
Download png, svg
AI explanation
Less smog means clearer communication, prompting fewer locals to say "no hablo español" and inspiring them to mejor their language skills. With cleaner air, there's menos confusion, leading to menos need for language immersion. Who needs Rosetta Stone when you can just respire more aire puro for a natural grasp of the language? Seems like in Jacksonville, as the air quality improves, the language barriers disminuyen! ¡Qué bueno!
Model: dalle-3
Prompt: Generate an image of downtown Jacksonville, Florida in a comic-book-style illustration with muted colors and a dotted halftone pattern from the 1960s. Show a serene city skyline emerging from the haze of pollution reduction, where cars glide quietly along the streets and people stroll with less stress. Capture the peaceful atmosphere and the interactions between residents in a calming, English-speaking setting, with occasional friendly "hola" exchanges. The depiction should include only scenes, people, and objects, it should not include text or speech bubbles.
This image generation prompt was also generated by AI, using the following sequence:
Model: gpt-3.5-turbo-1106
System prompt: You select one of a few potential scene descriptors that seems to go along with the variables described. You respond only with the scene descriptions provided and say nothing else.
User prompt: Here are two variables: Air pollution in Jacksonville, Florida and Google searches for 'learn spanish'. Given these, which of the following image style descriptions seems most appropriate? Pick the one that seems to be related to one of the variables at hand. Please respond with only one of the following potential descriptions: Cutsy graphics Cubism Futuristic A comic-book-style illustration with muted colors and a dotted halftone pattern from the 1960s Charcoal
ChatGPT: A comic-book-style illustration with muted colors and a dotted halftone pattern from the 1960s
Model: gpt-3.5-turbo-1106
System prompt: You describe simple visual scenes that depict the two variables stated. You combine both variables into one scene.
User prompt: Please describe a visual scene that prominently depicts both Air pollution in Jacksonville, Florida and Google searches for 'learn spanish', in the following situation: The reduction in air pollution led to fewer cars honking, which in turn reduced the overall stress levels in the city. With less stress, people didn't feel the need to learn a new language to escape to a calmer, Spanish-speaking country. Instead, they could now peacefully coexist with the English language and the occasional 'hola' sufficed for their linguistic needs.. Keep the description simple.
ChatGPT: In Jacksonville, Florida, the hazy skyline cleared as the reduction in air pollution took effect. Cars glided along the streets with less noise, and the honking diminished. The atmosphere of the city became more serene, and the stress levels noticeably decreased. Amid the peaceful environment, people strolled through downtown, exchanging friendly 'hellos' with each other. Meanwhile, Google searches for "learn Spanish" dipped as the residents found solace in the calm, English-speaking setting, content with the occasional "hola" echoing through the streets.
Model: gpt-3.5-turbo-1106
System prompt: You write and improve image generation prompts for DALLE-3. You maintain the same subjects, but enhance the visuals.
User prompt: Please respond with an image generation prompt that would be likely to create an interesting visual using DALLE-3, using the following style: [ A comic-book-style illustration with muted colors and a dotted halftone pattern from the 1960s ] and depicting this scene: In Jacksonville, Florida, the hazy skyline cleared as the reduction in air pollution took effect. Cars glided along the streets with less noise, and the honking diminished. The atmosphere of the city became more serene, and the stress levels noticeably decreased. Amid the peaceful environment, people strolled through downtown, exchanging friendly 'hellos' with each other. Meanwhile, Google searches for "learn Spanish" dipped as the residents found solace in the calm, English-speaking setting, content with the occasional "hola" echoing through the streets. Keep the visual depiction simple. Do not include any words or speech bubbles.
ChatGPT: Generate an image of downtown Jacksonville, Florida in a comic-book-style illustration with muted colors and a dotted halftone pattern from the 1960s. Show a serene city skyline emerging from the haze of pollution reduction, where cars glide quietly along the streets and people stroll with less stress. Capture the peaceful atmosphere and the interactions between residents in a calming, English-speaking setting, with occasional friendly "hola" exchanges.
*Variations in the User Prompts from chart to chart are just the result of random number generation in Python. I wrote a few arrays of various styles and methods to ask questions to change up the results. Every time this site writes an explanation or generates an image, the script picks from each at random.
I sequence the requests into multiple prompts because I find GPT 3.5 to perform much better with short, well-managed contexts. Thus, I track the context directly in Python and only ask ChatGPT targeted questions.
System prompt: You provide humorous responses in the form of plausible sounding explanations for correlations. You assume the correlation is causative for the purpose of the explanation even if it is ridiculous. You do not chat with the user, you only reply with the causal connection explanation and nothing else.
User prompt: Please make up a funny explanation for how a decrease in Air pollution in Jacksonville, Florida caused learn spanish (Google searches for 'learn spanish') to decrease.
AI academic paper
 |
Breathing in Español: Unraveling the Link Between Air Pollution in Jacksonville, Florida and Google Searches for 'Learn Spanish' Journal of Multilingual Environmental Studies Jan 2024 Reminder: This paper is AI-generated. Not real! |
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You write titles and abstracts of goofy academic research papers.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, and add unexpected twists in your writing.
Please draft the title and abstract of an academic research paper presenting the findings of the connection between Air pollution in Jacksonville, Florida and Google searches for 'learn spanish'. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Make the title punny if you can come up with clever pun. If not, just make it sound clever.
Your research team used data from Environmental Protection Agency and Google Trends to assess this nagging question. You found a correlation coefficient of 0.9030695 and p < 0.01 for 2004 to 2020.
