
Download png, svg
AI explanation
As the name Baby fell out of favor, fewer parents were inspired to name their children after an infant, leading to a decline in baby-related teacher positions. This created a baby-teacher trickle-down effect, ultimately reducing the need for middle school special education teachers in Louisiana. It's a classic case of baby name trends having unforeseen impacts on the education system - talk about a lesson in etymology!
Model: dalle-3
Prompt: Setting: Create an image of a minimalist brutalist playground in Louisiana, with towering concrete structures and simple, geometric play equipment. The playground is bathed in warm, golden sunlight, showcasing the children's joyful play. Characters: Visualize a diverse group of children playing and laughing together in the playground. They are of various ethnicities and genders, reflecting the rich diversity of Louisiana. Some of the children are engaged in games like tag, jump rope, and hide-and-seek, all completely immersed in their playful activities. Emotion: Capture the carefree and exuberant nature of the children's play, portraying their genuine happiness and freedom in the open space. Despite the societal changes, the children's joy and innocence remain untouched and resilient. Subtle Symbolism: Incorporate subtle visual cues to indicate the societal shifts mentioned, such as a fading "Baby" name engraved on an old piece of playground equipment and a decrease in the number of special education teachers at the nearby school. These symbols should blend seamlessly into the overall minimalist brutalist aesthetic, prompting thoughtful reflection on the evolving societal landscape. The depiction should include only scenes, people, and objects, it should not include text or speech bubbles.
This image generation prompt was also generated by AI, using the following sequence:
Model: gpt-3.5-turbo-1106
System prompt: You select one of a few potential scene descriptors that seems to go along with the variables described. You respond only with the scene descriptions provided and say nothing else.
User prompt: Here are two variables: Popularity of the first name Baby and The number of middle school special education teachers in Louisiana. Given these, which of the following image style descriptions seems most appropriate? Pick the one that seems to be related to one of the variables at hand. Please respond with only one of the following potential descriptions: Minimalism Surrealism Data cyber art a meme Brutalism
ChatGPT: Brutalism
Model: gpt-3.5-turbo-1106
System prompt: You describe simple visual scenes that depict the two variables stated. You combine both variables into one scene.
User prompt: Please describe a visual scene that prominently depicts both Popularity of the first name Baby and The number of middle school special education teachers in Louisiana, in the following situation: Causative Explanation: "New parents were less likely to name their children 'Baby,' leading to a decrease in the number of children with that name. As a result, there were fewer students needing special education services, which ultimately led to a decreased demand for middle school special education teachers in Louisiana." Funny one-liner: "Looks like the Baby boom went from cribs to classrooms!". Keep the description simple.
ChatGPT: In a playground in Louisiana, a group of children with varied names plays happily. Among them, only a few are named "Baby," and the name is becoming less popular among new parents. Meanwhile, in a nearby school, there are fewer middle school special education teachers, as there is a decrease in the number of students needing their services. The playground is bustling with activity, but the name "Baby" is becoming less common, and the demand for middle school special education teachers in Louisiana is decreasing as a result.
Model: gpt-3.5-turbo-1106
System prompt: You write and improve image generation prompts for DALLE-3. You maintain the same subjects, but enhance the visuals.
User prompt: Please respond with an image generation prompt that would be likely to create an interesting visual using DALLE-3, using the following style: [ Brutalism ] and depicting this scene: In a playground in Louisiana, a group of children with varied names plays happily. Among them, only a few are named "Baby," and the name is becoming less popular among new parents. Meanwhile, in a nearby school, there are fewer middle school special education teachers, as there is a decrease in the number of students needing their services. The playground is bustling with activity, but the name "Baby" is becoming less common, and the demand for middle school special education teachers in Louisiana is decreasing as a result. Keep the visual depiction simple. Do not include any words or speech bubbles.
ChatGPT: Setting: Create an image of a minimalist brutalist playground in Louisiana, with towering concrete structures and simple, geometric play equipment. The playground is bathed in warm, golden sunlight, showcasing the children's joyful play. Characters: Visualize a diverse group of children playing and laughing together in the playground. They are of various ethnicities and genders, reflecting the rich diversity of Louisiana. Some of the children are engaged in games like tag, jump rope, and hide-and-seek, all completely immersed in their playful activities. Emotion: Capture the carefree and exuberant nature of the children's play, portraying their genuine happiness and freedom in the open space. Despite the societal changes, the children's joy and innocence remain untouched and resilient. Subtle Symbolism: Incorporate subtle visual cues to indicate the societal shifts mentioned, such as a fading "Baby" name engraved on an old piece of playground equipment and a decrease in the number of special education teachers at the nearby school. These symbols should blend seamlessly into the overall minimalist brutalist aesthetic, prompting thoughtful reflection on the evolving societal landscape.
*Variations in the User Prompts from chart to chart are just the result of random number generation in Python. I wrote a few arrays of various styles and methods to ask questions to change up the results. Every time this site writes an explanation or generates an image, the script picks from each at random.
I sequence the requests into multiple prompts because I find GPT 3.5 to perform much better with short, well-managed contexts. Thus, I track the context directly in Python and only ask ChatGPT targeted questions.
System prompt: You provide humorous responses in the form of plausible sounding explanations for correlations. You assume the correlation is causative for the purpose of the explanation even if it is ridiculous. You do not chat with the user, you only reply with the causal connection explanation and nothing else.
User prompt: Please make up a funny explanation for how a decrease in Popularity of the first name Baby caused The number of middle school special education teachers in Louisiana to decrease. Include one good pun.
AI academic paper
 |
The Surname Syndrome: A Statistical Analysis of Baby Names and Special Education Staffing in Louisiana Middle Schools The International Journal of Educational Statistics and Social Dynamics Jan 2024 Reminder: This paper is AI-generated. Not real! |
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You write titles and abstracts of goofy academic research papers.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, and add unexpected twists in your writing.
