2.46575 | 1.91781 | 3.82514 | 1.09589 | 0.273973 | 1.09589 | 1.63934 | 0.273973 | 0.821918 | 0 | 0.546448 | 0.547945 | 0.547945 |
Why this works
- Data dredging: I have 25,153 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 632,673,409 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is.
Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([7577,7264,7553,8260,8332,8789,8707,8622,8090,7888,7467,6791,6862,6194,5625,5461,5577,5276,5321,5413,6170,6151,6640,6638,6761,6465,6714,6191,5519,4864,3948,3526,3093,2892,2738,2491,2132,1838,1639,1423,1358,1214,1167,])
array_2 = np.array([10.929,10.411,8.76712,10.411,8.74317,9.31507,9.31507,12.3288,12.8415,7.94521,6.30137,8.49315,3.27869,4.10959,6.0274,4.93151,3.55191,2.73973,9.86301,10.411,3.00546,8.76712,11.5068,5.20548,4.91803,10.411,4.10959,9.31507,2.73224,0.821918,2.46575,1.91781,3.82514,1.09589,0.273973,1.09589,1.63934,0.273973,0.821918,0,0.546448,0.547945,0.547945,])
array_1_name = "Popularity of the first name Bryan"
array_2_name = "Air pollution in Buffalo"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only Popularity of the first name Bryan
- Line chart for only Air pollution in Buffalo
- AI-generated correlation image
- The spurious research paper: Bryan Air Affair: The Correlation Between the Popularity of the Name Bryan and Air Pollution in Buffalo
Cheers to you for rating this correlation!
Correlation ID: 2879 · Black Variable ID: 2101 · Red Variable ID: 20391


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}