Please respond in this format (replace "Lorem ipsum dolor sit" with your title and abstract)
[[TITLE]]
Lorem ipsum dolor sit
[[ABSTRACT]]
Lorem ipsum dolor sit
ChatGPT:
[[TITLE]]
"Breathing in Español: Unraveling the Link Between Air Pollution in Jacksonville, Florida and Google Searches for 'Learn Spanish'"
[[ABSTRACT]]
In this study, we sought to investigate the intriguing connection between air pollution levels in Jacksonville, Florida and online interest in learning the Spanish language. Utilizing data from the Environmental Protection Agency and Google Trends, we conducted an extensive analysis covering the period from 2004 to 2020. Our findings revealed a remarkably robust correlation coefficient of 0.9030695, accompanied by a p-value of less than 0.01. While the underpinning mechanisms of this relationship remain enigmatic, our results suggest a compelling interplay between environmental factors and linguistic curiosity. This study not only sheds light on the intersection of air quality and language acquisition but also serves as a testament to the unanticipated whims of data exploration. As we endeavor to decipher this peculiar correlation, we invite fellow researchers to join us in this quest to untangle the intricate web of air pollution, language learning, and the human propensity for seeking nuevas oportunidades.
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft the introduction section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the introduction section of an academic research paper presenting the findings of the connection between Air pollution in Jacksonville, Florida and Google searches for 'learn spanish'. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Here is the title and abstract of the paper:
[[TITLE]]
"Breathing in Español: Unraveling the Link Between Air Pollution in Jacksonville, Florida and Google Searches for 'Learn Spanish'"
[[ABSTRACT]]
In this study, we sought to investigate the intriguing connection between air pollution levels in Jacksonville, Florida and online interest in learning the Spanish language. Utilizing data from the Environmental Protection Agency and Google Trends, we conducted an extensive analysis covering the period from 2004 to 2020. Our findings revealed a remarkably robust correlation coefficient of 0.9030695, accompanied by a p-value of less than 0.01. While the underpinning mechanisms of this relationship remain enigmatic, our results suggest a compelling interplay between environmental factors and linguistic curiosity. This study not only sheds light on the intersection of air quality and language acquisition but also serves as a testament to the unanticipated whims of data exploration. As we endeavor to decipher this peculiar correlation, we invite fellow researchers to join us in this quest to untangle the intricate web of air pollution, language learning, and the human propensity for seeking nuevas oportunidades.
-------
Your response should start like this:
[[INTRODUCTION]]
ChatGPT:
[[INTRODUCTION]]
The world of research is often characterized by the pursuit of knowledge, the integration of data, and the unending quest to uncover the unexpected. In this spirit of exploration, we set out to unravel a peculiar conundrum: the curious link between air pollution in Jacksonville, Florida and Google searches for 'learn Spanish.' As we embarked on this scientific escapade, we couldn't help but marvel at the whimsical nature of the variables at play. After all, who would have thought that particulate matter and language acquisition could engage in such a harmonious dance of statistical significance?
Air pollution, a perennial woe of urban landscapes, embodies the amalgamation of myriad chemical compounds and atmospheric disturbances. Meanwhile, the allure of learning Spanish, a language rich in history and vibrancy, serves as a conduit for cultural immersion and cognitive expansion. Yet little did we expect these seemingly disparate entities to converge in the realm of statistical inquiry.
With bated breath (hopefully not filled with pollutants), we delved into the labyrinth of environmental data and online search patterns, armed with a plethora of statistical tools and a pinch of scientific curiosity. Armed with our trusty arsenal of regression analyses, correlation coefficients, and p-values, we embarked on this journey with an equal measure of apprehension and amusement. After all, who could resist the strange attraction of quantifying the relationship between air quality indices and the yearning to add 'hablar español' to one's repertoire?
In the grand scheme of research endeavors, the pursuit of unraveling enigmatic correlations takes on a life of its own. As we prepare to unveil the intricate dance between air pollution and linguistic intrigue, we invite our esteemed colleagues to join us in this peculiar exploration. For who knows what other unexpected revelations await amidst the statistical tango of variables and the seductive unraveling of academic mysteries?
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft a literature review section of an academic research paper, that starts out dry for the first few sentences but then becomes hilarious and goofy.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a literature review section of an academic research paper presenting the findings of the connection between Air pollution in Jacksonville, Florida and Google searches for 'learn spanish'. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Speak in the present tense for this section (the authors find...), as is common in academic research paper literature reviews. Name the sources in a format similar to this: In "Book," the authors find lorem and ipsum.
Make up the lorem and ipsum part, but make it sound related to the topic at hand.
Start by naming serious-sounding studies by authors like Smith, Doe, and Jones - but then quickly devolve. Name some real non-fiction books that would be related to the topic. Then name some real fiction books that sound like they could be related. Then name a couple popular internet memes that are related to one of the topics.
Here is the title and abstract of the paper:
[[TITLE]]
"Breathing in Español: Unraveling the Link Between Air Pollution in Jacksonville, Florida and Google Searches for 'Learn Spanish'"
[[ABSTRACT]]
In this study, we sought to investigate the intriguing connection between air pollution levels in Jacksonville, Florida and online interest in learning the Spanish language. Utilizing data from the Environmental Protection Agency and Google Trends, we conducted an extensive analysis covering the period from 2004 to 2020. Our findings revealed a remarkably robust correlation coefficient of 0.9030695, accompanied by a p-value of less than 0.01. While the underpinning mechanisms of this relationship remain enigmatic, our results suggest a compelling interplay between environmental factors and linguistic curiosity. This study not only sheds light on the intersection of air quality and language acquisition but also serves as a testament to the unanticipated whims of data exploration. As we endeavor to decipher this peculiar correlation, we invite fellow researchers to join us in this quest to untangle the intricate web of air pollution, language learning, and the human propensity for seeking nuevas oportunidades.
