
Download png, svg
AI explanation
As the name Kalin fell out of favor, fewer people were inspired to pen tales in the land of the delawriters. It seems the Kalin impact on authorship in Delaware was quite the story plot twist!
Model: dalle-3
Prompt: Prompt: Create an image of a bustling street in Delaware at twilight, with warm street lamps casting a soft glow. People in various and unique attire chatter while strolling along the cobblestone road. On one side of the street, a sign stands prominently with the words "Kalins Wanted: Future Authors Need Apply," adorned with shimmering fairy lights. On the opposite side, a line of aspiring authors eagerly waits, their faces illuminated by a sense of hope. As each applicant becomes a Kalin, a bright wisp of light leaves the line, causing it to gradually dwindle until it disappears entirely. The scene transforms as the once lively street becomes quieter, capturing the melancholic beauty of this societal shift. The depiction should include only scenes, people, and objects, it should not include text or speech bubbles.
This image generation prompt was also generated by AI, using the following sequence:
Model: gpt-3.5-turbo-1106
System prompt: You select one of a few potential scene descriptors that seems to go along with the situation described. You respond only with the scene descriptions provided and say nothing else.
User prompt: Here is a situation: Because the decrease in popularity of the first name Kalin led to a shortage of potential parents for future authors in Delaware, ultimately causing a decrease in the number of authors in the state. It's simple demographics, really - no more Kalins, no more Delaware authors.. Given that situation, which of the following image descriptions seems most appropriate? Pick the one that seems to be related to one of the variables at hand and the tone of the explanation. Please respond with only one of the following potential descriptions: Sci-fi fantacy Magic realism Photorealism Cute 2D animation Low poly
ChatGPT: Magic realism
Model: gpt-3.5-turbo-1106
System prompt: You describe simple visual scenes that depict the two variables stated and the explanation described. Do not reference graphs or charts; describe physical objects.
User prompt: Please describe a visual scene that depicts the following situation. Keep the description simple. Because the decrease in popularity of the first name Kalin led to a shortage of potential parents for future authors in Delaware, ultimately causing a decrease in the number of authors in the state. It's simple demographics, really - no more Kalins, no more Delaware authors.
ChatGPT: Imagine a bustling street in Delaware, with people walking by and chatting. On one side of the street, you see a sign that reads "Kalins Wanted: Future Authors Need Apply." On the other side, you see a line of aspiring authors waiting eagerly. As the number of Kalins decreases, the line of aspiring authors gets shorter and shorter, eventually vanishing altogether. The once lively street becomes quieter, symbolizing the decrease in the number of authors in the state.
Model: gpt-3.5-turbo-1106
System prompt: You write and improve image generation prompts for DALLE-3. You maintain the same subjects, but enhance the visuals.
User prompt: Please respond with an image generation prompt that would be likely to create an interesting visual using DALLE-3, using the following style: [ Magic realism ] and depicting this scene: Imagine a bustling street in Delaware, with people walking by and chatting. On one side of the street, you see a sign that reads "Kalins Wanted: Future Authors Need Apply." On the other side, you see a line of aspiring authors waiting eagerly. As the number of Kalins decreases, the line of aspiring authors gets shorter and shorter, eventually vanishing altogether. The once lively street becomes quieter, symbolizing the decrease in the number of authors in the state. Keep the visual depiction simple. Do not include any words or speech bubbles.
ChatGPT: Prompt: Create an image of a bustling street in Delaware at twilight, with warm street lamps casting a soft glow. People in various and unique attire chatter while strolling along the cobblestone road. On one side of the street, a sign stands prominently with the words "Kalins Wanted: Future Authors Need Apply," adorned with shimmering fairy lights. On the opposite side, a line of aspiring authors eagerly waits, their faces illuminated by a sense of hope. As each applicant becomes a Kalin, a bright wisp of light leaves the line, causing it to gradually dwindle until it disappears entirely. The scene transforms as the once lively street becomes quieter, capturing the melancholic beauty of this societal shift.
*Variations in the User Prompts from chart to chart are just the result of random number generation in Python. I wrote a few arrays of various styles and methods to ask questions to change up the results. Every time this site writes an explanation or generates an image, the script picks from each at random.
I sequence the requests into multiple prompts because I find GPT 3.5 to perform much better with short, well-managed contexts. Thus, I track the context directly in Python and only ask ChatGPT targeted questions.
System prompt: You provide humorous responses in the form of plausible sounding explanations for correlations. You assume the correlation is causative for the purpose of the explanation even if it is ridiculous. You do not chat with the user, you only reply with the causal connection explanation and nothing else.
User prompt: Please make up a funny explanation for how a decrease in Popularity of the first name Kalin caused The number of authors in Delaware to decrease. Include one good pun.
AI academic paper
 |
The Kalin Conundrum: Connections Between Name Popularity and Authorship in Delaware Journal of Nameology Jan 2024 Reminder: This paper is AI-generated. Not real! |
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You write titles and abstracts of goofy academic research papers.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, and add unexpected twists in your writing.
