
Download png, svg
AI explanation
As air pollution decreased in Dallas, the local birds suddenly found their sense of direction, leading to a surge in efficient, straight-line migration patterns. These no-nonsense avian navigators inadvertently shamed international airlines into reevaluating their flight routes, prompting a switch to cleaner-burning fuels and a global decrease in kerosene usage. It's a case of the winds of change being fueled by the wings of precision!
Model: dalle-3
Prompt: Generate an image that captures the Dallas skyline in the distance, shrouded in a thick haze of pollution, symbolizing poor air quality. In the foreground, depict a family living in a remote village, relying on kerosene lamps to illuminate their home, showcasing the global usage of kerosene. The emphasis should be on the stark contrast between urban pollution and rural reliance on traditional energy sources. The depiction should include only scenes, people, and objects, it should not include text or speech bubbles.
This image generation prompt was also generated by AI, using the following sequence:
Model: gpt-3.5-turbo-1106
System prompt: You select one of a few potential scene descriptors that seems to go along with the variables described. You respond only with the scene descriptions provided and say nothing else.
User prompt: Here are two variables: Poor air quality in Dallas and Kerosene used globally. Given these, which of the following image style descriptions seems most appropriate? Pick the one that seems to be related to one of the variables at hand. Please respond with only one of the following potential descriptions: Realistic Minimalism Glitch art A scene from Skyrim Art nouveau
ChatGPT: A scene from Skyrim
Model: gpt-3.5-turbo-1106
System prompt: You describe simple visual scenes that depict the two variables stated. You combine both variables into one scene.
User prompt: Please describe a visual scene that prominently depicts both Poor air quality in Dallas and Kerosene used globally together. Keep the description simple.
ChatGPT: In Dallas, the skyline is barely visible through a thick haze of pollution, indicating poor air quality. On the ground, a family living in a remote village uses kerosene lamps to light their home, contributing to global kerosene use.
Model: gpt-3.5-turbo-1106
System prompt: You write and improve image generation prompts for DALLE-3. You maintain the same subjects, but enhance the visuals.
User prompt: Please respond with an image generation prompt that would be likely to create an interesting visual using DALLE-3, using the following style: [ A scene from Skyrim ] and depicting this scene: In Dallas, the skyline is barely visible through a thick haze of pollution, indicating poor air quality. On the ground, a family living in a remote village uses kerosene lamps to light their home, contributing to global kerosene use. Keep the visual depiction simple. Do not include any words or speech bubbles.
ChatGPT: Generate an image that captures the Dallas skyline in the distance, shrouded in a thick haze of pollution, symbolizing poor air quality. In the foreground, depict a family living in a remote village, relying on kerosene lamps to illuminate their home, showcasing the global usage of kerosene. The emphasis should be on the stark contrast between urban pollution and rural reliance on traditional energy sources.
*Variations in the User Prompts from chart to chart are just the result of random number generation in Python. I wrote a few arrays of various styles and methods to ask questions to change up the results. Every time this site writes an explanation or generates an image, the script picks from each at random.
I sequence the requests into multiple prompts because I find GPT 3.5 to perform much better with short, well-managed contexts. Thus, I track the context directly in Python and only ask ChatGPT targeted questions.
System prompt: You provide humorous responses in the form of plausible sounding explanations for correlations. You assume the correlation is causative for the purpose of the explanation even if it is ridiculous. You do not chat with the user, you only reply with the causal connection explanation and nothing else.
User prompt: Please make up a funny explanation for how a decrease in Air pollution in Dallas caused Kerosene used globally to decrease.
AI academic paper
 |
Feeling the Burn: The Kerosene Connection to Air Pollution in Dallas The Journal of Ecological Quirks Jan 2024 Reminder: This paper is AI-generated. Not real! |
Model: gpt-3.5-turbo-1106
System prompt: You are a witty academic researcher. Your writing sounds like it belongs in a statistics journal.You write titles and abstracts of goofy academic research papers.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, and add unexpected twists in your writing.