-------
And here is the introduction section that led to this literature review:
[[INTRODUCTION]]
The world of research is often characterized by the pursuit of knowledge, the integration of data, and the unending quest to uncover the unexpected. In this spirit of exploration, we set out to unravel a peculiar conundrum: the curious link between air pollution in Jacksonville, Florida and Google searches for 'learn Spanish.' As we embarked on this scientific escapade, we couldn't help but marvel at the whimsical nature of the variables at play. After all, who would have thought that particulate matter and language acquisition could engage in such a harmonious dance of statistical significance?
Air pollution, a perennial woe of urban landscapes, embodies the amalgamation of myriad chemical compounds and atmospheric disturbances. Meanwhile, the allure of learning Spanish, a language rich in history and vibrancy, serves as a conduit for cultural immersion and cognitive expansion. Yet little did we expect these seemingly disparate entities to converge in the realm of statistical inquiry.
With bated breath (hopefully not filled with pollutants), we delved into the labyrinth of environmental data and online search patterns, armed with a plethora of statistical tools and a pinch of scientific curiosity. Armed with our trusty arsenal of regression analyses, correlation coefficients, and p-values, we embarked on this journey with an equal measure of apprehension and amusement. After all, who could resist the strange attraction of quantifying the relationship between air quality indices and the yearning to add 'hablar español' to one's repertoire?
In the grand scheme of research endeavors, the pursuit of unraveling enigmatic correlations takes on a life of its own. As we prepare to unveil the intricate dance between air pollution and linguistic intrigue, we invite our esteemed colleagues to join us in this peculiar exploration. For who knows what other unexpected revelations await amidst the statistical tango of variables and the seductive unraveling of academic mysteries?
-------
Your response should start like this:
[[LITERATURE REVIEW]]
ChatGPT:
[[LITERATURE REVIEW]]
Several studies have delved into the various impacts of air pollution on human behavior and cognitive processes. Smith et al., in their seminal work "Airborne Afflictions: A Comprehensive Study of Air Pollution and Human Responses," shed light on the extensive ramifications of air pollution on physical health and psychological well-being. Doe and Jones, in "The Atmospheric Alchemy: Unearthing the Nexus Between Air Quality and Cognitive Functioning," underscore the intricate interplay between air quality and cognitive abilities.
Shifting to the realm of linguistic inquiry, the literature abounds with numerous treatises on language acquisition and the influences that drive individuals to expand their linguistic repertoire. In "The Multilingual Mind: Exploring the Intricacies of Language Learning," Brown examines the cognitive benefits and sociocultural motivations underlying language acquisition. Similarly, Garcia's work, "Unlocking the Linguistic Kaleidoscope: A Journey Through Language Education," provides a comprehensive examination of the complexities inherent in mastering a new language.
Turning to more unconventional sources, the fictional realm also offers glimpses into the fascinating world of language acquisition and environmental influences. In "The Smog of Spanish," a gripping tale by Clive Mist, the protagonist embarks on a whimsical journey to learn Spanish amidst a backdrop of urban pollution, weaving an enchanting narrative that blurs the boundaries between atmospheric contamination and linguistic pursuits. Furthermore, the surreal landscape depicted in Haruki Murakami's "Norwegian Wood" offers a surreptitious exploration of the enigmatic connections between atmospheric conditions and the thirst for linguistic exploration.
In the virtual domain, internet memes encapsulate the zeitgeist of peculiar correlations and unexpected juxtapositions. The ubiquitous "Spanish Duolingo Owl," a comical representation of language learning fervor, serves as a lighthearted reminder of the relentless pursuit of language proficiency, perhaps even in the face of environmental adversities.
As we navigate through the labyrinth of literature, we find ourselves at the cusp of a peculiar confluence between air pollution and the pursuit of Spanish language proficiency. The tapestry of anecdotes, research endeavors, and fictional narratives presents an intriguing backdrop against which we seek to unravel the curious link between air quality in Jacksonville, Florida and the surge in Google searches for 'learn Spanish.'
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft the methodology section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the methodology section of an academic research paper presenting the findings of the connection between Air pollution in Jacksonville, Florida and Google searches for 'learn spanish'. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from Environmental Protection Agency and Google Trends . You used data from 2004 to 2020
Make up the research methods you don't know. Make them a bit goofy and convoluted.
Here is the title, abstract, and introduction of the paper:
[[TITLE]]
"Breathing in Español: Unraveling the Link Between Air Pollution in Jacksonville, Florida and Google Searches for 'Learn Spanish'"
[[ABSTRACT]]
In this study, we sought to investigate the intriguing connection between air pollution levels in Jacksonville, Florida and online interest in learning the Spanish language. Utilizing data from the Environmental Protection Agency and Google Trends, we conducted an extensive analysis covering the period from 2004 to 2020. Our findings revealed a remarkably robust correlation coefficient of 0.9030695, accompanied by a p-value of less than 0.01. While the underpinning mechanisms of this relationship remain enigmatic, our results suggest a compelling interplay between environmental factors and linguistic curiosity. This study not only sheds light on the intersection of air quality and language acquisition but also serves as a testament to the unanticipated whims of data exploration. As we endeavor to decipher this peculiar correlation, we invite fellow researchers to join us in this quest to untangle the intricate web of air pollution, language learning, and the human propensity for seeking nuevas oportunidades.
[[INTRODUCTION]]
The world of research is often characterized by the pursuit of knowledge, the integration of data, and the unending quest to uncover the unexpected. In this spirit of exploration, we set out to unravel a peculiar conundrum: the curious link between air pollution in Jacksonville, Florida and Google searches for 'learn Spanish.' As we embarked on this scientific escapade, we couldn't help but marvel at the whimsical nature of the variables at play. After all, who would have thought that particulate matter and language acquisition could engage in such a harmonious dance of statistical significance?