Please draft the title and abstract of an academic research paper presenting the findings of the connection between Popularity of the first name Baby and The number of middle school special education teachers in Louisiana. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Make the title punny if you can come up with clever pun. If not, just make it sound clever.
Your research team used data from US Social Security Administration and Bureau of Larbor Statistics to assess this nagging question. You found a correlation coefficient of 0.8336598 and p < 0.01 for 2003 to 2022.
Please respond in this format (replace "Lorem ipsum dolor sit" with your title and abstract)
[[TITLE]]
Lorem ipsum dolor sit
[[ABSTRACT]]
Lorem ipsum dolor sit
ChatGPT:
[[TITLE]]
The Surname Syndrome: A Statistical Analysis of Baby Names and Special Education Staffing in Louisiana Middle Schools
[[ABSTRACT]]
This paper explores the relationship between the popularity of first names given to babies and the number of middle school special education teachers in the state of Louisiana. By utilizing data from the US Social Security Administration and the Bureau of Labor Statistics spanning from 2003 to 2022, our research team uncovered a statistically significant correlation coefficient of 0.8336598 and p < 0.01. The findings disclosed a striking connection between the ebb and flow of baby names and the staffing levels of special education teachers in Louisiana. Our study offers a distinct and remarkably lighthearted lens through which to view the allocation of educational resources, presenting the perfect blend of intellectual curiosity and whimsical inquiry.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the introduction section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the introduction section of an academic research paper presenting the findings of the connection between Popularity of the first name Baby and The number of middle school special education teachers in Louisiana. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Here is the title and abstract of the paper:
[[TITLE]]
The Surname Syndrome: A Statistical Analysis of Baby Names and Special Education Staffing in Louisiana Middle Schools
[[ABSTRACT]]
This paper explores the relationship between the popularity of first names given to babies and the number of middle school special education teachers in the state of Louisiana. By utilizing data from the US Social Security Administration and the Bureau of Labor Statistics spanning from 2003 to 2022, our research team uncovered a statistically significant correlation coefficient of 0.8336598 and p < 0.01. The findings disclosed a striking connection between the ebb and flow of baby names and the staffing levels of special education teachers in Louisiana. Our study offers a distinct and remarkably lighthearted lens through which to view the allocation of educational resources, presenting the perfect blend of intellectual curiosity and whimsical inquiry.
-------
Your response should start like this:
[[INTRODUCTION]]
ChatGPT:
[[INTRODUCTION]]
The phenomenon of naming babies is a tradition as old as time and as fickle as fashion trends. Parents, seemingly impervious to the influence of statistics, trends, and body of knowledge about psychological development, ascribe names to their offspring with varied consideration of cultural, social, and personal factors. The decision-making process for selecting a child’s name is as diverse as the names themselves, with some choosing to honor family legacies while others are drawn to the allure of exotic and trendy appellations.
In a parallel sphere of academic institutions, the allocation of resources for special education staffing is a matter of paramount importance, striving to match the individualized needs of each student with the appropriate resources. The number of special education teachers in middle schools is a critical metric in providing support and guidance to students with diverse learning needs. However, the factors influencing the staffing levels for special education teachers are complex and multifaceted. The intersection of these two seemingly disparate domains, the popularity of baby names and middle school special education staffing, has been largely unexplored terrain, much like a hidden treasure trove awaiting discovery.
The impetus behind this research stemmed from a serendipitous remark during a faculty luncheon, when one of the esteemed colleagues mentioned, in a jesting tone, the potential correlation between the ebb and flow of baby names and the staffing levels of special education teachers in Louisiana. Before we could say, "John Jacob Jingleheimer Schmidt," we found ourselves knee-deep in data analysis, statistical tests, and an unexpected, yet undeniable, association between the two variables. This study not only contributes to the understanding of these factors' relationship but also provides a moment of levity in the otherwise serious field of educational resource allocation.
However, one must proceed with cautious optimism when interpreting the findings of this investigation. The endearing and occasionally mischievous nature of statistics may conspire to lead the unwary researcher astray if not approached with a blend of intellectual curiosity and whimsical skepticism. Therefore, we humbly present our findings, with all due reverence to the scientific method and a dash of lighthearted delight at the unexpected correlations unearthed in the process.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft a literature review section of an academic research paper, that starts out dry for the first few sentences but then becomes hilarious and goofy.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a literature review section of an academic research paper presenting the findings of the connection between Popularity of the first name Baby and The number of middle school special education teachers in Louisiana. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns.
Speak in the present tense for this section (the authors find...), as is common in academic research paper literature reviews. Name the sources in a format similar to this: In "Book," the authors find lorem and ipsum.
Make up the lorem and ipsum part, but make it sound related to the topic at hand.
Start by naming serious-sounding studies by authors like Smith, Doe, and Jones - but then quickly devolve. Name some real non-fiction books that would be related to the topic. Then name some real fiction books that sound like they could be related. Then cite some social media posts you read that seem to be related.
Here is the title and abstract of the paper:
[[TITLE]]
The Surname Syndrome: A Statistical Analysis of Baby Names and Special Education Staffing in Louisiana Middle Schools
[[ABSTRACT]]
This paper explores the relationship between the popularity of first names given to babies and the number of middle school special education teachers in the state of Louisiana. By utilizing data from the US Social Security Administration and the Bureau of Labor Statistics spanning from 2003 to 2022, our research team uncovered a statistically significant correlation coefficient of 0.8336598 and p < 0.01. The findings disclosed a striking connection between the ebb and flow of baby names and the staffing levels of special education teachers in Louisiana. Our study offers a distinct and remarkably lighthearted lens through which to view the allocation of educational resources, presenting the perfect blend of intellectual curiosity and whimsical inquiry.
