
Download png, svg
Check back later, or email me if you'd enjoy seeing this work in real-time.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
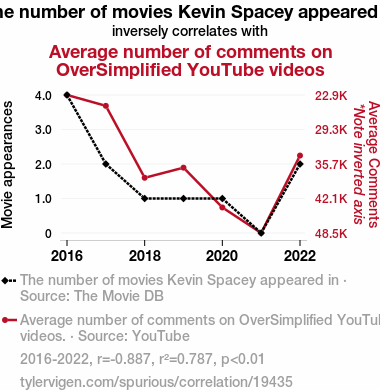
The number of movies Kevin Spacey appeared inSource: The Movie DB
Additional Info: American Beauty (1999); Pay It Forward (2000); Swimming with Sharks (1994); Shrink (2009); The Shipping News (2001); Beyond the Sea (2004); The Life of David Gale (2003); Look, Up in the Sky! The Amazing Story of Superman (2006); Ordinary Decent Criminal (2000); Father of Invention (2010); Recount (2008); The Big Kahuna (1999); Casino Jack (2010); Darrow (1991); Margin Call (2011); Inseparable (2012); Envelope (2012); Spirit of a Denture (2012); The Ventriloquist (2012); NOW: In the Wings on a World Stage (2014); Elvis & Nixon (2016); Hitchcock: Shadow of a Genius (1999); America Rebuilds: A Year at Ground Zero (2002); Nine Lives (2016); The Interrogation of Leo and Lisa (2006); Shackleton's Antarctic Adventure (2001); Once Upon a Time in Croatia (2022); Control (2023); Being Frank With Tucker (2023); K-PAX (2001); The Usual Suspects (1995); Superman Returns (2006); 21 (2008); Midnight in the Garden of Good and Evil (1997); Hurlyburly (1998); Iron Will (1994); A Bug's Life (1998); The Negotiator (1998); Telstar: The Joe Meek Story (2008); Hackers Wanted (2009); Doomsday Gun (1994); Fall From Grace (1990); When You Remember Me (1990); Billionaire Boys Club (2018); Rebel in the Rye (2017); Baby Driver (2017); Pursuing the Suspects (2002); The Man Who Drew God (2023); Moon (2009); ¿Quien mató a Jeffrey Epstein? (2020); L.A. Confidential (1997); The Ref (1994); Consenting Adults (1992); Looking for Richard (1996); A Time to Kill (1996); Edison (2005); The Men Who Stare at Goats (2009); See No Evil, Hear No Evil (1989); Dad (1989); Outbreak (1995); The United States of Leland (2003); Henry & June (1990); Horrible Bosses (2011); Long Day's Journey Into Night (1987); The Organ Grinder's Monkey (2011); Horrible Bosses 2 (2014); A Show of Force (1990); Glengarry Glen Ross (1992); The Final Days (2000); Mad As Hell (2014); Rocket Gibraltar (1988); Se7en (1995); Keyser Soze, Lie or Legend - Featurette (2002); Whatever You Desire: Making 'L.A. Confidential' (2008); Working Girl (1988); Sunlight and Shadow: The Visual Style of 'L.A. Confidential' (2008); Declaration of Independence (2003); Jack Lemmon: America's Everyman (1996); Fred Claus (2007); How Did They Ever Make a Movie of Facebook? (2011); American Beauty: Look Closer... (2000); Prince Andrew: Banished (2022); Heartburn (1986); Round Up: Deposing 'The Usual Suspects' (2002); Untouchable (2019); Forever Hollywood (1999); Tony Bennett Celebrates 90 (2016); Austin Powers in Goldmember (2002); Playboy Mansion Parties Uncensored (2001); Final Cut: Ladies and Gentlemen (2012); Unity (2015); All Governments Lie: Truth, Deception, and the Spirit of I.F. Stone (2016); The Pixar Story (2007)
See what else correlates with The number of movies Kevin Spacey appeared in
Average number of comments on OverSimplified YouTube videos
Detailed data title: Average number of comments on OverSimplified YouTube videos.
Source: YouTube
See what else correlates with Average number of comments on OverSimplified YouTube videos
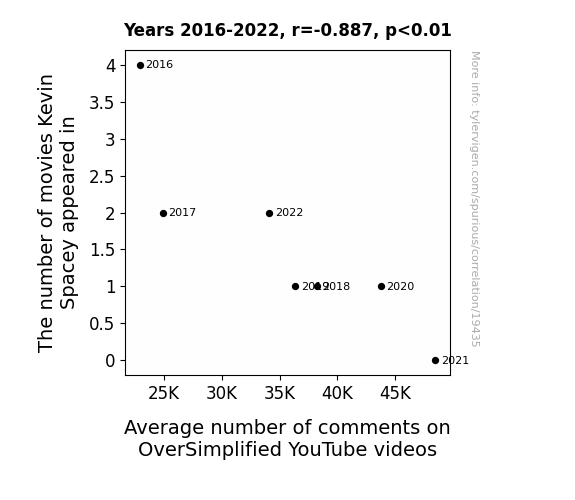
Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.7869710 (Coefficient of determination)
This means 78.7% of the change in the one variable (i.e., Average number of comments on OverSimplified YouTube videos) is predictable based on the change in the other (i.e., The number of movies Kevin Spacey appeared in) over the 7 years from 2016 through 2022.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 0.0077. 0.0077316631387967130000000000
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as -0.89 in 0.77% of random cases. Said differently, if you correlated 129 random variables Which I absolutely did.
with the same 6 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 6 because we have two variables measured over a period of 7 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ -0.98, -0.4 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| The number of movies Kevin Spacey appeared in (Movie appearances) | 4 | 2 | 1 | 1 | 1 | 0 | 2 |
| Average number of comments on OverSimplified YouTube videos (Average Comments) | 22914.5 | 24921 | 38231.8 | 36362.3 | 43726 | 48451.7 | 34121.5 |
Why this works
- Data dredging: I have 25,237 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 636,906,169 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is. - Very low n: There are not many data points included in this analysis. Even if the p-value is high, we should be suspicious of using so few datapoints in a correlation.
- Y-axis doesn't start at zero: I truncated the Y-axes of the graph above. I also used a line graph, which makes the visual connection stand out more than it deserves.
Nothing against line graphs. They are great at telling a story when you have linear data! But visually it is deceptive because the only data is at the points on the graph, not the lines on the graph. In between each point, the data could have been doing anything. Like going for a random walk by itself!
Mathematically what I showed is true, but it is intentionally misleading. Below is the same chart but with both Y-axes starting at zero. - Inverted Y-axis: I inverted the Y-axis on the chart above so that the lines would move together. This is visually pleasing, but not at all intuitive. Below is a line graph that does not invert the Y-axis.

Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([4,2,1,1,1,0,2,])
array_2 = np.array([22914.5,24921,38231.8,36362.3,43726,48451.7,34121.5,])
array_1_name = "The number of movies Kevin Spacey appeared in"
array_2_name = "Average number of comments on OverSimplified YouTube videos"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only The number of movies Kevin Spacey appeared in
- Line chart for only Average number of comments on OverSimplified YouTube videos
Your rating is stellar!
Correlation ID: 19435 · Black Variable ID: 26693 · Red Variable ID: 25625


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}