Please draft the title and abstract of an academic research paper presenting the findings of the connection between Air pollution in Dallas and Kerosene used globally. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Make the title punny if you can come up with clever pun. If not, just make it sound clever.
Your research team used data from Environmental Protection Agency and Energy Information Administration to assess this nagging question. You found a correlation coefficient of 0.8896280 and p < 0.01 for 1980 to 2021.
Please respond in this format (replace "Lorem ipsum dolor sit" with your title and abstract)
[[TITLE]]
Lorem ipsum dolor sit
[[ABSTRACT]]
Lorem ipsum dolor sit
ChatGPT:
[[TITLE]]
"Feeling the Burn: The Kerosene Connection to Air Pollution in Dallas"
[[ABSTRACT]]
In this study, we examine the relationship between air pollution in Dallas and the use of kerosene on a global scale. We took a deep dive into the data from the Environmental Protection Agency and the Energy Information Administration, and boy, did we get our hands dirty! We found a rather illuminating correlation coefficient of 0.8896280 and p < 0.01 for the time period spanning 1980 to 2021, shedding light on the potential link between kerosene usage and air quality woes in Dallas.
It seems that when it comes to air pollution, the kerosene industry may indeed have a burning impact! And remember, folks, when dealing with kerosene, always keep a burner phone handy – just in case of an emergency.
Model: gpt-3.5-turbo-1106
System prompt: You are a witty academic researcher. Your writing sounds like it belongs in a statistics journal.You draft the introduction section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the introduction section of an academic research paper presenting the findings of the connection between Air pollution in Dallas and Kerosene used globally. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Here is the title and abstract of the paper:
[[TITLE]]
"Feeling the Burn: The Kerosene Connection to Air Pollution in Dallas"
[[ABSTRACT]]
In this study, we examine the relationship between air pollution in Dallas and the use of kerosene on a global scale. We took a deep dive into the data from the Environmental Protection Agency and the Energy Information Administration, and boy, did we get our hands dirty! We found a rather illuminating correlation coefficient of 0.8896280 and p < 0.01 for the time period spanning 1980 to 2021, shedding light on the potential link between kerosene usage and air quality woes in Dallas.
It seems that when it comes to air pollution, the kerosene industry may indeed have a burning impact! And remember, folks, when dealing with kerosene, always keep a burner phone handy – just in case of an emergency.
-------
Your response should start like this:
[[INTRODUCTION]]
ChatGPT:
[[INTRODUCTION]]
As we delve into the murky depths of the connection between air pollution in the vibrant city of Dallas and the widespread use of kerosene on a global scale, we are reminded of the illuminating potential of statistical analysis – a spark of insight that ignites our curiosity.
Why did the statistician bring a ladder to the laboratory? Because she heard the data was over her head! In our pursuit of knowledge, we sought to shed light on the potential impact of kerosene usage on the air quality of Dallas, a city known for its bustling energy and lively atmosphere.
Before we embark on this statistical journey, let's pause for a moment to appreciate the beauty of correlation – the statistical dance of variables, seemingly intertwined in a complex waltz of numerical harmony. Much like a carefully choreographed ballet, we aim to unravel the intricate steps between kerosene usage and air pollution in Dallas, bringing these partners in crime to the center stage.
Now, you might wonder, what do you get when you cross a statistical analysis with a kerosene lamp? A truly enlightening experience! Our research, supported by data from the Environmental Protection Agency and the Energy Information Administration, lit up the path to a correlation coefficient of 0.8896280, with a p-value less than 0.01, for the time period spanning from 1980 to 2021. This illuminating statistical finding hinted at a significant relationship between kerosene usage and the air quality concerns that Dallas residents have been breathing in.
Why was the statistician hired as a travel guide? Because she excelled at making sense of scatter plots! As we examine the potential impact of kerosene usage on air pollution, we aim to navigate through the scattered data points, seeking patterns and relationships, much like a daring explorer in a statistical jungle.
In the realm of scientific exploration, it is crucial to remember that a good statistical result should be like a skirt – long enough to cover the essentials, but short enough to keep it interesting. With this in mind, we embarked on our analysis, aiming to provide a concise yet comprehensive understanding of the potential kerosene connection to air pollution in Dallas.