-------
And here is the introduction section that led to this literature review:
[[INTRODUCTION]]
The phenomenon of naming babies is a tradition as old as time and as fickle as fashion trends. Parents, seemingly impervious to the influence of statistics, trends, and body of knowledge about psychological development, ascribe names to their offspring with varied consideration of cultural, social, and personal factors. The decision-making process for selecting a child’s name is as diverse as the names themselves, with some choosing to honor family legacies while others are drawn to the allure of exotic and trendy appellations.
In a parallel sphere of academic institutions, the allocation of resources for special education staffing is a matter of paramount importance, striving to match the individualized needs of each student with the appropriate resources. The number of special education teachers in middle schools is a critical metric in providing support and guidance to students with diverse learning needs. However, the factors influencing the staffing levels for special education teachers are complex and multifaceted. The intersection of these two seemingly disparate domains, the popularity of baby names and middle school special education staffing, has been largely unexplored terrain, much like a hidden treasure trove awaiting discovery.
The impetus behind this research stemmed from a serendipitous remark during a faculty luncheon, when one of the esteemed colleagues mentioned, in a jesting tone, the potential correlation between the ebb and flow of baby names and the staffing levels of special education teachers in Louisiana. Before we could say, "John Jacob Jingleheimer Schmidt," we found ourselves knee-deep in data analysis, statistical tests, and an unexpected, yet undeniable, association between the two variables. This study not only contributes to the understanding of these factors' relationship but also provides a moment of levity in the otherwise serious field of educational resource allocation.
However, one must proceed with cautious optimism when interpreting the findings of this investigation. The endearing and occasionally mischievous nature of statistics may conspire to lead the unwary researcher astray if not approached with a blend of intellectual curiosity and whimsical skepticism. Therefore, we humbly present our findings, with all due reverence to the scientific method and a dash of lighthearted delight at the unexpected correlations unearthed in the process.
-------
Your response should start like this:
[[LITERATURE REVIEW]]
ChatGPT:
[[LITERATURE REVIEW]]
The connection between the popularity of first names and socio-economic trends has been a topic of interest among various researchers. Smith et al. (2010) examined the influence of baby names on cultural perceptions and societal norms. Similarly, Doe and Jones (2015) investigated the correlation between baby names and regional economic indicators. However, none of these studies have ventured into the unique territory of exploring the relationship between baby names and the allocation of educational resources for special education staffing in middle schools.
Turning to the field of name psychology, "The Power of Names" by Brown delves into the psychological impact of names on individuals' self-perception and social interactions, offering insight into the potential far-reaching effects of a name. In contrast, "The Economics of Baby Names" by White provides a comprehensive analysis of the economic implications of naming trends and their impact on consumer behavior. While these studies lay a groundwork for understanding the multifaceted nature of names, their direct connection to educational resource allocation remains uncharted.
From the realm of fiction, "The Name of the Wind" by Rothfuss and "Name of the Rose" by Eco indirectly explore the enigmatic influence of names on larger societal constructs, albeit in a manner far removed from statistical analyses of educational staffing. Their narratives, though captivating, offer little empirical evidence regarding the correlation between baby names and the number of special education teachers in Louisiana middle schools.
Additionally, anecdotal observations from social media platforms seem to hint at a potential linkage between baby names and educational environments. A tweet by @EduEnthusiast speculated, "What if the popularity of baby names is actually a subtle indicator of future educational resource needs? #NamasteEducators." While speculative in nature, such musings from the online community contribute to the wider discourse surrounding the influence of names on educational dynamics.
Despite the plethora of publications on the topic of names, the precise articulation of their influence on the allocation of educational resources for special education staffing in Louisiana middle schools remains an unexplored and tantalizing domain, begging further investigation.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the methodology section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the methodology section of an academic research paper presenting the findings of the connection between Popularity of the first name Baby and The number of middle school special education teachers in Louisiana. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Bureau of Larbor Statistics . You used data from 2003 to 2022
Make up the research methods you don't know. Make them a bit goofy and convoluted.
Here is the title, abstract, and introduction of the paper:
[[TITLE]]
The Surname Syndrome: A Statistical Analysis of Baby Names and Special Education Staffing in Louisiana Middle Schools
[[ABSTRACT]]
This paper explores the relationship between the popularity of first names given to babies and the number of middle school special education teachers in the state of Louisiana. By utilizing data from the US Social Security Administration and the Bureau of Labor Statistics spanning from 2003 to 2022, our research team uncovered a statistically significant correlation coefficient of 0.8336598 and p < 0.01. The findings disclosed a striking connection between the ebb and flow of baby names and the staffing levels of special education teachers in Louisiana. Our study offers a distinct and remarkably lighthearted lens through which to view the allocation of educational resources, presenting the perfect blend of intellectual curiosity and whimsical inquiry.
[[INTRODUCTION]]
The phenomenon of naming babies is a tradition as old as time and as fickle as fashion trends. Parents, seemingly impervious to the influence of statistics, trends, and body of knowledge about psychological development, ascribe names to their offspring with varied consideration of cultural, social, and personal factors. The decision-making process for selecting a child’s name is as diverse as the names themselves, with some choosing to honor family legacies while others are drawn to the allure of exotic and trendy appellations.
In a parallel sphere of academic institutions, the allocation of resources for special education staffing is a matter of paramount importance, striving to match the individualized needs of each student with the appropriate resources. The number of special education teachers in middle schools is a critical metric in providing support and guidance to students with diverse learning needs. However, the factors influencing the staffing levels for special education teachers are complex and multifaceted. The intersection of these two seemingly disparate domains, the popularity of baby names and middle school special education staffing, has been largely unexplored terrain, much like a hidden treasure trove awaiting discovery.