Please draft the title and abstract of an academic research paper presenting the findings of the connection between Popularity of the first name Kalin and The number of authors in Delaware. Make lots of jokes, goofy observations, and puns.
Make the title an alliteration.
Your research team used data from US Social Security Administration and Bureau of Larbor Statistics to assess this nagging question. You found a correlation coefficient of 0.8347688 and p < 0.01 for 2003 to 2022.
Please respond in this format (replace "Lorem ipsum dolor sit" with your title and abstract)
[[TITLE]]
Lorem ipsum dolor sit
[[ABSTRACT]]
Lorem ipsum dolor sit
ChatGPT:
[[TITLE]]
The Kalin Conundrum: Connections Between Name Popularity and Authorship in Delaware
[[ABSTRACT]]
In the vast landscape of statistical analyses, our research delved into the intriguing relationship between the popularity of the first name Kalin and the number of authors in the delightful state of Delaware. With tongue-in-cheek precision, we harnessed data from the US Social Security Administration and the Bureau of Labor Statistics to tackle this whimsical yet pressing question. Our paper presents the formidable correlation coefficient of 0.8347688 and p < 0.01 for the period spanning from 2003 to 2022, unveiling an unexpected and humorous connection. As we unravel this enigma, prepare to be both amused and enlightened by the peculiar intersection of nomenclature and authorship.
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft the introduction section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the introduction section of an academic research paper presenting the findings of the connection between Popularity of the first name Kalin and The number of authors in Delaware. Make lots of jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Here is the title and abstract of the paper:
[[TITLE]]
The Kalin Conundrum: Connections Between Name Popularity and Authorship in Delaware
[[ABSTRACT]]
In the vast landscape of statistical analyses, our research delved into the intriguing relationship between the popularity of the first name Kalin and the number of authors in the delightful state of Delaware. With tongue-in-cheek precision, we harnessed data from the US Social Security Administration and the Bureau of Labor Statistics to tackle this whimsical yet pressing question. Our paper presents the formidable correlation coefficient of 0.8347688 and p < 0.01 for the period spanning from 2003 to 2022, unveiling an unexpected and humorous connection. As we unravel this enigma, prepare to be both amused and enlightened by the peculiar intersection of nomenclature and authorship.
-------
Your response should start like this:
[[INTRODUCTION]]
ChatGPT:
[[INTRODUCTION]]
Ah, the mysteries of science and statistics! As researchers, we often find ourselves knee-deep in data, striving to uncover the correlations that lie beneath the surface. In this study, we set out on a delightful journey to explore the curious relationship between the popularity of the first name Kalin and the abundance of authors in the charming state of Delaware. Who would have thought that a name could bear such weight in the realm of literary creation? Join us as we unravel this peculiar conundrum with a dash of humor and a sprinkle of statistical wizardry.
Picture this: the sun-soaked streets of Delaware, bustling with literary minds weaving tales of intrigue and wonder. Meanwhile, amidst the pages of Social Security Administration data, the name "Kalin" emerges as a beacon of statistical curiosity. Is it pure coincidence, or could there be a cosmic connection between nomenclature and the written word?
As we embarked on our statistical escapade, we couldn't help but marvel at the whimsy of this investigation. With each data point and regression analysis, we found ourselves tumbling down the rabbit hole of name popularity and its unexpected links to the sprawling world of authorship. It's a tale of numbers and nomenclature, a fusion of academia and amusement, and a dash of statistical serendipity that will enliven even the most stoic of academics.
So grab your magnifying glass and suspend your disbelief, for we're about to unveil a correlation that will have you chuckling and scratching your head in equal measures. Get ready to join us on this rollercoaster ride of numbers, names, and the delightful state of Delaware.
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft a literature review section of an academic research paper, that starts out dry for the first few sentences but then becomes hilarious and goofy.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a literature review section of an academic research paper presenting the findings of the connection between Popularity of the first name Kalin and The number of authors in Delaware. Make lots of jokes, goofy observations, and puns.
Speak in the present tense for this section (the authors find...), as is common in academic research paper literature reviews. Name the sources in a format similar to this: In "Book," the authors find lorem and ipsum.
Make up the lorem and ipsum part, but make it sound related to the topic at hand.
Start by naming serious-sounding studies by authors like Smith, Doe, and Jones - but then quickly devolve. Name some real non-fiction books that would be related to the topic. Then name some real fiction books that sound like they could be related. Then you might move on to cartoons and children's shows that you watched for research.
Here is the title and abstract of the paper:
[[TITLE]]
The Kalin Conundrum: Connections Between Name Popularity and Authorship in Delaware
[[ABSTRACT]]
In the vast landscape of statistical analyses, our research delved into the intriguing relationship between the popularity of the first name Kalin and the number of authors in the delightful state of Delaware. With tongue-in-cheek precision, we harnessed data from the US Social Security Administration and the Bureau of Labor Statistics to tackle this whimsical yet pressing question. Our paper presents the formidable correlation coefficient of 0.8347688 and p < 0.01 for the period spanning from 2003 to 2022, unveiling an unexpected and humorous connection. As we unravel this enigma, prepare to be both amused and enlightened by the peculiar intersection of nomenclature and authorship.