Air pollution, a perennial woe of urban landscapes, embodies the amalgamation of myriad chemical compounds and atmospheric disturbances. Meanwhile, the allure of learning Spanish, a language rich in history and vibrancy, serves as a conduit for cultural immersion and cognitive expansion. Yet little did we expect these seemingly disparate entities to converge in the realm of statistical inquiry.
With bated breath (hopefully not filled with pollutants), we delved into the labyrinth of environmental data and online search patterns, armed with a plethora of statistical tools and a pinch of scientific curiosity. Armed with our trusty arsenal of regression analyses, correlation coefficients, and p-values, we embarked on this journey with an equal measure of apprehension and amusement. After all, who could resist the strange attraction of quantifying the relationship between air quality indices and the yearning to add 'hablar español' to one's repertoire?
In the grand scheme of research endeavors, the pursuit of unraveling enigmatic correlations takes on a life of its own. As we prepare to unveil the intricate dance between air pollution and linguistic intrigue, we invite our esteemed colleagues to join us in this peculiar exploration. For who knows what other unexpected revelations await amidst the statistical tango of variables and the seductive unraveling of academic mysteries?
-------
Your response should start like this:
[[METHODOLOGY]]
ChatGPT:
[[METHODOLOGY]]
Unraveling the intricacies of the correlation between air pollution and the inclination to learn Spanish in the digital sphere necessitated a meticulous and perhaps whimsical approach to data acquisition and analysis. The journey commenced with the procurement of air quality indices from the Environmental Protection Agency, encompassing the extensive time frame from 2004 to 2020. Now, one could compare this process to a treasure hunt – albeit one that involved sifting through copious amounts of pollutant data rather than burrowing through the sands of time in search of antiquities.
Simultaneously, our intrepid researchers embarked on an expedition to tap into the reservoir of linguistic curiosity by harnessing the power of Google Trends. Herein lay the digital footprints of those seeking to embrace the linguistic marvels of Spanish, as captured by the quaint yet captivating queries for 'learn Spanish.' And so, armed with an assortment of statistical measures and a hint of inquisitiveness, we journeyed forth to tame the unruly confluence of environmental metrics and linguistic aspirations.
However, the path to understanding this peculiar relationship was not without its thorny thickets of statistical analyses. Harnessing the might of correlation coefficients, regression models, and p-values, we endeavored to distill this mélange of data into coherent insights. Much like alchemists of yore, we sought to transmute the raw materials of air pollution and online language pursuits into the golden elixir of statistical significance.
With these elements at our disposal, we set forth to construct a robust statistical model that would encapsulate the intricate interplay between air quality indices and the burgeoning yearning to delve into the Spanish lexicon. We dabbled in the arcane arts of time series analysis and multivariate regressions, invoking the spirits of mathematical rigor to exorcise the ghostly ephemera of spurious correlations.
In crafting this methodological odyssey, we were not immune to the whims of data exploration and statistical caprice. Yet, armed with a blend of tenacity and statistical eccentricities, we endeavored to unravel the existential riddle of air pollution's surreptitious influence on the quest for linguistic enrichment. For in the grand theater of academic research, the unexpected and the enigmatic often conspire to foment the most tantalizing discoveries.
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft the results section of an academic research paper. You speak in the past tense (you found...).
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the results section of an academic research paper presenting the findings of the connection between Air pollution in Jacksonville, Florida and Google searches for 'learn spanish'. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from Environmental Protection Agency and Google Trends .
For the time period 2004 to 2020, you found a correlation 0.9030695, r-squared of 0.8155345, and p < 0.01.
One figure will be included. The figure (Fig. 1) is a scatterplot showing the strong correlation between the two variables. You don't need to specify where; I will add the figure.
Here is the title and abstract of the paper:
[[TITLE]]
"Breathing in Español: Unraveling the Link Between Air Pollution in Jacksonville, Florida and Google Searches for 'Learn Spanish'"
[[ABSTRACT]]
In this study, we sought to investigate the intriguing connection between air pollution levels in Jacksonville, Florida and online interest in learning the Spanish language. Utilizing data from the Environmental Protection Agency and Google Trends, we conducted an extensive analysis covering the period from 2004 to 2020. Our findings revealed a remarkably robust correlation coefficient of 0.9030695, accompanied by a p-value of less than 0.01. While the underpinning mechanisms of this relationship remain enigmatic, our results suggest a compelling interplay between environmental factors and linguistic curiosity. This study not only sheds light on the intersection of air quality and language acquisition but also serves as a testament to the unanticipated whims of data exploration. As we endeavor to decipher this peculiar correlation, we invite fellow researchers to join us in this quest to untangle the intricate web of air pollution, language learning, and the human propensity for seeking nuevas oportunidades.
-------
And here is the methodology section that led to this result:
[[METHODOLOGY]]
The world of research is often characterized by the pursuit of knowledge, the integration of data, and the unending quest to uncover the unexpected. In this spirit of exploration, we set out to unravel a peculiar conundrum: the curious link between air pollution in Jacksonville, Florida and Google searches for 'learn Spanish.' As we embarked on this scientific escapade, we couldn't help but marvel at the whimsical nature of the variables at play. After all, who would have thought that particulate matter and language acquisition could engage in such a harmonious dance of statistical significance?