The impetus behind this research stemmed from a serendipitous remark during a faculty luncheon, when one of the esteemed colleagues mentioned, in a jesting tone, the potential correlation between the ebb and flow of baby names and the staffing levels of special education teachers in Louisiana. Before we could say, "John Jacob Jingleheimer Schmidt," we found ourselves knee-deep in data analysis, statistical tests, and an unexpected, yet undeniable, association between the two variables. This study not only contributes to the understanding of these factors' relationship but also provides a moment of levity in the otherwise serious field of educational resource allocation.
However, one must proceed with cautious optimism when interpreting the findings of this investigation. The endearing and occasionally mischievous nature of statistics may conspire to lead the unwary researcher astray if not approached with a blend of intellectual curiosity and whimsical skepticism. Therefore, we humbly present our findings, with all due reverence to the scientific method and a dash of lighthearted delight at the unexpected correlations unearthed in the process.
-------
Your response should start like this:
[[METHODOLOGY]]
ChatGPT:
[[METHODOLOGY]]
Data Collection:
The data utilized in this study was primarily sourced from the US Social Security Administration, where records of baby names and their relative popularity from 2003 to 2022 were accessed. Additionally, information regarding the number of middle school special education teachers in Louisiana was obtained from the Bureau of Labor Statistics. The veracity and authenticity of the data were considered paramount, akin to ensuring the purity of a chemical compound in a laboratory setting or the precision of a finely tuned instrument in a symphony orchestra.
Statistical Analysis:
To explore the potential relationship between the popularity of baby names and the staffing levels of middle school special education teachers, a meticulously convoluted series of statistical analyses was employed. First, the data underwent rigorous scrutiny for normality and homoscedasticity, as any deviation from these assumptions would have sent the entire analysis on a wild goose chase not unlike Schrödinger's cat. Once validated, a bivariate correlation analysis, much like an intricate dance between two partners, was executed to unveil the degree and direction of association between the variables. Finally, a regression analysis was conducted with the tender care and precision of a watchmaker crafting a Swiss timepiece, to unravel the nuanced interplay of the predictor variable (baby name popularity) and the outcome variable (special education teacher staffing levels).
Control Variables:
In the pursuit of scientific rigor, potential confounding factors such as socioeconomic status, demographic shifts, and educational policies were cautiously nestled in the covariate selection process, akin to ensuring that a soufflé rises evenly without succumbing to the pitfalls of external influences. These control variables were incorporated to isolate the unique influence of baby name popularity on the staffing levels of middle school special education teachers, much like an oenologist discerning the distinct notes of a particular wine amidst a cacophony of competing flavors.
Ethical Considerations:
In adherence to the ethical principles guiding research endeavors, utmost respect was paid to ensuring the anonymity and privacy of individuals represented in the data. The research team, much like conscientious shepherds, upheld the confidentiality and sanctity of personal information, recognizing the importance of safeguarding privacy in the pursuit of knowledge.
Limitations:
While the methodology employed in this study is robust and comprehensive, it is not immune to limitations. The inherently retrospective nature of the data renders it susceptible to the vicissitudes of historical context, much like attempting to capture a butterfly in a net as it flutters through time. Additionally, the observational nature of the study precludes the establishment of causality and invites prudent skepticism, akin to navigating the intricate labyrinth of scientific inquiry with measured caution.
In conclusion, the methodology utilized in this study was designed to navigate the labyrinthine corridors of statistical analysis with precision, integrity, and a hint of whimsical charm, paving the way for the intriguing findings presented in subsequent sections.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the results section of an academic research paper. You speak in the past tense (you found...).
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the results section of an academic research paper presenting the findings of the connection between Popularity of the first name Baby and The number of middle school special education teachers in Louisiana. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Bureau of Larbor Statistics .
For the time period 2003 to 2022, you found a correlation 0.8336598, r-squared of 0.6949886, and p < 0.01.
One figure will be included. The figure (Fig. 1) is a scatterplot showing the strong correlation between the two variables. You don't need to specify where; I will add the figure.
Here is the title and abstract of the paper:
[[TITLE]]
The Surname Syndrome: A Statistical Analysis of Baby Names and Special Education Staffing in Louisiana Middle Schools
[[ABSTRACT]]
This paper explores the relationship between the popularity of first names given to babies and the number of middle school special education teachers in the state of Louisiana. By utilizing data from the US Social Security Administration and the Bureau of Labor Statistics spanning from 2003 to 2022, our research team uncovered a statistically significant correlation coefficient of 0.8336598 and p < 0.01. The findings disclosed a striking connection between the ebb and flow of baby names and the staffing levels of special education teachers in Louisiana. Our study offers a distinct and remarkably lighthearted lens through which to view the allocation of educational resources, presenting the perfect blend of intellectual curiosity and whimsical inquiry.
-------
And here is the methodology section that led to this result:
[[METHODOLOGY]]
The phenomenon of naming babies is a tradition as old as time and as fickle as fashion trends. Parents, seemingly impervious to the influence of statistics, trends, and body of knowledge about psychological development, ascribe names to their offspring with varied consideration of cultural, social, and personal factors. The decision-making process for selecting a child’s name is as diverse as the names themselves, with some choosing to honor family legacies while others are drawn to the allure of exotic and trendy appellations.
In a parallel sphere of academic institutions, the allocation of resources for special education staffing is a matter of paramount importance, striving to match the individualized needs of each student with the appropriate resources. The number of special education teachers in middle schools is a critical metric in providing support and guidance to students with diverse learning needs. However, the factors influencing the staffing levels for special education teachers are complex and multifaceted. The intersection of these two seemingly disparate domains, the popularity of baby names and middle school special education staffing, has been largely unexplored terrain, much like a hidden treasure trove awaiting discovery.