So, fasten your seatbelts and keep a nose for statistical significance as we embark on this research journey. The correlation may be clear as the Texas sky, but the journey promises intriguing twists and turns, much like a statistical rollercoaster. Let's hold on tight and embrace the statistical adventure ahead!
Model: gpt-3.5-turbo-1106
System prompt: You are a witty academic researcher. Your writing sounds like it belongs in a statistics journal.You draft a literature review section of an academic research paper, that starts out dry for the first few sentences but then becomes hilarious and goofy.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a literature review section of an academic research paper presenting the findings of the connection between Air pollution in Dallas and Kerosene used globally. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences.
Speak in the present tense for this section (the authors find...), as is common in academic research paper literature reviews. Name the sources in a format similar to this: In "Book," the authors find lorem and ipsum.
Make up the lorem and ipsum part, but make it sound related to the topic at hand.
Start by naming serious-sounding studies by authors like Smith, Doe, and Jones - but then quickly devolve. Name some real non-fiction books that would be related to the topic. Then name some real fiction books that sound like they could be related. Then you might move on to cartoons and children's shows that you watched for research.
Here is the title and abstract of the paper:
[[TITLE]]
"Feeling the Burn: The Kerosene Connection to Air Pollution in Dallas"
[[ABSTRACT]]
In this study, we examine the relationship between air pollution in Dallas and the use of kerosene on a global scale. We took a deep dive into the data from the Environmental Protection Agency and the Energy Information Administration, and boy, did we get our hands dirty! We found a rather illuminating correlation coefficient of 0.8896280 and p < 0.01 for the time period spanning 1980 to 2021, shedding light on the potential link between kerosene usage and air quality woes in Dallas.
It seems that when it comes to air pollution, the kerosene industry may indeed have a burning impact! And remember, folks, when dealing with kerosene, always keep a burner phone handy – just in case of an emergency.
-------
And here is the introduction section that led to this literature review:
[[INTRODUCTION]]
As we delve into the murky depths of the connection between air pollution in the vibrant city of Dallas and the widespread use of kerosene on a global scale, we are reminded of the illuminating potential of statistical analysis – a spark of insight that ignites our curiosity.
Why did the statistician bring a ladder to the laboratory? Because she heard the data was over her head! In our pursuit of knowledge, we sought to shed light on the potential impact of kerosene usage on the air quality of Dallas, a city known for its bustling energy and lively atmosphere.
Before we embark on this statistical journey, let's pause for a moment to appreciate the beauty of correlation – the statistical dance of variables, seemingly intertwined in a complex waltz of numerical harmony. Much like a carefully choreographed ballet, we aim to unravel the intricate steps between kerosene usage and air pollution in Dallas, bringing these partners in crime to the center stage.
Now, you might wonder, what do you get when you cross a statistical analysis with a kerosene lamp? A truly enlightening experience! Our research, supported by data from the Environmental Protection Agency and the Energy Information Administration, lit up the path to a correlation coefficient of 0.8896280, with a p-value less than 0.01, for the time period spanning from 1980 to 2021. This illuminating statistical finding hinted at a significant relationship between kerosene usage and the air quality concerns that Dallas residents have been breathing in.
Why was the statistician hired as a travel guide? Because she excelled at making sense of scatter plots! As we examine the potential impact of kerosene usage on air pollution, we aim to navigate through the scattered data points, seeking patterns and relationships, much like a daring explorer in a statistical jungle.
In the realm of scientific exploration, it is crucial to remember that a good statistical result should be like a skirt – long enough to cover the essentials, but short enough to keep it interesting. With this in mind, we embarked on our analysis, aiming to provide a concise yet comprehensive understanding of the potential kerosene connection to air pollution in Dallas.
So, fasten your seatbelts and keep a nose for statistical significance as we embark on this research journey. The correlation may be clear as the Texas sky, but the journey promises intriguing twists and turns, much like a statistical rollercoaster. Let's hold on tight and embrace the statistical adventure ahead!