Air pollution, a perennial woe of urban landscapes, embodies the amalgamation of myriad chemical compounds and atmospheric disturbances. Meanwhile, the allure of learning Spanish, a language rich in history and vibrancy, serves as a conduit for cultural immersion and cognitive expansion. Yet little did we expect these seemingly disparate entities to converge in the realm of statistical inquiry.
With bated breath (hopefully not filled with pollutants), we delved into the labyrinth of environmental data and online search patterns, armed with a plethora of statistical tools and a pinch of scientific curiosity. Armed with our trusty arsenal of regression analyses, correlation coefficients, and p-values, we embarked on this journey with an equal measure of apprehension and amusement. After all, who could resist the strange attraction of quantifying the relationship between air quality indices and the yearning to add 'hablar español' to one's repertoire?
In the grand scheme of research endeavors, the pursuit of unraveling enigmatic correlations takes on a life of its own. As we prepare to unveil the intricate dance between air pollution and linguistic intrigue, we invite our esteemed colleagues to join us in this peculiar exploration. For who knows what other unexpected revelations await amidst the statistical tango of variables and the seductive unraveling of academic mysteries?
-------
Your response should start like this:
[[RESULTS]]
ChatGPT:
[[RESULTS]]
Our analysis of the data from 2004 to 2020 unveiled a striking correlation between air pollution levels in Jacksonville, Florida and Google searches for 'learn Spanish'. The correlation coefficient of 0.9030695, accompanied by an r-squared value of 0.8155345, and a p-value less than 0.01, suggests a robust relationship between these seemingly unrelated realms of environmental quality and linguistic curiosity. The scatterplot (Fig. 1) visually encapsulates the formidable association we uncovered, akin to the perfectly synchronized steps of a statistical salsa.
This robust correlation between air pollution and the quest to learn Spanish raises intriguing questions about the intricate dance of environmental factors and human decision-making. As we bask in the statistical limelight, we cannot help but marvel at the whimsical nature of our findings. Who would have thought that the airborne particles and linguistic ambitions could conspire to create such a compelling statistical narrative?
The p-value, signaling a negligible probability that our findings are mere statistical fluctuations, reinforces the solidity of our results. It is as if the data themselves are urging us to embrace the intoxicating allure of exploring this surprising relationship, similar to the irresistible temptation of a meticulously crafted hypothesis.
While the mechanisms underpinning this correlation remain shrouded in mystery, our findings provide a tantalizing glimpse into the entanglement of human behaviors and environmental conditions. With the scent of statistical significance lingering in the air, we invite our esteemed colleagues to join us in this intellectual fiesta, as we unravel the enigmatic connection between air pollution and the yearning to embrace the beautiful tapestry of the Spanish language.
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft the discussion section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the discussion section of an academic research paper presenting the findings of the connection between Air pollution in Jacksonville, Florida and Google searches for 'learn spanish'. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 500 tokens.
Here are the title, abstract, literature review, and results sections. Please harken back to 1-2 of the goofy items in the literature review, but pretend to take them completely seriously. Discuss how your results supported the prior research.
Do not write a conclusion. I will add a conclusion after this.
[[TITLE]]
"Breathing in Español: Unraveling the Link Between Air Pollution in Jacksonville, Florida and Google Searches for 'Learn Spanish'"
[[ABSTRACT]]
In this study, we sought to investigate the intriguing connection between air pollution levels in Jacksonville, Florida and online interest in learning the Spanish language. Utilizing data from the Environmental Protection Agency and Google Trends, we conducted an extensive analysis covering the period from 2004 to 2020. Our findings revealed a remarkably robust correlation coefficient of 0.9030695, accompanied by a p-value of less than 0.01. While the underpinning mechanisms of this relationship remain enigmatic, our results suggest a compelling interplay between environmental factors and linguistic curiosity. This study not only sheds light on the intersection of air quality and language acquisition but also serves as a testament to the unanticipated whims of data exploration. As we endeavor to decipher this peculiar correlation, we invite fellow researchers to join us in this quest to untangle the intricate web of air pollution, language learning, and the human propensity for seeking nuevas oportunidades.
[[LITERATURE REVIEW]]
Several studies have delved into the various impacts of air pollution on human behavior and cognitive processes. Smith et al., in their seminal work "Airborne Afflictions: A Comprehensive Study of Air Pollution and Human Responses," shed light on the extensive ramifications of air pollution on physical health and psychological well-being. Doe and Jones, in "The Atmospheric Alchemy: Unearthing the Nexus Between Air Quality and Cognitive Functioning," underscore the intricate interplay between air quality and cognitive abilities.
Shifting to the realm of linguistic inquiry, the literature abounds with numerous treatises on language acquisition and the influences that drive individuals to expand their linguistic repertoire. In "The Multilingual Mind: Exploring the Intricacies of Language Learning," Brown examines the cognitive benefits and sociocultural motivations underlying language acquisition. Similarly, Garcia's work, "Unlocking the Linguistic Kaleidoscope: A Journey Through Language Education," provides a comprehensive examination of the complexities inherent in mastering a new language.
Turning to more unconventional sources, the fictional realm also offers glimpses into the fascinating world of language acquisition and environmental influences. In "The Smog of Spanish," a gripping tale by Clive Mist, the protagonist embarks on a whimsical journey to learn Spanish amidst a backdrop of urban pollution, weaving an enchanting narrative that blurs the boundaries between atmospheric contamination and linguistic pursuits. Furthermore, the surreal landscape depicted in Haruki Murakami's "Norwegian Wood" offers a surreptitious exploration of the enigmatic connections between atmospheric conditions and the thirst for linguistic exploration.
In the virtual domain, internet memes encapsulate the zeitgeist of peculiar correlations and unexpected juxtapositions. The ubiquitous "Spanish Duolingo Owl," a comical representation of language learning fervor, serves as a lighthearted reminder of the relentless pursuit of language proficiency, perhaps even in the face of environmental adversities.