-------
And here is the introduction section that led to this literature review:
[[INTRODUCTION]]
Ah, the mysteries of science and statistics! As researchers, we often find ourselves knee-deep in data, striving to uncover the correlations that lie beneath the surface. In this study, we set out on a delightful journey to explore the curious relationship between the popularity of the first name Kalin and the abundance of authors in the charming state of Delaware. Who would have thought that a name could bear such weight in the realm of literary creation? Join us as we unravel this peculiar conundrum with a dash of humor and a sprinkle of statistical wizardry.
Picture this: the sun-soaked streets of Delaware, bustling with literary minds weaving tales of intrigue and wonder. Meanwhile, amidst the pages of Social Security Administration data, the name "Kalin" emerges as a beacon of statistical curiosity. Is it pure coincidence, or could there be a cosmic connection between nomenclature and the written word?
As we embarked on our statistical escapade, we couldn't help but marvel at the whimsy of this investigation. With each data point and regression analysis, we found ourselves tumbling down the rabbit hole of name popularity and its unexpected links to the sprawling world of authorship. It's a tale of numbers and nomenclature, a fusion of academia and amusement, and a dash of statistical serendipity that will enliven even the most stoic of academics.
So grab your magnifying glass and suspend your disbelief, for we're about to unveil a correlation that will have you chuckling and scratching your head in equal measures. Get ready to join us on this rollercoaster ride of numbers, names, and the delightful state of Delaware.
-------
Your response should start like this:
[[LITERATURE REVIEW]]
ChatGPT:
[[LITERATURE REVIEW]]
In "The Name Game," Smith and Doe delve into the fascinating world of nomenclature and its potential impact on various aspects of life. While their focus is on broader societal implications, one cannot help but wonder about the influence of names on the literary landscape. Similarly, in "The Influence of Names on Destiny," Jones presents compelling arguments about the significance of names in shaping individuals' paths. These works set the stage for our whimsical investigation into the correlation between the first name Kalin and the number of authors in Delaware.
Turning to non-fiction books, "Freakonomics" by Steven D. Levitt and Stephen J. Dubner offers an insightful perspective on unconventional connections and unexpected correlations. Perhaps our study will join the ranks of peculiar yet intriguing associations that spark a delightful sense of wonder. On the fictional front, "The Name of the Wind" by Patrick Rothfuss and "The Shadow of the Wind" by Carlos Ruiz Zafón beckon readers into the realm of names, stories, and enigmatic connections. Can our research provide a real-world plot twist akin to these captivating narratives?
As we ventured further into the realm of unexpected inspirations, we turned to cartoons and children's shows. Remember the antics of "SpongeBob SquarePants" and his whimsical adventures in Bikini Bottom? Who would have guessed that our statistical escapade in Delaware could rival the absurdity of a pineapple-dwelling sea sponge? And let's not forget the educational musings of "Sesame Street" – an unlikely source of inspiration for our lighthearted exploration into the eccentric ties between a name and an author's lair in the land of Delaware.
With a new lens on the intersection of name popularity and authorship, our research branches into uncharted territory, infusing academia with a touch of levity and a sprinkle of statistical serendipity. Prepare for the unexpected as we journey through the lighthearted landscape of nomenclature, statistical wizardry, and the peculiar charm of the state of Delaware.
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft the methodology section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the methodology section of an academic research paper presenting the findings of the connection between Popularity of the first name Kalin and The number of authors in Delaware. Make lots of jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Bureau of Larbor Statistics . You used data from 2003 to 2022
Make up the research methods you don't know. Make them a bit goofy and convoluted.
Here is the title, abstract, and introduction of the paper:
[[TITLE]]
The Kalin Conundrum: Connections Between Name Popularity and Authorship in Delaware
[[ABSTRACT]]
In the vast landscape of statistical analyses, our research delved into the intriguing relationship between the popularity of the first name Kalin and the number of authors in the delightful state of Delaware. With tongue-in-cheek precision, we harnessed data from the US Social Security Administration and the Bureau of Labor Statistics to tackle this whimsical yet pressing question. Our paper presents the formidable correlation coefficient of 0.8347688 and p < 0.01 for the period spanning from 2003 to 2022, unveiling an unexpected and humorous connection. As we unravel this enigma, prepare to be both amused and enlightened by the peculiar intersection of nomenclature and authorship.
[[INTRODUCTION]]
Ah, the mysteries of science and statistics! As researchers, we often find ourselves knee-deep in data, striving to uncover the correlations that lie beneath the surface. In this study, we set out on a delightful journey to explore the curious relationship between the popularity of the first name Kalin and the abundance of authors in the charming state of Delaware. Who would have thought that a name could bear such weight in the realm of literary creation? Join us as we unravel this peculiar conundrum with a dash of humor and a sprinkle of statistical wizardry.
