
Download png, svg
Check back later, or email me if you'd enjoy seeing this work in real-time.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
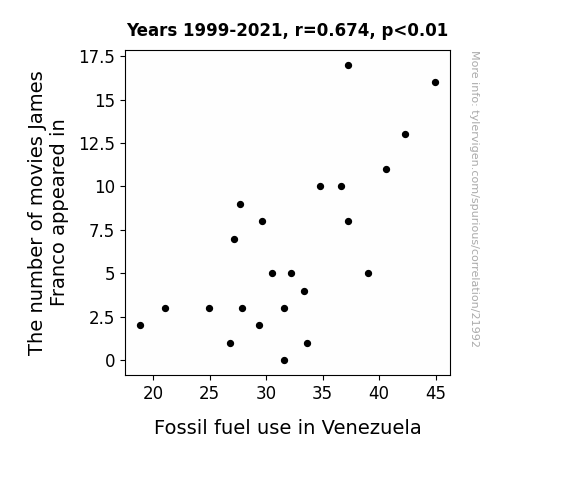
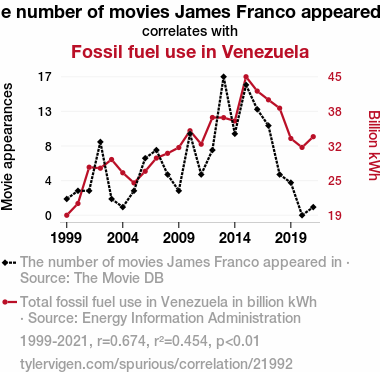
The number of movies James Franco appeared inSource: The Movie DB
Additional Info: James Dean (2001); Tristan & Isolde (2006); Flyboys (2006); Annapolis (2006); Sonny (2002); Good Time Max (2008); 127 Hours (2010); The Ape (2005); Howl (2010); Shadows & Lies (2010); Oz the Great and Powerful (2013); The Broken Tower (2012); The Hills with James Franco and Mila Kunis (2007); Eames: The Architect and the Painter (2011); Spring Breakers (2013); The Letter (2012); This Is the End (2013); As I Lay Dying (2013); Maladies (2012); Erased James Franco (2009); The Color of Time (2012); Every Thing Will Be Fine (2015); Good People (2014); Black Dog, Red Dog (2015); The Sound and the Fury (2015); I Am Michael (2015); Yosemite (2016); Comedy Central Roast of James Franco (2013); The Interview (2014); National Theatre Live: Of Mice and Men (2014); In Dubious Battle (2016); Zeroville (2019); The Heyday of the Insensitive Bastards (2015); The Adderall Diaries (2016); Future Relic 02 (2014); The Disaster Artist (2017); Grasshopper (2006); Blind Spot (2003); The Car Kid (2002); Obituaries (2014); At Any Cost (2000); Actors Anonymous (2017); The Mad Whale (2017); Future World (2018); Killing Animals (2015); Masculinity & Me (2010); A Walk in Winter (2015); The Labyrinth (2017); Arctic Dogs (2019); The Institute (2017); The Vault (2017); Mississippi Requiem (2018); The Long Home (2021); High School Lover (2017); Blood Heist (2017); The Room Before and After - Part 1: James Franco (2009); Roast of James Franco: Red Carpet Pre-Show (2013); If Tomorrow Comes (2000); Dave Skylark's Very Special VMA Special (2014); Hart Crane: An Exegesis (2012); Caput (2011); Fool's Gold (2005); Pineapple Express (2008); Camille (2008); Mother, May I Sleep with Danger? (2016); Rise of the Planet of the Apes (2011); Your Highness (2011); Mean People Suck (2001); Homefront (2013); True Story (2015); Wild Horses (2015); Queen of the Desert (2015); Why Him? (2016); A Fuller Life (2013); Pretenders (2019); Behind the Scenes of Palo Alto (2014); Spider-Man 3 (2007); Spider-Man 2 (2004); City by the Sea (2002); The Great Raid (2005); Eat Pray Love (2010); The Company (2003); Child of God (2014); Sal (2013); Memoria (2016); Saturday Night (2010); Burn Country (2016); Interview (2007); Alien: Covenant - Prologue: Last Supper (2017); Playtime (2013); Spider-Man (2002); Whatever It Takes (2000); Third Person (2013); Palo Alto (2013); King Cobra (2016); The Caged Pillows (2016); You Always Stalk the Ones You Love (2002); Don't Come Back from the Moon (2019); Freaks and Geeks: The Documentary (2018); Here Comes the Night Time (2013); Spider-Mania (2002); Milk (2008); In the Valley of Elah (2007); The Dead Girl (2006); Kin (2018); Some Body (2001); To Serve and Protect (1999); Blood Surf (2016); The Iceman (2012); Mother Ghost (2002); The Little Prince (2015); Sausage Party (2016); Don Quixote: The Ingenious Gentleman of La Mancha (2015); Finishing the Game: The Search for a New Bruce Lee (2007); About Cherry (2012); Never Been Kissed (1999); 14 Actors Acting (2010); Lovelace (2013); Goat (2016); Marina Abramović: The Artist Is Present (2012); The 4%: Film's Gender Problem (2016); Behind the Ultimate Spin: The Making of 'Spider-Man' (2002); SNL Presents: A Very Gilly Christmas (2009); An American Crime (2007); With Great Power: The Stan Lee Story (2010); Call Me Lucky (2015); Richard Peter Johnson (2015); Mademoiselle C (2013); Date Night (2010); Love and Distrust (2010); Deuces Wild (2002); Interior. Leather Bar. (2013); The Ballad of Buster Scruggs (2018); The Night Before (2015); Killers Kill, Dead Men Die (2007); What Is Cinema? (2013); The Show (2017); Alien: Covenant (2017); Nights in Rodanthe (2008); Saturday Night Live: 40th Anniversary Special (2015); The Wicker Man (2006); Dawn of the Planet of the Apes (2014); The Holiday (2006); Spider-Man: All Roads Lead to No Way Home (2022); The Green Hornet (2011); Veronica Mars (2014); Knocked Up (2007)
See what else correlates with The number of movies James Franco appeared in
Fossil fuel use in Venezuela
Detailed data title: Total fossil fuel use in Venezuela in billion kWh
Source: Energy Information Administration
See what else correlates with Fossil fuel use in Venezuela
Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.4541811 (Coefficient of determination)
This means 45.4% of the change in the one variable (i.e., Fossil fuel use in Venezuela) is predictable based on the change in the other (i.e., The number of movies James Franco appeared in) over the 23 years from 1999 through 2021.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 0.00042. 0.0004222731289225667700000000
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.67 in 0.042% of random cases. Said differently, if you correlated 2,368 random variables Which I absolutely did.
with the same 22 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 22 because we have two variables measured over a period of 23 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.36, 0.85 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | |
| The number of movies James Franco appeared in (Movie appearances) | 2 | 3 | 3 | 9 | 2 | 1 | 3 | 7 | 8 | 5 | 3 | 10 | 5 | 8 | 17 | 10 | 16 | 13 | 11 | 5 | 4 | 0 | 1 |
| Fossil fuel use in Venezuela (Billion kWh) | 18.828 | 21.042 | 27.888 | 27.706 | 29.34 | 26.842 | 24.928 | 27.12 | 29.6138 | 30.5086 | 31.601 | 34.7659 | 32.2335 | 37.2663 | 37.2381 | 36.6121 | 44.9527 | 42.2474 | 40.6014 | 39.0194 | 33.307 | 31.6238 | 33.6477 |
Why this works
- Data dredging: I have 25,237 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 636,906,169 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is. - Y-axis doesn't start at zero: I truncated the Y-axes of the graph above. I also used a line graph, which makes the visual connection stand out more than it deserves.
Nothing against line graphs. They are great at telling a story when you have linear data! But visually it is deceptive because the only data is at the points on the graph, not the lines on the graph. In between each point, the data could have been doing anything. Like going for a random walk by itself!
Mathematically what I showed is true, but it is intentionally misleading. Below is the same chart but with both Y-axes starting at zero.

Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([2,3,3,9,2,1,3,7,8,5,3,10,5,8,17,10,16,13,11,5,4,0,1,])
array_2 = np.array([18.828,21.042,27.888,27.706,29.34,26.842,24.928,27.12,29.6138,30.5086,31.601,34.7659,32.2335,37.2663,37.2381,36.6121,44.9527,42.2474,40.6014,39.0194,33.307,31.6238,33.6477,])
array_1_name = "The number of movies James Franco appeared in"
array_2_name = "Fossil fuel use in Venezuela"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only The number of movies James Franco appeared in
- Line chart for only Fossil fuel use in Venezuela
You're the correlation whisperer we needed!
Correlation ID: 21992 · Black Variable ID: 26516 · Red Variable ID: 24095


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}