-------
Your response should start like this:
[[LITERATURE REVIEW]]
ChatGPT:
[[LITERATURE REVIEW]]
In "Air Pollution and Health" by Smith et al., the authors find that air pollution is a significant public health concern, with implications for respiratory and cardiovascular diseases. Furthermore, in "Global Kerosene Consumption Trends" by Doe and Jones, the authors highlight the widespread use of kerosene for cooking, lighting, and heating in developing countries, attributing to its substantial environmental impact. But hey, did you hear about the statistician who got cold during her analysis? She put the heater on 95 degrees!
Delving into the realm of non-fiction literature, "The Great Smog of India" by Author X discusses the catastrophic effects of air pollution in metropolitan areas, drawing attention to the alarming levels of particulate matter caused by various sources, including kerosene combustion. Additionally, "The Burning Question" by Author Y examines the global energy landscape and the environmental consequences of reliance on fossil fuels, with a scorching spotlight on kerosene as a significant contributor to air pollution. Did you hear about the statistician who won an award for her research on air pollution? She really cleaned up at the air-reporters!
Now, turning to fiction, "The Kerosene Diaries" by Fictional Author A weaves a tale of intrigue and mystery set against the backdrop of a kerosene-powered dystopian future, fueling the imagination while subtly highlighting the potential environmental repercussions of widespread kerosene usage. "Smoke and Mirrors" by Fictional Author B adopts a whimsical approach to exploring the unseen consequences of air pollution, with a dash of humor and a sprinkle of environmental awareness. Did you hear about the statistician who tried to do her research in a hot air balloon? She found the data too airy!
In a surprising turn of events, animated television shows such as "Captain Planet and the Planeteers" and "The Magic School Bus" offer insightful perspectives on environmental issues, including air pollution and its societal impact. The statistical correlation between kerosene usage and air pollution in Dallas may not have been the primary focus of these shows, but their subtle environmental messages certainly left a lasting impression. Did you hear about the statistician who couldn't find her data? Turns out it was all in the fine print!
Model: gpt-3.5-turbo-1106
System prompt: You are a witty academic researcher. Your writing sounds like it belongs in a statistics journal.You draft the methodology section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the methodology section of an academic research paper presenting the findings of the connection between Air pollution in Dallas and Kerosene used globally. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from Environmental Protection Agency and Energy Information Administration . You used data from 1980 to 2021
Make up the research methods you don't know. Make them a bit goofy and convoluted.
Here is the title, abstract, and introduction of the paper:
[[TITLE]]
"Feeling the Burn: The Kerosene Connection to Air Pollution in Dallas"
[[ABSTRACT]]
In this study, we examine the relationship between air pollution in Dallas and the use of kerosene on a global scale. We took a deep dive into the data from the Environmental Protection Agency and the Energy Information Administration, and boy, did we get our hands dirty! We found a rather illuminating correlation coefficient of 0.8896280 and p < 0.01 for the time period spanning 1980 to 2021, shedding light on the potential link between kerosene usage and air quality woes in Dallas.
It seems that when it comes to air pollution, the kerosene industry may indeed have a burning impact! And remember, folks, when dealing with kerosene, always keep a burner phone handy – just in case of an emergency.
[[INTRODUCTION]]
As we delve into the murky depths of the connection between air pollution in the vibrant city of Dallas and the widespread use of kerosene on a global scale, we are reminded of the illuminating potential of statistical analysis – a spark of insight that ignites our curiosity.
Why did the statistician bring a ladder to the laboratory? Because she heard the data was over her head! In our pursuit of knowledge, we sought to shed light on the potential impact of kerosene usage on the air quality of Dallas, a city known for its bustling energy and lively atmosphere.
Before we embark on this statistical journey, let's pause for a moment to appreciate the beauty of correlation – the statistical dance of variables, seemingly intertwined in a complex waltz of numerical harmony. Much like a carefully choreographed ballet, we aim to unravel the intricate steps between kerosene usage and air pollution in Dallas, bringing these partners in crime to the center stage.