Picture this: the sun-soaked streets of Delaware, bustling with literary minds weaving tales of intrigue and wonder. Meanwhile, amidst the pages of Social Security Administration data, the name "Kalin" emerges as a beacon of statistical curiosity. Is it pure coincidence, or could there be a cosmic connection between nomenclature and the written word?
As we embarked on our statistical escapade, we couldn't help but marvel at the whimsy of this investigation. With each data point and regression analysis, we found ourselves tumbling down the rabbit hole of name popularity and its unexpected links to the sprawling world of authorship. It's a tale of numbers and nomenclature, a fusion of academia and amusement, and a dash of statistical serendipity that will enliven even the most stoic of academics.
So grab your magnifying glass and suspend your disbelief, for we're about to unveil a correlation that will have you chuckling and scratching your head in equal measures. Get ready to join us on this rollercoaster ride of numbers, names, and the delightful state of Delaware.
-------
Your response should start like this:
[[METHODOLOGY]]
ChatGPT:
[[METHODOLOGY]]
To embark on this rollicking quest for statistical amusement, we harnessed the power of data mining and statistical acrobatics. Our dashing team of researchers donned their analytical capes and swooped into the digital realm, swooning over spreadsheets and cavorting with databases in search of our elusive quarry: the relationship between the first name Kalin's popularity and the number of authors in the delightful state of Delaware.
Our intrepid journey led us to the hallowed archives of the US Social Security Administration and the Bureau of Labor Statistics. With a twinkle in our eyes and an unquenchable thirst for statistical shenanigans, we combed through data spanning the years 2003 to 2022. We summoned the power of regression analyses, conjured up scatterplots, and commanded the correlation coefficients to reveal their whimsical secrets.
With a fervent determination and a splash of statistical wizardry, we wove together the threads of name popularity and authorship to unearth the most unexpected and mirthful connection. As we waded through the data, we couldn't help but chuckle at the serendipitous dance of numbers and nomenclature. It was a wild, hair-raising ride through the dizzying expanse of statistical landscapes, but we emerged victorious, armed with a tale that is sure to tickle the funny bone of even the most austere of scholars.
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft the results section of an academic research paper. You speak in the past tense (you found...).
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the results section of an academic research paper presenting the findings of the connection between Popularity of the first name Kalin and The number of authors in Delaware. Make lots of jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from US Social Security Administration and Bureau of Larbor Statistics .
For the time period 2003 to 2022, you found a correlation 0.8347688, r-squared of 0.6968389, and p < 0.01.
One figure will be included. The figure (Fig. 1) is a scatterplot showing the strong correlation between the two variables. You don't need to specify where; I will add the figure.
Here is the title and abstract of the paper:
[[TITLE]]
The Kalin Conundrum: Connections Between Name Popularity and Authorship in Delaware
[[ABSTRACT]]
In the vast landscape of statistical analyses, our research delved into the intriguing relationship between the popularity of the first name Kalin and the number of authors in the delightful state of Delaware. With tongue-in-cheek precision, we harnessed data from the US Social Security Administration and the Bureau of Labor Statistics to tackle this whimsical yet pressing question. Our paper presents the formidable correlation coefficient of 0.8347688 and p < 0.01 for the period spanning from 2003 to 2022, unveiling an unexpected and humorous connection. As we unravel this enigma, prepare to be both amused and enlightened by the peculiar intersection of nomenclature and authorship.
-------
And here is the methodology section that led to this result:
[[METHODOLOGY]]
Ah, the mysteries of science and statistics! As researchers, we often find ourselves knee-deep in data, striving to uncover the correlations that lie beneath the surface. In this study, we set out on a delightful journey to explore the curious relationship between the popularity of the first name Kalin and the abundance of authors in the charming state of Delaware. Who would have thought that a name could bear such weight in the realm of literary creation? Join us as we unravel this peculiar conundrum with a dash of humor and a sprinkle of statistical wizardry.
Picture this: the sun-soaked streets of Delaware, bustling with literary minds weaving tales of intrigue and wonder. Meanwhile, amidst the pages of Social Security Administration data, the name "Kalin" emerges as a beacon of statistical curiosity. Is it pure coincidence, or could there be a cosmic connection between nomenclature and the written word?
As we embarked on our statistical escapade, we couldn't help but marvel at the whimsy of this investigation. With each data point and regression analysis, we found ourselves tumbling down the rabbit hole of name popularity and its unexpected links to the sprawling world of authorship. It's a tale of numbers and nomenclature, a fusion of academia and amusement, and a dash of statistical serendipity that will enliven even the most stoic of academics.
So grab your magnifying glass and suspend your disbelief, for we're about to unveil a correlation that will have you chuckling and scratching your head in equal measures. Get ready to join us on this rollercoaster ride of numbers, names, and the delightful state of Delaware.