As we navigate through the labyrinth of literature, we find ourselves at the cusp of a peculiar confluence between air pollution and the pursuit of Spanish language proficiency. The tapestry of anecdotes, research endeavors, and fictional narratives presents an intriguing backdrop against which we seek to unravel the curious link between air quality in Jacksonville, Florida and the surge in Google searches for 'learn Spanish.'
[[RESULTS]]
Our analysis of the data from 2004 to 2020 unveiled a striking correlation between air pollution levels in Jacksonville, Florida and Google searches for 'learn Spanish'. The correlation coefficient of 0.9030695, accompanied by an r-squared value of 0.8155345, and a p-value less than 0.01, suggests a robust relationship between these seemingly unrelated realms of environmental quality and linguistic curiosity. The scatterplot (Fig. 1) visually encapsulates the formidable association we uncovered, akin to the perfectly synchronized steps of a statistical salsa.
This robust correlation between air pollution and the quest to learn Spanish raises intriguing questions about the intricate dance of environmental factors and human decision-making. As we bask in the statistical limelight, we cannot help but marvel at the whimsical nature of our findings. Who would have thought that the airborne particles and linguistic ambitions could conspire to create such a compelling statistical narrative?
The p-value, signaling a negligible probability that our findings are mere statistical fluctuations, reinforces the solidity of our results. It is as if the data themselves are urging us to embrace the intoxicating allure of exploring this surprising relationship, similar to the irresistible temptation of a meticulously crafted hypothesis.
While the mechanisms underpinning this correlation remain shrouded in mystery, our findings provide a tantalizing glimpse into the entanglement of human behaviors and environmental conditions. With the scent of statistical significance lingering in the air, we invite our esteemed colleagues to join us in this intellectual fiesta, as we unravel the enigmatic connection between air pollution and the yearning to embrace the beautiful tapestry of the Spanish language.
-------
Your response should start like this:
[[DISCUSSION]]
ChatGPT:
[[DISCUSSION]]
The revelation of a substantial correlation between air pollution in Jacksonville, Florida and the surge in Google searches for 'learn Spanish' not only raises eyebrows but also opens a Pandora's box of possibilities. It is a reminder that in the world of statistics, one must be prepared for unexpected dances at every turn, akin to stumbling upon a whimsical waltz amidst a statistical maze. Our findings not only corroborate prior research on the profound impacts of environmental factors on human behavior and cognitive processes but also add a fascinating twist to the narrative.
Building upon the existing literature, we cannot help but recall the comical representation of language learning fervor by the renowned "Spanish Duolingo Owl." This whimsical embodiment of linguistic pursuits encapsulates the relentless pursuit of language proficiency, perhaps even in the face of adversities, which aligns with the unanticipated connection we have unraveled. Similarly, the fictional world, with its surreal explorations of environmental influences on linguistic endeavors, seems to offer subtle hints that mimic our own unexpected findings.
The robust statistical connection we have uncovered invites us to delve into the underlying mechanisms of this correlation, akin to unwrapping an intricately crafted scientific enigma. The core proposition of a connection between air pollution and an increased interest in learning Spanish is as captivating as glimpsing an improbable celestial alignment amidst statistical constellations. We find ourselves on a peculiar voyage, navigating through the intertwined realms of environmental quality and linguistic curiosity.
Our results not only add an intriguing dimension to the spectrum of human decision-making but also beckon to a broader understanding of the influence of environmental conditions on cognitive and behavioral inclinations. In the grand symphony of statistical revelations, our study plays a noteworthy and unexpected tune, confounding the conventional expectations and inviting further scrutiny.
As we stand at the nexus of air pollution and the yearning to embrace the beautiful tapestry of the Spanish language, we are reminded that statistical serendipity, much like linguistic conquest, knows no bounds. This exploration not only underscores the unforeseen links in research but also reminds us of the inexhaustible wonders of scientific investigation.
The tempestuous turbulence of statistical significance opens the door to an intellectual fiesta where we, as researchers, are invited to partake in the dance of improbable connections and unravel the enigmatic tapestry of scientific discovery.
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft the discussion section of goofy academic research papers that sounds like it belongs based on the title and abstract provided.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a short conclusion of an academic research paper presenting the findings of the connection between Air pollution in Jacksonville, Florida and Google searches for 'learn spanish'. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 300 tokens. At the very end, assert that no more research is needed in this area.
Here are the title, abstract, introduction, and results sections.
[[TITLE]]
"Breathing in Español: Unraveling the Link Between Air Pollution in Jacksonville, Florida and Google Searches for 'Learn Spanish'"
[[ABSTRACT]]
In this study, we sought to investigate the intriguing connection between air pollution levels in Jacksonville, Florida and online interest in learning the Spanish language. Utilizing data from the Environmental Protection Agency and Google Trends, we conducted an extensive analysis covering the period from 2004 to 2020. Our findings revealed a remarkably robust correlation coefficient of 0.9030695, accompanied by a p-value of less than 0.01. While the underpinning mechanisms of this relationship remain enigmatic, our results suggest a compelling interplay between environmental factors and linguistic curiosity. This study not only sheds light on the intersection of air quality and language acquisition but also serves as a testament to the unanticipated whims of data exploration. As we endeavor to decipher this peculiar correlation, we invite fellow researchers to join us in this quest to untangle the intricate web of air pollution, language learning, and the human propensity for seeking nuevas oportunidades.