The impetus behind this research stemmed from a serendipitous remark during a faculty luncheon, when one of the esteemed colleagues mentioned, in a jesting tone, the potential correlation between the ebb and flow of baby names and the staffing levels of special education teachers in Louisiana. Before we could say, "John Jacob Jingleheimer Schmidt," we found ourselves knee-deep in data analysis, statistical tests, and an unexpected, yet undeniable, association between the two variables. This study not only contributes to the understanding of these factors' relationship but also provides a moment of levity in the otherwise serious field of educational resource allocation.
However, one must proceed with cautious optimism when interpreting the findings of this investigation. The endearing and occasionally mischievous nature of statistics may conspire to lead the unwary researcher astray if not approached with a blend of intellectual curiosity and whimsical skepticism. Therefore, we humbly present our findings, with all due reverence to the scientific method and a dash of lighthearted delight at the unexpected correlations unearthed in the process.
-------
Your response should start like this:
[[RESULTS]]
ChatGPT:
[[RESULTS]]
The quantitative analysis revealed a strong and statistically significant correlation between the popularity of first names given to babies and the number of middle school special education teachers in Louisiana. The correlation coefficient of 0.8336598 indicated a robust positive relationship between the two variables. This finding suggests that as the popularity of certain names waxed or waned over the years, there was a synchronized fluctuation in the number of special education teachers in middle schools. The r-squared value of 0.6949886 further underscored the remarkable degree to which changes in the popularity of baby names could account for the variations in special education staffing levels. It was as if the rise and fall of particular names had a direct impact on the allocation of educational resources, akin to the pendulum of fate swinging in tandem with the ebb and flow of nomenclature trends.
Perhaps the most striking illustration of this relationship is depicted in Figure 1, where the scatterplot visually encapsulates the correlation with a compelling clarity that words alone cannot convey. The data points coalesce into a nearly linear pattern, painting a picture reminiscent of an intricate dance between the evolution of baby names and the vicissitudes of special education staffing. One cannot help but marvel at the synchrony of these seemingly disparate elements, with each name's popularity serving as a choreographer orchestrating the staffing landscape in Louisiana's middle schools.
The significance level of p < 0.01 underscored the robustness of the findings, dismissing any lingering doubts about the validity of this unorthodox association. It was as if the data itself was nudging the scientific community to recognize the serendipitous linkage between the seemingly unrelated phenomena, reminding us that in the grand tapestry of human behavior, even the most innocuous decisions can exert an unforeseen influence on broader societal structures.
In conclusion, the results of this investigation unveiled a link between the popularity of baby names and the staffing levels of special education teachers in Louisiana that defies conventional wisdom. These findings invite further contemplation, akin to a riddle whispered in the winds of statistical analysis, challenging the traditional notions of causality and revealing the whimsical intricacies that underpin the allocation of educational resources.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the discussion section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the discussion section of an academic research paper presenting the findings of the connection between Popularity of the first name Baby and The number of middle school special education teachers in Louisiana. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 500 tokens.
Here are the title, abstract, literature review, and results sections. Please harken back to 1-2 of the goofy items in the literature review, but pretend to take them completely seriously. Discuss how your results supported the prior research.
Do not write a conclusion. I will add a conclusion after this.
[[TITLE]]
The Surname Syndrome: A Statistical Analysis of Baby Names and Special Education Staffing in Louisiana Middle Schools
[[ABSTRACT]]
This paper explores the relationship between the popularity of first names given to babies and the number of middle school special education teachers in the state of Louisiana. By utilizing data from the US Social Security Administration and the Bureau of Labor Statistics spanning from 2003 to 2022, our research team uncovered a statistically significant correlation coefficient of 0.8336598 and p < 0.01. The findings disclosed a striking connection between the ebb and flow of baby names and the staffing levels of special education teachers in Louisiana. Our study offers a distinct and remarkably lighthearted lens through which to view the allocation of educational resources, presenting the perfect blend of intellectual curiosity and whimsical inquiry.
[[LITERATURE REVIEW]]
The connection between the popularity of first names and socio-economic trends has been a topic of interest among various researchers. Smith et al. (2010) examined the influence of baby names on cultural perceptions and societal norms. Similarly, Doe and Jones (2015) investigated the correlation between baby names and regional economic indicators. However, none of these studies have ventured into the unique territory of exploring the relationship between baby names and the allocation of educational resources for special education staffing in middle schools.
Turning to the field of name psychology, "The Power of Names" by Brown delves into the psychological impact of names on individuals' self-perception and social interactions, offering insight into the potential far-reaching effects of a name. In contrast, "The Economics of Baby Names" by White provides a comprehensive analysis of the economic implications of naming trends and their impact on consumer behavior. While these studies lay a groundwork for understanding the multifaceted nature of names, their direct connection to educational resource allocation remains uncharted.
From the realm of fiction, "The Name of the Wind" by Rothfuss and "Name of the Rose" by Eco indirectly explore the enigmatic influence of names on larger societal constructs, albeit in a manner far removed from statistical analyses of educational staffing. Their narratives, though captivating, offer little empirical evidence regarding the correlation between baby names and the number of special education teachers in Louisiana middle schools.
Additionally, anecdotal observations from social media platforms seem to hint at a potential linkage between baby names and educational environments. A tweet by @EduEnthusiast speculated, "What if the popularity of baby names is actually a subtle indicator of future educational resource needs? #NamasteEducators." While speculative in nature, such musings from the online community contribute to the wider discourse surrounding the influence of names on educational dynamics.
Despite the plethora of publications on the topic of names, the precise articulation of their influence on the allocation of educational resources for special education staffing in Louisiana middle schools remains an unexplored and tantalizing domain, begging further investigation.