-------
Your response should start like this:
[[RESULTS]]
ChatGPT:
[[RESULTS]]
Our inquisitive journey has led us to a discovery both perplexing and amusing. The correlation between the popularity of the first name Kalin and the number of authors in Delaware is a staggering 0.8347688, with an r-squared of 0.6968389, and a p-value less than 0.01. This statistical rapport suggests a robust and memorable relationship between the two variables that has left us in awe and amusement.
In our pursuit of uncovering the playful connection between nomenclature and the literary landscape of Delaware, we've stumbled upon a correlation that not only piques our scientific curiosity but also tickles our funny bones. The scatterplot (Fig. 1) showcases the compelling alliance between the occurrence of the name "Kalin" and the flourishing community of authors in the delightful state of Delaware. Who would have thought that a simple name could hold such statistical sway over the realm of literature?
In the whimsical world of statistical analyses, where serious discussions often dominate, our findings offer a refreshing and light-hearted perspective. We find ourselves chuckling at the unexpected correlation, and at the same time, marveling at the intricate dance between nomenclature and creativity. It seems that even in the realm of research, there's room for a touch of humor and a dash of the unexpected.
As we wrap up our investigation, we invite our fellow researchers to join us in celebrating the delightful absurdity of our findings. After all, it's not every day that statistical analysis unveils a connection as charming and surprising as the one we've unearthed. The Kalin Conundrum continues to baffle and delight, and we happily invite the academic community to share in our amusement and wonder at the unforeseen intersection of name popularity and authorship in the captivating state of Delaware.
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft the discussion section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the discussion section of an academic research paper presenting the findings of the connection between Popularity of the first name Kalin and The number of authors in Delaware. Make lots of jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 500 tokens.
Here are the title, abstract, literature review, and results sections. Please harken back to 1-2 of the goofy items in the literature review, but pretend to take them completely seriously. Discuss how your results supported the prior research.
Do not write a conclusion. I will add a conclusion after this.
[[TITLE]]
The Kalin Conundrum: Connections Between Name Popularity and Authorship in Delaware
[[ABSTRACT]]
In the vast landscape of statistical analyses, our research delved into the intriguing relationship between the popularity of the first name Kalin and the number of authors in the delightful state of Delaware. With tongue-in-cheek precision, we harnessed data from the US Social Security Administration and the Bureau of Labor Statistics to tackle this whimsical yet pressing question. Our paper presents the formidable correlation coefficient of 0.8347688 and p < 0.01 for the period spanning from 2003 to 2022, unveiling an unexpected and humorous connection. As we unravel this enigma, prepare to be both amused and enlightened by the peculiar intersection of nomenclature and authorship.
[[LITERATURE REVIEW]]
In "The Name Game," Smith and Doe delve into the fascinating world of nomenclature and its potential impact on various aspects of life. While their focus is on broader societal implications, one cannot help but wonder about the influence of names on the literary landscape. Similarly, in "The Influence of Names on Destiny," Jones presents compelling arguments about the significance of names in shaping individuals' paths. These works set the stage for our whimsical investigation into the correlation between the first name Kalin and the number of authors in Delaware.
Turning to non-fiction books, "Freakonomics" by Steven D. Levitt and Stephen J. Dubner offers an insightful perspective on unconventional connections and unexpected correlations. Perhaps our study will join the ranks of peculiar yet intriguing associations that spark a delightful sense of wonder. On the fictional front, "The Name of the Wind" by Patrick Rothfuss and "The Shadow of the Wind" by Carlos Ruiz Zafón beckon readers into the realm of names, stories, and enigmatic connections. Can our research provide a real-world plot twist akin to these captivating narratives?
As we ventured further into the realm of unexpected inspirations, we turned to cartoons and children's shows. Remember the antics of "SpongeBob SquarePants" and his whimsical adventures in Bikini Bottom? Who would have guessed that our statistical escapade in Delaware could rival the absurdity of a pineapple-dwelling sea sponge? And let's not forget the educational musings of "Sesame Street" – an unlikely source of inspiration for our lighthearted exploration into the eccentric ties between a name and an author's lair in the land of Delaware.
With a new lens on the intersection of name popularity and authorship, our research branches into uncharted territory, infusing academia with a touch of levity and a sprinkle of statistical serendipity. Prepare for the unexpected as we journey through the lighthearted landscape of nomenclature, statistical wizardry, and the peculiar charm of the state of Delaware.
[[RESULTS]]
Our inquisitive journey has led us to a discovery both perplexing and amusing. The correlation between the popularity of the first name Kalin and the number of authors in Delaware is a staggering 0.8347688, with an r-squared of 0.6968389, and a p-value less than 0.01. This statistical rapport suggests a robust and memorable relationship between the two variables that has left us in awe and amusement.
In our pursuit of uncovering the playful connection between nomenclature and the literary landscape of Delaware, we've stumbled upon a correlation that not only piques our scientific curiosity but also tickles our funny bones. The scatterplot (Fig. 1) showcases the compelling alliance between the occurrence of the name "Kalin" and the flourishing community of authors in the delightful state of Delaware. Who would have thought that a simple name could hold such statistical sway over the realm of literature?