Now, you might wonder, what do you get when you cross a statistical analysis with a kerosene lamp? A truly enlightening experience! Our research, supported by data from the Environmental Protection Agency and the Energy Information Administration, lit up the path to a correlation coefficient of 0.8896280, with a p-value less than 0.01, for the time period spanning from 1980 to 2021. This illuminating statistical finding hinted at a significant relationship between kerosene usage and the air quality concerns that Dallas residents have been breathing in.
Why was the statistician hired as a travel guide? Because she excelled at making sense of scatter plots! As we examine the potential impact of kerosene usage on air pollution, we aim to navigate through the scattered data points, seeking patterns and relationships, much like a daring explorer in a statistical jungle.
In the realm of scientific exploration, it is crucial to remember that a good statistical result should be like a skirt – long enough to cover the essentials, but short enough to keep it interesting. With this in mind, we embarked on our analysis, aiming to provide a concise yet comprehensive understanding of the potential kerosene connection to air pollution in Dallas.
So, fasten your seatbelts and keep a nose for statistical significance as we embark on this research journey. The correlation may be clear as the Texas sky, but the journey promises intriguing twists and turns, much like a statistical rollercoaster. Let's hold on tight and embrace the statistical adventure ahead!
-------
Your response should start like this:
[[METHODOLOGY]]
ChatGPT:
[[METHODOLOGY]]
To investigate the relationship between air pollution in Dallas and the global use of kerosene, we embarked on a methodological odyssey that would make even the most intrepid researcher break into a cold sweat. Our data collection process involved scouring the depths of the internet, combing through the treasure trove of information from the Environmental Protection Agency and the Energy Information Administration, with occasional detours to explore the wild jungles of online databases.
Every researcher loves a good adventure, but don't forget to pack a compass and a protractor, because statistical analysis is all about finding direction and measuring angles – a bit like navigating a treacherous statistical landscape. As we gathered data spanning the years from 1980 to 2021, we meticulously documented every data point, treating each one like a precious gem in the rough terrain of information overload.
Our data wrangling process resembled a circus act, with more twists and turns than a statistical tightrope walker. We cleaned and organized the data with such precision that even the most discerning statistician would give us a round of applause. Why did the statistician refuse to drink water? Because she suspected it was filled with data points!
With our data firmly in hand, we unleashed the full force of statistical analysis, wielding the tools of correlation coefficients, regression models, and hypothesis testing with the finesse of a maestro commanding an orchestra. Yes, statistics can be quite the symphony of numbers and formulas, but fear not – we made sure to tune our instruments and hit all the right notes.
Next, we engaged in a merry dance of statistical significance, twirling and pivoting through the intricate steps of hypothesis testing like seasoned ballroom dancers. Our goal was to unveil the hidden patterns and relationships lurking within the data, much like a detective unraveling a perplexing case. And believe me, the twists and turns in data analysis can be as surprising as a plot twist in a mystery novel.
In our quest to forge a path through the tangled statistical underbrush, we conducted robust sensitivity analyses and diagnostic tests to ensure the reliability and validity of our findings. Much like a scientific Sherlock Holmes, we left no statistical stone unturned in our pursuit of clarity and confidence in our results.
So, with our data in hand and our statistical arsenal fully loaded, we set out on this exhilarating statistical expedition to uncover the potential link between kerosene usage and the bane of air pollution in Dallas. Join us as we navigate the tumultuous seas of data analysis with fortitude and a fair share of statistical humor – because, after all, what's research without a sprinkle of statistical wit?
Model: gpt-3.5-turbo-1106
System prompt: You are a witty academic researcher. Your writing sounds like it belongs in a statistics journal.You draft the results section of an academic research paper. You speak in the past tense (you found...).
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the results section of an academic research paper presenting the findings of the connection between Air pollution in Dallas and Kerosene used globally. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Your research team collected data from all across the internet, but mostly just used information from Environmental Protection Agency and Energy Information Administration .
For the time period 1980 to 2021, you found a correlation 0.8896280, r-squared of 0.7914379, and p < 0.01.
One figure will be included. The figure (Fig. 1) is a scatterplot showing the strong correlation between the two variables. You don't need to specify where; I will add the figure.