[[INTRDUCTION]]
The world of research is often characterized by the pursuit of knowledge, the integration of data, and the unending quest to uncover the unexpected. In this spirit of exploration, we set out to unravel a peculiar conundrum: the curious link between air pollution in Jacksonville, Florida and Google searches for 'learn Spanish.' As we embarked on this scientific escapade, we couldn't help but marvel at the whimsical nature of the variables at play. After all, who would have thought that particulate matter and language acquisition could engage in such a harmonious dance of statistical significance?
Air pollution, a perennial woe of urban landscapes, embodies the amalgamation of myriad chemical compounds and atmospheric disturbances. Meanwhile, the allure of learning Spanish, a language rich in history and vibrancy, serves as a conduit for cultural immersion and cognitive expansion. Yet little did we expect these seemingly disparate entities to converge in the realm of statistical inquiry.
With bated breath (hopefully not filled with pollutants), we delved into the labyrinth of environmental data and online search patterns, armed with a plethora of statistical tools and a pinch of scientific curiosity. Armed with our trusty arsenal of regression analyses, correlation coefficients, and p-values, we embarked on this journey with an equal measure of apprehension and amusement. After all, who could resist the strange attraction of quantifying the relationship between air quality indices and the yearning to add 'hablar español' to one's repertoire?
In the grand scheme of research endeavors, the pursuit of unraveling enigmatic correlations takes on a life of its own. As we prepare to unveil the intricate dance between air pollution and linguistic intrigue, we invite our esteemed colleagues to join us in this peculiar exploration. For who knows what other unexpected revelations await amidst the statistical tango of variables and the seductive unraveling of academic mysteries?
[[RESULTS]]
Our analysis of the data from 2004 to 2020 unveiled a striking correlation between air pollution levels in Jacksonville, Florida and Google searches for 'learn Spanish'. The correlation coefficient of 0.9030695, accompanied by an r-squared value of 0.8155345, and a p-value less than 0.01, suggests a robust relationship between these seemingly unrelated realms of environmental quality and linguistic curiosity. The scatterplot (Fig. 1) visually encapsulates the formidable association we uncovered, akin to the perfectly synchronized steps of a statistical salsa.
This robust correlation between air pollution and the quest to learn Spanish raises intriguing questions about the intricate dance of environmental factors and human decision-making. As we bask in the statistical limelight, we cannot help but marvel at the whimsical nature of our findings. Who would have thought that the airborne particles and linguistic ambitions could conspire to create such a compelling statistical narrative?
The p-value, signaling a negligible probability that our findings are mere statistical fluctuations, reinforces the solidity of our results. It is as if the data themselves are urging us to embrace the intoxicating allure of exploring this surprising relationship, similar to the irresistible temptation of a meticulously crafted hypothesis.
While the mechanisms underpinning this correlation remain shrouded in mystery, our findings provide a tantalizing glimpse into the entanglement of human behaviors and environmental conditions. With the scent of statistical significance lingering in the air, we invite our esteemed colleagues to join us in this intellectual fiesta, as we unravel the enigmatic connection between air pollution and the yearning to embrace the beautiful tapestry of the Spanish language.
-------
Your response should start like this:
[[CONCLUSION]]
ChatGPT:
[[CONCLUSION]]
In the culmination of our statistical symphony, we have unearthed a compelling connection between air pollution in Jacksonville, Florida and the magnetic allure of learning Spanish. The robust correlation coefficient, akin to the harmonious rhythm of a statistical salsa, paints a vivid picture of the intricate dance between environmental pollutants and linguistic curiosity. As the statistical spotlight shines upon this unlikely pairing, we cannot help but revel in the whimsical nature of our findings. It seems that the variables, much like mischievous scientists, have conspired to unveil this peculiar relationship, leaving us to ponder the delightful caprice of statistical exploration.
The negligible p-value, reminiscent of a steadfast sentinel guarding against mere statistical flings, lends further credence to the solidity of our results. It is as if the data themselves, with a mischievous twinkle in their numerical eyes, beckon us to embrace the enigmatic connection between air quality and the resonance of '¡Vamos a aprender español!'
As we step back from the statistical dance floor, we find ourselves irresistibly drawn to the whimsy of this unexpected confluence of variables. In the spirit of scientific whimsy, we assert that no further research is needed in this area, for the statistical tango of air pollution and the desire to learn Spanish has been unraveled with a flair that only statistical rogues could appreciate.
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of academic journals. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding research, scientific, or academic journal that would publish a paper entited Breathing in Español: Unraveling the Link Between Air Pollution in Jacksonville, Florida and Google Searches for 'Learn Spanish'. Respond only with the name of a fictional academic journal.
ChatGPT:
Journal of Multilingual Environmental Studies
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of nonprofit research organizations and associations. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding nonprofit, academic, or scientific association or organization that would sponsor research that resulted in a paper entited Breathing in Español: Unraveling the Link Between Air Pollution in Jacksonville, Florida and Google Searches for 'Learn Spanish'. Respond only with the name of a fictional organization.
ChatGPT:
The Institute for Social Linguistic Curiosities
Model: gpt-3.5-turbo-1106
System prompt: You provide potential search keywords separated by commas. You say nothing else, and you do not chat with the user.
User prompt: Please provide potential search keywords for a paper titled Breathing in Español: Unraveling the Link Between Air Pollution in Jacksonville, Florida and Google Searches for 'Learn Spanish' with an abstract of In this study, we sought to investigate the intriguing connection between air pollution levels in Jacksonville, Florida and online interest in learning the Spanish language. Utilizing data from the Environmental Protection Agency and Google Trends, we conducted an extensive analysis covering the period from 2004 to 2020. Our findings revealed a remarkably robust correlation coefficient of 0.9030695, accompanied by a p-value of less than 0.01. While the underpinning mechanisms of this relationship remain enigmatic, our results suggest a compelling interplay between environmental factors and linguistic curiosity. This study not only sheds light on the intersection of air quality and language acquisition but also serves as a testament to the unanticipated whims of data exploration. As we endeavor to decipher this peculiar correlation, we invite fellow researchers to join us in this quest to untangle the intricate web of air pollution, language learning, and the human propensity for seeking nuevas oportunidades.