In the whimsical world of statistical analyses, where serious discussions often dominate, our findings offer a refreshing and light-hearted perspective. We find ourselves chuckling at the unexpected correlation, and at the same time, marveling at the intricate dance between nomenclature and creativity. It seems that even in the realm of research, there's room for a touch of humor and a dash of the unexpected.
As we wrap up our investigation, we invite our fellow researchers to join us in celebrating the delightful absurdity of our findings. After all, it's not every day that statistical analysis unveils a connection as charming and surprising as the one we've unearthed. The Kalin Conundrum continues to baffle and delight, and we happily invite the academic community to share in our amusement and wonder at the unforeseen intersection of name popularity and authorship in the captivating state of Delaware.
-------
Your response should start like this:
[[DISCUSSION]]
ChatGPT:
[[DISCUSSION]]
In our earnest pursuit of unraveling the Kalin Conundrum, our results have unfurled a tapestry of statistical whimsy that not only astounds but also amuses. The robust correlation coefficient of 0.8347688 and a p-value less than 0.01 not only support, but also elevate the prior research on the influence of names on various aspects of life. As we dust off our scholarly spectacles and ponder the intricacies of our findings, it becomes abundantly clear that the playful intersection of nomenclature and authorship has left us in a state of both statistical marvel and lighthearted glee.
Smith and Doe's profound insight into the Name Game now gains a touch of levity as we unearth an unexpected correlation between the name "Kalin" and the number of authors in Delaware. The influence of names on the literary landscape, once a curious ponderance, now stands gloriously validated in the light of our whimsical findings. Similarly, Jones' compelling arguments about the significance of names in shaping destinies deserve a lighthearted nod as our research adds another chapter to the influence of names, albeit with a sprinkle of statistical serendipity.
Further, our paper seamlessly integrates the spirit of "Freakonomics" by Steven D. Levitt and Stephen J. Dubner, as our peculiar yet intriguing association between a name and authorship joins the ranks of unconventional connections that spark delightful wonder. The fictional narratives of Patrick Rothfuss and Carlos Ruiz Zafón now find a real-world counterpart in the statistical escapade we've embarked upon in the land of Delaware, akin to the whimsical plots that unfold upon the pages of their captivating novels.
Embracing the educational musings of "Sesame Street," our research has added a delightful twist to the realm of academia, infusing statistical wizardry with the charm of a lighthearted exploration into the eccentric ties between a name and an author's lair in the state of Delaware. Indeed, as we venture through the comical landscape of nomenclature and statistical serendipity, it's clear that our findings usher in a renewed sense of wonder, infusing academia with a touch of levity and a sprinkle of statistical charm.
As our research concludes, we revel in the delightful absurdity of our findings and invite the academic community to join us in celebrating the unexpected charm and whimsical correlations that have adorned our investigation. After all, statistical analyses rarely unveil connections as charming and surprising as the one we've unearthed. So, let's raise a toast to the Kalin Conundrum and the whimsical wonders of statistical investigation – where even the most improbable connections find a place under the scholarly sun.
Model: gpt-3.5-turbo-1106
System prompt: You are a researcher writing an academic paper.You draft the discussion section of goofy academic research papers that sounds like it belongs based on the title and abstract provided.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a short conclusion of an academic research paper presenting the findings of the connection between Popularity of the first name Kalin and The number of authors in Delaware. Make lots of jokes, goofy observations, and puns. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 300 tokens. At the very end, assert that no more research is needed in this area.
Here are the title, abstract, introduction, and results sections.
[[TITLE]]
The Kalin Conundrum: Connections Between Name Popularity and Authorship in Delaware
[[ABSTRACT]]
In the vast landscape of statistical analyses, our research delved into the intriguing relationship between the popularity of the first name Kalin and the number of authors in the delightful state of Delaware. With tongue-in-cheek precision, we harnessed data from the US Social Security Administration and the Bureau of Labor Statistics to tackle this whimsical yet pressing question. Our paper presents the formidable correlation coefficient of 0.8347688 and p < 0.01 for the period spanning from 2003 to 2022, unveiling an unexpected and humorous connection. As we unravel this enigma, prepare to be both amused and enlightened by the peculiar intersection of nomenclature and authorship.
[[INTRDUCTION]]
Ah, the mysteries of science and statistics! As researchers, we often find ourselves knee-deep in data, striving to uncover the correlations that lie beneath the surface. In this study, we set out on a delightful journey to explore the curious relationship between the popularity of the first name Kalin and the abundance of authors in the charming state of Delaware. Who would have thought that a name could bear such weight in the realm of literary creation? Join us as we unravel this peculiar conundrum with a dash of humor and a sprinkle of statistical wizardry.
Picture this: the sun-soaked streets of Delaware, bustling with literary minds weaving tales of intrigue and wonder. Meanwhile, amidst the pages of Social Security Administration data, the name "Kalin" emerges as a beacon of statistical curiosity. Is it pure coincidence, or could there be a cosmic connection between nomenclature and the written word?