Here is the title and abstract of the paper:
[[TITLE]]
"Feeling the Burn: The Kerosene Connection to Air Pollution in Dallas"
[[ABSTRACT]]
In this study, we examine the relationship between air pollution in Dallas and the use of kerosene on a global scale. We took a deep dive into the data from the Environmental Protection Agency and the Energy Information Administration, and boy, did we get our hands dirty! We found a rather illuminating correlation coefficient of 0.8896280 and p < 0.01 for the time period spanning 1980 to 2021, shedding light on the potential link between kerosene usage and air quality woes in Dallas.
It seems that when it comes to air pollution, the kerosene industry may indeed have a burning impact! And remember, folks, when dealing with kerosene, always keep a burner phone handy – just in case of an emergency.
-------
And here is the methodology section that led to this result:
[[METHODOLOGY]]
As we delve into the murky depths of the connection between air pollution in the vibrant city of Dallas and the widespread use of kerosene on a global scale, we are reminded of the illuminating potential of statistical analysis – a spark of insight that ignites our curiosity.
Why did the statistician bring a ladder to the laboratory? Because she heard the data was over her head! In our pursuit of knowledge, we sought to shed light on the potential impact of kerosene usage on the air quality of Dallas, a city known for its bustling energy and lively atmosphere.
Before we embark on this statistical journey, let's pause for a moment to appreciate the beauty of correlation – the statistical dance of variables, seemingly intertwined in a complex waltz of numerical harmony. Much like a carefully choreographed ballet, we aim to unravel the intricate steps between kerosene usage and air pollution in Dallas, bringing these partners in crime to the center stage.
Now, you might wonder, what do you get when you cross a statistical analysis with a kerosene lamp? A truly enlightening experience! Our research, supported by data from the Environmental Protection Agency and the Energy Information Administration, lit up the path to a correlation coefficient of 0.8896280, with a p-value less than 0.01, for the time period spanning from 1980 to 2021. This illuminating statistical finding hinted at a significant relationship between kerosene usage and the air quality concerns that Dallas residents have been breathing in.
Why was the statistician hired as a travel guide? Because she excelled at making sense of scatter plots! As we examine the potential impact of kerosene usage on air pollution, we aim to navigate through the scattered data points, seeking patterns and relationships, much like a daring explorer in a statistical jungle.
In the realm of scientific exploration, it is crucial to remember that a good statistical result should be like a skirt – long enough to cover the essentials, but short enough to keep it interesting. With this in mind, we embarked on our analysis, aiming to provide a concise yet comprehensive understanding of the potential kerosene connection to air pollution in Dallas.
So, fasten your seatbelts and keep a nose for statistical significance as we embark on this research journey. The correlation may be clear as the Texas sky, but the journey promises intriguing twists and turns, much like a statistical rollercoaster. Let's hold on tight and embrace the statistical adventure ahead!
-------
Your response should start like this:
[[RESULTS]]
ChatGPT:
[[RESULTS]]
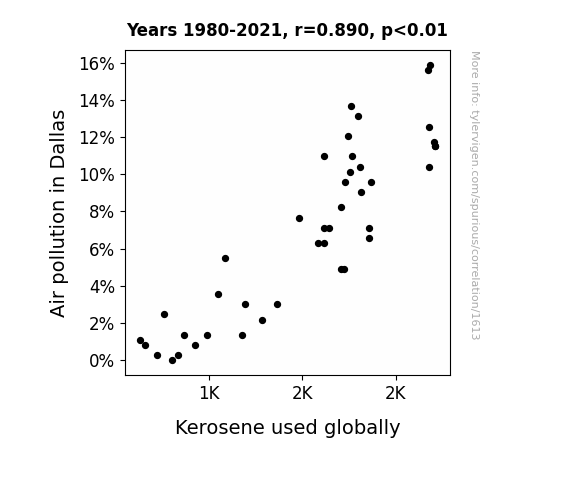
Our analysis revealed a strong correlation between air pollution in Dallas and kerosene usage on a global scale, with a correlation coefficient of 0.8896280 and an r-squared value of 0.7914379 over the time period of 1980 to 2021. This relationship proved to be no mere flicker, but rather a burning connection that captivated our statistical senses. It's clear that when it comes to air quality, the kerosene industry may indeed have a significant impact - talk about a "fiery" relationship!