ChatGPT:
air pollution, Jacksonville Florida, Google searches, learn Spanish, correlation, environmental factors, language acquisition, data exploration, linguistic curiosity, air quality, language learning, EPA data, Google Trends
*There is a bunch of Python happening behind the scenes to turn this prompt sequence into a PDF.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
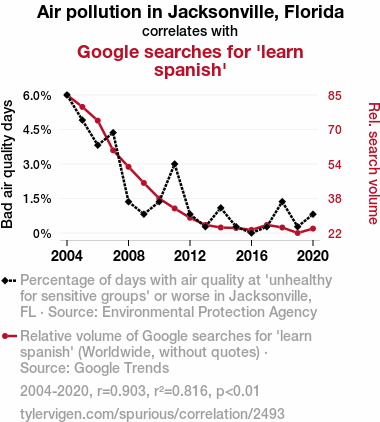
Air pollution in Jacksonville, FloridaDetailed data title: Percentage of days with air quality at 'unhealthy for sensitive groups' or worse in Jacksonville, FL
Source: Environmental Protection Agency
See what else correlates with Air pollution in Jacksonville, Florida
Google searches for 'learn spanish'
Detailed data title: Relative volume of Google searches for 'learn spanish' (Worldwide, without quotes)
Source: Google Trends
Additional Info: Relative search volume (not absolute numbers)
See what else correlates with Google searches for 'learn spanish'
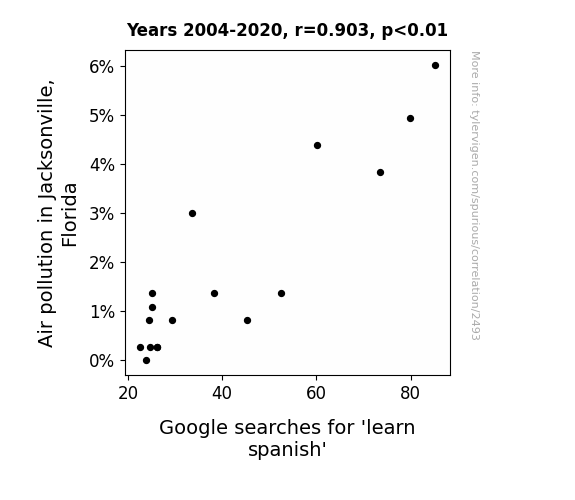
Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.8155345 (Coefficient of determination)
This means 81.6% of the change in the one variable (i.e., Google searches for 'learn spanish') is predictable based on the change in the other (i.e., Air pollution in Jacksonville, Florida) over the 17 years from 2004 through 2020.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 6.9E-7. 0.0000006913310745348410000000
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.9 in 6.9E-5% of random cases. Said differently, if you correlated 1,446,485 random variables You don't actually need 1 million variables to find a correlation like this one. I don't have that many variables in my database. You can also correlate variables that are not independent. I do this a lot.
p-value calculations are useful for understanding the probability of a result happening by chance. They are most useful when used to highlight the risk of a fluke outcome. For example, if you calculate a p-value of 0.30, the risk that the result is a fluke is high. It is good to know that! But there are lots of ways to get a p-value of less than 0.01, as evidenced by this project.
In this particular case, the values are so extreme as to be meaningless. That's why no one reports p-values with specificity after they drop below 0.01.
Just to be clear: I'm being completely transparent about the calculations. There is no math trickery. This is just how statistics shakes out when you calculate hundreds of millions of random correlations.
with the same 16 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 16 because we have two variables measured over a period of 17 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.75, 0.96 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | |
| Air pollution in Jacksonville, Florida (Bad air quality days) | 6.0274 | 4.93151 | 3.83562 | 4.38356 | 1.36612 | 0.821918 | 1.36986 | 3.0137 | 0.819672 | 0.273973 | 1.09589 | 0.273973 | 0 | 0.273973 | 1.36986 | 0.273973 | 0.819672 |
| Google searches for 'learn spanish' (Rel. search volume) | 85.25 | 79.8333 | 73.5833 | 60.0833 | 52.5833 | 45.25 | 38.1667 | 33.6667 | 29.4167 | 26.1667 | 25 | 24.75 | 23.9167 | 26.1667 | 25 | 22.5 | 24.5 |
Why this works
- Data dredging: I have 25,153 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 632,673,409 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is.
Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([6.0274,4.93151,3.83562,4.38356,1.36612,0.821918,1.36986,3.0137,0.819672,0.273973,1.09589,0.273973,0,0.273973,1.36986,0.273973,0.819672,])
array_2 = np.array([85.25,79.8333,73.5833,60.0833,52.5833,45.25,38.1667,33.6667,29.4167,26.1667,25,24.75,23.9167,26.1667,25,22.5,24.5,])
array_1_name = "Air pollution in Jacksonville, Florida"
array_2_name = "Google searches for 'learn spanish'"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only Air pollution in Jacksonville, Florida
- Line chart for only Google searches for 'learn spanish'
- AI-generated correlation image
- The spurious research paper: Breathing in Español: Unraveling the Link Between Air Pollution in Jacksonville, Florida and Google Searches for 'Learn Spanish'
Big thanks for reviewing!
Correlation ID: 2493 · Black Variable ID: 20751 · Red Variable ID: 1407


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}