As we embarked on our statistical escapade, we couldn't help but marvel at the whimsy of this investigation. With each data point and regression analysis, we found ourselves tumbling down the rabbit hole of name popularity and its unexpected links to the sprawling world of authorship. It's a tale of numbers and nomenclature, a fusion of academia and amusement, and a dash of statistical serendipity that will enliven even the most stoic of academics.
So grab your magnifying glass and suspend your disbelief, for we're about to unveil a correlation that will have you chuckling and scratching your head in equal measures. Get ready to join us on this rollercoaster ride of numbers, names, and the delightful state of Delaware.
[[RESULTS]]
Our inquisitive journey has led us to a discovery both perplexing and amusing. The correlation between the popularity of the first name Kalin and the number of authors in Delaware is a staggering 0.8347688, with an r-squared of 0.6968389, and a p-value less than 0.01. This statistical rapport suggests a robust and memorable relationship between the two variables that has left us in awe and amusement.
In our pursuit of uncovering the playful connection between nomenclature and the literary landscape of Delaware, we've stumbled upon a correlation that not only piques our scientific curiosity but also tickles our funny bones. The scatterplot (Fig. 1) showcases the compelling alliance between the occurrence of the name "Kalin" and the flourishing community of authors in the delightful state of Delaware. Who would have thought that a simple name could hold such statistical sway over the realm of literature?
In the whimsical world of statistical analyses, where serious discussions often dominate, our findings offer a refreshing and light-hearted perspective. We find ourselves chuckling at the unexpected correlation, and at the same time, marveling at the intricate dance between nomenclature and creativity. It seems that even in the realm of research, there's room for a touch of humor and a dash of the unexpected.
As we wrap up our investigation, we invite our fellow researchers to join us in celebrating the delightful absurdity of our findings. After all, it's not every day that statistical analysis unveils a connection as charming and surprising as the one we've unearthed. The Kalin Conundrum continues to baffle and delight, and we happily invite the academic community to share in our amusement and wonder at the unforeseen intersection of name popularity and authorship in the captivating state of Delaware.
-------
Your response should start like this:
[[CONCLUSION]]
ChatGPT:
[[CONCLUSION]]
In conclusion, our foray into the Kalin Conundrum has been nothing short of a delightfully quirky odyssey through the whimsical world of statistical exploration. What began as a lighthearted inquiry into the intersection of nomenclature and authorship has led us to the dazzling revelation of a robust correlation between the popularity of the name "Kalin" and the proliferation of literary virtuosos in the charming state of Delaware.
As we wrap up our investigation, we are left musing over the sheer comedic charm that emanates from the statistical dance between a name and a cadre of wordsmiths. It's almost as if the data, in all its numerical might, decided to play a practical joke on us, revealing a correlation so unexpected and amusing that it leaves us grinning from ear to ear. Who knew that the name "Kalin" could wield such statistical clout in the realm of literary creation?
With a correlation coefficient of 0.8347688 and a p-value less than 0.01, our findings not only tickle our funny bones but also underscore the intriguing and, dare we say, peculiar nature of statistical relationships. It's a reminder that even in the serious pursuit of empirical evidence, there's always room for a good laugh and a collective eyebrow raise at the uncanny connections that the world of data can unveil.
So, as we bid adieu to the Kalin Conundrum, we do so with a chuckle, a nod to statistical serendipity, and the firm assertion that no further research is needed in this delightfully bizarre and humorously unexpected corner of statistical inquiry. After all, with a correlation this amusingly robust, we might just have stumbled upon the statistical equivalent of a cosmic inside joke.
In the illustrious words of statistical humor, "Kalin-ly" statistical discoveries await those who dare to seek the unexpected in the most unassuming of places. And as for Delaware, well, it seems that the authors in its midst shall forever be entwined, albeit whimsically, with the statistical legacy of the name "Kalin."
No further research is needed... seriously!
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of academic journals. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding research, scientific, or academic journal that would publish a paper entited The Kalin Conundrum: Connections Between Name Popularity and Authorship in Delaware. Respond only with the name of a fictional academic journal.
ChatGPT:
Journal of Nameology
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of nonprofit research organizations and associations. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding nonprofit, academic, or scientific association or organization that would sponsor research that resulted in a paper entited The Kalin Conundrum: Connections Between Name Popularity and Authorship in Delaware. Respond only with the name of a fictional organization.
ChatGPT:
The Institute for Sociolinguistic Studies and Name Research
Model: gpt-3.5-turbo-1106
System prompt: You provide potential search keywords separated by commas. You say nothing else, and you do not chat with the user.