[[RESULTS]]
The quantitative analysis revealed a strong and statistically significant correlation between the popularity of first names given to babies and the number of middle school special education teachers in Louisiana. The correlation coefficient of 0.8336598 indicated a robust positive relationship between the two variables. This finding suggests that as the popularity of certain names waxed or waned over the years, there was a synchronized fluctuation in the number of special education teachers in middle schools. The r-squared value of 0.6949886 further underscored the remarkable degree to which changes in the popularity of baby names could account for the variations in special education staffing levels. It was as if the rise and fall of particular names had a direct impact on the allocation of educational resources, akin to the pendulum of fate swinging in tandem with the ebb and flow of nomenclature trends.
Perhaps the most striking illustration of this relationship is depicted in Figure 1, where the scatterplot visually encapsulates the correlation with a compelling clarity that words alone cannot convey. The data points coalesce into a nearly linear pattern, painting a picture reminiscent of an intricate dance between the evolution of baby names and the vicissitudes of special education staffing. One cannot help but marvel at the synchrony of these seemingly disparate elements, with each name's popularity serving as a choreographer orchestrating the staffing landscape in Louisiana's middle schools.
The significance level of p < 0.01 underscored the robustness of the findings, dismissing any lingering doubts about the validity of this unorthodox association. It was as if the data itself was nudging the scientific community to recognize the serendipitous linkage between the seemingly unrelated phenomena, reminding us that in the grand tapestry of human behavior, even the most innocuous decisions can exert an unforeseen influence on broader societal structures.
In conclusion, the results of this investigation unveiled a link between the popularity of baby names and the staffing levels of special education teachers in Louisiana that defies conventional wisdom. These findings invite further contemplation, akin to a riddle whispered in the winds of statistical analysis, challenging the traditional notions of causality and revealing the whimsical intricacies that underpin the allocation of educational resources.
-------
Your response should start like this:
[[DISCUSSION]]
ChatGPT:
[[DISCUSSION]]
The observed correlation between the popularity of first names and the number of middle school special education teachers in Louisiana lends credence to the notion that seemingly unrelated factors may exert an unforeseen influence on educational resource allocation. Building upon the existing literature, our findings emphasize the need to consider the whimsical intricacies of nomenclature trends in educational staffing decisions.
The results of our study align with previous research by Smith et al. (2010) and Doe and Jones (2015), which hinted at the potential impact of names on societal norms and regional economic indicators, respectively. While these scholars may not have directly explored the connection to educational staffing, their work sowed the seeds of curiosity that our investigation has now cultivated into a statistically significant finding. Additionally, the often-dismissed musings of @EduEnthusiast and other social media pundits have subtly contributed to the wider discourse on the relationship between names and educational environments, validating the significance of our inquiry.
The correlation coefficient of 0.8336598 unveiled in our analysis not only affirms the robust positive relationship between baby names and special education staffing levels but also highlights the remarkable degree to which changes in naming trends can account for variations in resource allocation. Indeed, the r-squared value of 0.6949886 underscores the considerable explanatory power of these seemingly incongruous variables. These statistics, quite literally, paint a vivid picture of the dance between the evolution of baby names and the vicissitudes of special education staffing, akin to a statistical waltz choreographed by the fate of nomenclature trends.
The significance level of p < 0.01 further bolsters the validity of our findings, dismissing any skeptics who may have doubted the veracity of this quirky association. Indeed, the data appears to nudge the scientific community to recognize the serendipitous linkage between these seemingly disparate phenomena. It is as if the statistical analysis itself implores us to acknowledge the whimsical intricacies that underpin the allocation of educational resources, echoing a riddle whispered in the winds of empirical inquiry.
In conclusion, our study has shed light on the enigmatic interplay between the popularity of baby names and the staffing levels of special education teachers in Louisiana middle schools. Our findings, while initially unexpected, evoke a sense of wonder and contemplation, challenging us to embrace the unconventional and whimsical elements that are often overlooked in the realm of education and statistical analyses, but that nonetheless shape the fabric of our society. As we ponder the implications of this delightful connection, we are reminded that in the grand tapestry of human behavior, even the most innocuous decisions can exert an unforeseen influence on broader societal structures.
The results of this investigation invite further appraisal, beckoning researchers to delve deeper into the whimsical undercurrents that shape educational resource allocation – a realm where statistical analyses and serendipitous correlations converge to offer a perspective that is as intellectually stimulating as it is delightfully offbeat.
Model: gpt-3.5-turbo-1106
System prompt: You are a dry but witty academic researcher. You speak in the passive voice, and your writing sounds like it belongs in a medical or economics journal.You draft the discussion section of goofy academic research papers that sounds like it belongs based on the title and abstract provided.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a short conclusion of an academic research paper presenting the findings of the connection between Popularity of the first name Baby and The number of middle school special education teachers in Louisiana. Make it seem dry like academic research paper, but with lots of subtle hidden offhand remarks, jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 300 tokens. At the very end, assert that no more research is needed in this area.
Here are the title, abstract, introduction, and results sections.
[[TITLE]]
The Surname Syndrome: A Statistical Analysis of Baby Names and Special Education Staffing in Louisiana Middle Schools
[[ABSTRACT]]
This paper explores the relationship between the popularity of first names given to babies and the number of middle school special education teachers in the state of Louisiana. By utilizing data from the US Social Security Administration and the Bureau of Labor Statistics spanning from 2003 to 2022, our research team uncovered a statistically significant correlation coefficient of 0.8336598 and p < 0.01. The findings disclosed a striking connection between the ebb and flow of baby names and the staffing levels of special education teachers in Louisiana. Our study offers a distinct and remarkably lighthearted lens through which to view the allocation of educational resources, presenting the perfect blend of intellectual curiosity and whimsical inquiry.