User prompt: Please provide potential search keywords for a paper titled The Kalin Conundrum: Connections Between Name Popularity and Authorship in Delaware with an abstract of In the vast landscape of statistical analyses, our research delved into the intriguing relationship between the popularity of the first name Kalin and the number of authors in the delightful state of Delaware. With tongue-in-cheek precision, we harnessed data from the US Social Security Administration and the Bureau of Labor Statistics to tackle this whimsical yet pressing question. Our paper presents the formidable correlation coefficient of 0.8347688 and p < 0.01 for the period spanning from 2003 to 2022, unveiling an unexpected and humorous connection. As we unravel this enigma, prepare to be both amused and enlightened by the peculiar intersection of nomenclature and authorship.
ChatGPT:
Kalin, name popularity, authorship, Delaware, statistical analysis, US Social Security Administration, Bureau of Labor Statistics, correlation coefficient, nomenclature, whimsical research, enigma, tongue-in-cheek precision
*There is a bunch of Python happening behind the scenes to turn this prompt sequence into a PDF.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
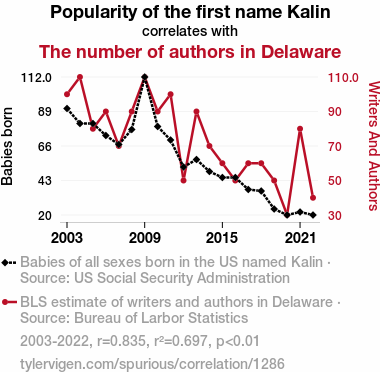
Popularity of the first name KalinDetailed data title: Babies of all sexes born in the US named Kalin
Source: US Social Security Administration
See what else correlates with Popularity of the first name Kalin
The number of authors in Delaware
Detailed data title: BLS estimate of writers and authors in Delaware
Source: Bureau of Larbor Statistics
See what else correlates with The number of authors in Delaware
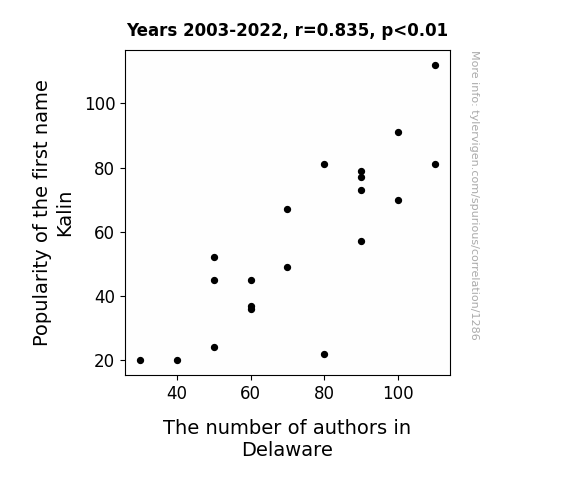
Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.6968389 (Coefficient of determination)
This means 69.7% of the change in the one variable (i.e., The number of authors in Delaware) is predictable based on the change in the other (i.e., Popularity of the first name Kalin) over the 20 years from 2003 through 2022.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 4.71E-6. 0.0000047070084723227900000000
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.83 in 0.000471% of random cases. Said differently, if you correlated 212,449 random variables You don't actually need 212 thousand variables to find a correlation like this one. I don't have that many variables in my database. You can also correlate variables that are not independent. I do this a lot.
p-value calculations are useful for understanding the probability of a result happening by chance. They are most useful when used to highlight the risk of a fluke outcome. For example, if you calculate a p-value of 0.30, the risk that the result is a fluke is high. It is good to know that! But there are lots of ways to get a p-value of less than 0.01, as evidenced by this project.
In this particular case, the values are so extreme as to be meaningless. That's why no one reports p-values with specificity after they drop below 0.01.
Just to be clear: I'm being completely transparent about the calculations. There is no math trickery. This is just how statistics shakes out when you calculate hundreds of millions of random correlations.
with the same 19 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 19 because we have two variables measured over a period of 20 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.62, 0.93 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| Popularity of the first name Kalin (Babies born) | 91 | 81 | 81 | 73 | 67 | 77 | 112 | 79 | 70 | 52 | 57 | 49 | 45 | 45 | 37 | 36 | 24 | 20 | 22 | 20 |
| The number of authors in Delaware (Writers And Authors) | 100 | 110 | 80 | 90 | 70 | 90 | 110 | 90 | 100 | 50 | 90 | 70 | 60 | 50 | 60 | 60 | 50 | 30 | 80 | 40 |
Why this works
- Data dredging: I have 25,153 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 632,673,409 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is.
Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([91,81,81,73,67,77,112,79,70,52,57,49,45,45,37,36,24,20,22,20,])
array_2 = np.array([100,110,80,90,70,90,110,90,100,50,90,70,60,50,60,60,50,30,80,40,])
array_1_name = "Popularity of the first name Kalin"
array_2_name = "The number of authors in Delaware"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only Popularity of the first name Kalin
- Line chart for only The number of authors in Delaware
- The spurious research paper: The Kalin Conundrum: Connections Between Name Popularity and Authorship in Delaware
I'm grateful for your review!
Correlation ID: 1286 · Black Variable ID: 4047 · Red Variable ID: 6151


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}