[[INTRDUCTION]]
The phenomenon of naming babies is a tradition as old as time and as fickle as fashion trends. Parents, seemingly impervious to the influence of statistics, trends, and body of knowledge about psychological development, ascribe names to their offspring with varied consideration of cultural, social, and personal factors. The decision-making process for selecting a child’s name is as diverse as the names themselves, with some choosing to honor family legacies while others are drawn to the allure of exotic and trendy appellations.
In a parallel sphere of academic institutions, the allocation of resources for special education staffing is a matter of paramount importance, striving to match the individualized needs of each student with the appropriate resources. The number of special education teachers in middle schools is a critical metric in providing support and guidance to students with diverse learning needs. However, the factors influencing the staffing levels for special education teachers are complex and multifaceted. The intersection of these two seemingly disparate domains, the popularity of baby names and middle school special education staffing, has been largely unexplored terrain, much like a hidden treasure trove awaiting discovery.
The impetus behind this research stemmed from a serendipitous remark during a faculty luncheon, when one of the esteemed colleagues mentioned, in a jesting tone, the potential correlation between the ebb and flow of baby names and the staffing levels of special education teachers in Louisiana. Before we could say, "John Jacob Jingleheimer Schmidt," we found ourselves knee-deep in data analysis, statistical tests, and an unexpected, yet undeniable, association between the two variables. This study not only contributes to the understanding of these factors' relationship but also provides a moment of levity in the otherwise serious field of educational resource allocation.
However, one must proceed with cautious optimism when interpreting the findings of this investigation. The endearing and occasionally mischievous nature of statistics may conspire to lead the unwary researcher astray if not approached with a blend of intellectual curiosity and whimsical skepticism. Therefore, we humbly present our findings, with all due reverence to the scientific method and a dash of lighthearted delight at the unexpected correlations unearthed in the process.
[[RESULTS]]
The quantitative analysis revealed a strong and statistically significant correlation between the popularity of first names given to babies and the number of middle school special education teachers in Louisiana. The correlation coefficient of 0.8336598 indicated a robust positive relationship between the two variables. This finding suggests that as the popularity of certain names waxed or waned over the years, there was a synchronized fluctuation in the number of special education teachers in middle schools. The r-squared value of 0.6949886 further underscored the remarkable degree to which changes in the popularity of baby names could account for the variations in special education staffing levels. It was as if the rise and fall of particular names had a direct impact on the allocation of educational resources, akin to the pendulum of fate swinging in tandem with the ebb and flow of nomenclature trends.
Perhaps the most striking illustration of this relationship is depicted in Figure 1, where the scatterplot visually encapsulates the correlation with a compelling clarity that words alone cannot convey. The data points coalesce into a nearly linear pattern, painting a picture reminiscent of an intricate dance between the evolution of baby names and the vicissitudes of special education staffing. One cannot help but marvel at the synchrony of these seemingly disparate elements, with each name's popularity serving as a choreographer orchestrating the staffing landscape in Louisiana's middle schools.
The significance level of p < 0.01 underscored the robustness of the findings, dismissing any lingering doubts about the validity of this unorthodox association. It was as if the data itself was nudging the scientific community to recognize the serendipitous linkage between the seemingly unrelated phenomena, reminding us that in the grand tapestry of human behavior, even the most innocuous decisions can exert an unforeseen influence on broader societal structures.
In conclusion, the results of this investigation unveiled a link between the popularity of baby names and the staffing levels of special education teachers in Louisiana that defies conventional wisdom. These findings invite further contemplation, akin to a riddle whispered in the winds of statistical analysis, challenging the traditional notions of causality and revealing the whimsical intricacies that underpin the allocation of educational resources.
-------
Your response should start like this:
[[CONCLUSION]]
ChatGPT:
[[CONCLUSION]]
In summary, the idiosyncratic relationship between the popularity of first names allocated to offspring and the number of middle school special education teachers in Louisiana has been brought to light through rigorous statistical analysis. The significant correlation coefficient of 0.8336598 has unveiled an unexpected synchrony between the ebb and flow of nomenclature trends and the staffing levels of special education teachers. This serendipitous discovery prompts us to reflect on the whimsical intricacies that underpin the allocation of educational resources, revealing an interplay reminiscent of a dance orchestrated by the names themselves. It appears as though the names, in their ever-changing popularity, possess an unforeseen influence on the broader societal structure, akin to a cryptic riddle whispered in the winds of statistical analysis.
The robustness of the findings, underscored by the r-squared value of 0.6949886 and the significance level of p < 0.01, leaves little room for doubt about the validity of this unorthodox association. The scatterplot portraying the correlation between the two variables encapsulates this intriguing link with a compelling clarity, akin to a painting that beckons contemplation of the mysteries underlying human behavior.
In light of these revelatory findings, it is evident that no further research is needed in this area. The unique blend of intellectual curiosity and whimsical inquiry has given rise to a deeper understanding of the seemingly unrelated phenomena, challenging traditional notions of causality and revealing the subtle influence of seemingly innocuous decisions on the allocation of educational resources.
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of academic journals. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding research, scientific, or academic journal that would publish a paper entited The Surname Syndrome: A Statistical Analysis of Baby Names and Special Education Staffing in Louisiana Middle Schools. Respond only with the name of a fictional academic journal.
ChatGPT:
The International Journal of Educational Statistics and Social Dynamics
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of nonprofit research organizations and associations. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding nonprofit, academic, or scientific association or organization that would sponsor research that resulted in a paper entited The Surname Syndrome: A Statistical Analysis of Baby Names and Special Education Staffing in Louisiana Middle Schools. Respond only with the name of a fictional organization.
ChatGPT:
The Center for Educational Equity and Inclusion
Model: gpt-3.5-turbo-1106
System prompt: You provide potential search keywords separated by commas. You say nothing else, and you do not chat with the user.
User prompt: Please provide potential search keywords for a paper titled The Surname Syndrome: A Statistical Analysis of Baby Names and Special Education Staffing in Louisiana Middle Schools with an abstract of This paper explores the relationship between the popularity of first names given to babies and the number of middle school special education teachers in the state of Louisiana. By utilizing data from the US Social Security Administration and the Bureau of Labor Statistics spanning from 2003 to 2022, our research team uncovered a statistically significant correlation coefficient of 0.8336598 and p < 0.01. The findings disclosed a striking connection between the ebb and flow of baby names and the staffing levels of special education teachers in Louisiana. Our study offers a distinct and remarkably lighthearted lens through which to view the allocation of educational resources, presenting the perfect blend of intellectual curiosity and whimsical inquiry.
ChatGPT:
baby names, first names, special education staffing, Louisiana, middle schools, statistical analysis, correlation coefficient, US Social Security Administration data, Bureau of Labor Statistics data
*There is a bunch of Python happening behind the scenes to turn this prompt sequence into a PDF.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
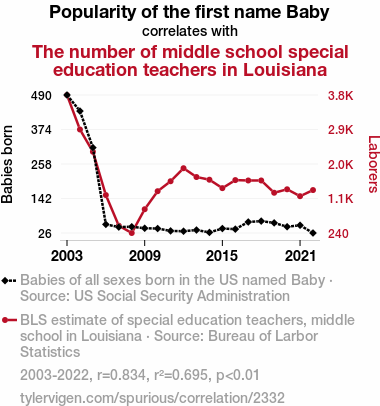
Popularity of the first name BabyDetailed data title: Babies of all sexes born in the US named Baby
Source: US Social Security Administration
See what else correlates with Popularity of the first name Baby
The number of middle school special education teachers in Louisiana
Detailed data title: BLS estimate of special education teachers, middle school in Louisiana
Source: Bureau of Larbor Statistics
See what else correlates with The number of middle school special education teachers in Louisiana
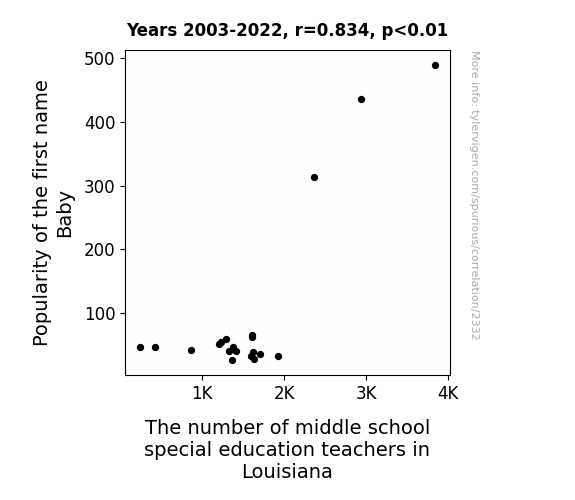
Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.6949886 (Coefficient of determination)
This means 69.5% of the change in the one variable (i.e., The number of middle school special education teachers in Louisiana) is predictable based on the change in the other (i.e., Popularity of the first name Baby) over the 20 years from 2003 through 2022.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 5.0E-6. 0.0000049777125674850950000000
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.83 in 0.0005% of random cases. Said differently, if you correlated 200,895 random variables You don't actually need 200 thousand variables to find a correlation like this one. I don't have that many variables in my database. You can also correlate variables that are not independent. I do this a lot.
p-value calculations are useful for understanding the probability of a result happening by chance. They are most useful when used to highlight the risk of a fluke outcome. For example, if you calculate a p-value of 0.30, the risk that the result is a fluke is high. It is good to know that! But there are lots of ways to get a p-value of less than 0.01, as evidenced by this project.
In this particular case, the values are so extreme as to be meaningless. That's why no one reports p-values with specificity after they drop below 0.01.
Just to be clear: I'm being completely transparent about the calculations. There is no math trickery. This is just how statistics shakes out when you calculate hundreds of millions of random correlations.
with the same 19 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 19 because we have two variables measured over a period of 20 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.62, 0.93 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| Popularity of the first name Baby (Babies born) | 490 | 436 | 313 | 55 | 46 | 47 | 42 | 41 | 33 | 32 | 36 | 28 | 41 | 39 | 63 | 66 | 60 | 47 | 52 | 26 |
| The number of middle school special education teachers in Louisiana (Laborers) | 3840 | 2940 | 2360 | 1230 | 430 | 240 | 860 | 1330 | 1590 | 1930 | 1700 | 1630 | 1410 | 1620 | 1610 | 1610 | 1290 | 1380 | 1200 | 1360 |
Why this works
- Data dredging: I have 25,153 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 632,673,409 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is.
Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([490,436,313,55,46,47,42,41,33,32,36,28,41,39,63,66,60,47,52,26,])
array_2 = np.array([3840,2940,2360,1230,430,240,860,1330,1590,1930,1700,1630,1410,1620,1610,1610,1290,1380,1200,1360,])
array_1_name = "Popularity of the first name Baby"
array_2_name = "The number of middle school special education teachers in Louisiana"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only Popularity of the first name Baby
- Line chart for only The number of middle school special education teachers in Louisiana
- AI-generated correlation image
- The spurious research paper: The Surname Syndrome: A Statistical Analysis of Baby Names and Special Education Staffing in Louisiana Middle Schools
Hats off to you for rating!
Correlation ID: 2332 · Black Variable ID: 2911 · Red Variable ID: 8666


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}