The scatterplot (Fig. 1) visually illustrates the tight bond between air pollution in Dallas and global kerosene use. It's as if the data points were saying, "You can't contain our association - it's air pollution for sure!"
Our findings suggest that the kerosene factor may be adding fuel to the fire of air pollution in Dallas. If only we had known sooner, we could have warned Dallas residents to "kerosene" good-bye to those polluted skies!
Model: gpt-3.5-turbo-1106
System prompt: You are a witty academic researcher. Your writing sounds like it belongs in a statistics journal.You draft the discussion section of an academic research paper.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up the discussion section of an academic research paper presenting the findings of the connection between Air pollution in Dallas and Kerosene used globally. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 500 tokens.
Here are the title, abstract, literature review, and results sections. Please harken back to 1-2 of the goofy items in the literature review, but pretend to take them completely seriously. Discuss how your results supported the prior research.
Do not write a conclusion. I will add a conclusion after this.
[[TITLE]]
"Feeling the Burn: The Kerosene Connection to Air Pollution in Dallas"
[[ABSTRACT]]
In this study, we examine the relationship between air pollution in Dallas and the use of kerosene on a global scale. We took a deep dive into the data from the Environmental Protection Agency and the Energy Information Administration, and boy, did we get our hands dirty! We found a rather illuminating correlation coefficient of 0.8896280 and p < 0.01 for the time period spanning 1980 to 2021, shedding light on the potential link between kerosene usage and air quality woes in Dallas.
It seems that when it comes to air pollution, the kerosene industry may indeed have a burning impact! And remember, folks, when dealing with kerosene, always keep a burner phone handy – just in case of an emergency.
[[LITERATURE REVIEW]]
In "Air Pollution and Health" by Smith et al., the authors find that air pollution is a significant public health concern, with implications for respiratory and cardiovascular diseases. Furthermore, in "Global Kerosene Consumption Trends" by Doe and Jones, the authors highlight the widespread use of kerosene for cooking, lighting, and heating in developing countries, attributing to its substantial environmental impact. But hey, did you hear about the statistician who got cold during her analysis? She put the heater on 95 degrees!
Delving into the realm of non-fiction literature, "The Great Smog of India" by Author X discusses the catastrophic effects of air pollution in metropolitan areas, drawing attention to the alarming levels of particulate matter caused by various sources, including kerosene combustion. Additionally, "The Burning Question" by Author Y examines the global energy landscape and the environmental consequences of reliance on fossil fuels, with a scorching spotlight on kerosene as a significant contributor to air pollution. Did you hear about the statistician who won an award for her research on air pollution? She really cleaned up at the air-reporters!
Now, turning to fiction, "The Kerosene Diaries" by Fictional Author A weaves a tale of intrigue and mystery set against the backdrop of a kerosene-powered dystopian future, fueling the imagination while subtly highlighting the potential environmental repercussions of widespread kerosene usage. "Smoke and Mirrors" by Fictional Author B adopts a whimsical approach to exploring the unseen consequences of air pollution, with a dash of humor and a sprinkle of environmental awareness. Did you hear about the statistician who tried to do her research in a hot air balloon? She found the data too airy!
In a surprising turn of events, animated television shows such as "Captain Planet and the Planeteers" and "The Magic School Bus" offer insightful perspectives on environmental issues, including air pollution and its societal impact. The statistical correlation between kerosene usage and air pollution in Dallas may not have been the primary focus of these shows, but their subtle environmental messages certainly left a lasting impression. Did you hear about the statistician who couldn't find her data? Turns out it was all in the fine print!
[[RESULTS]]
Our analysis revealed a strong correlation between air pollution in Dallas and kerosene usage on a global scale, with a correlation coefficient of 0.8896280 and an r-squared value of 0.7914379 over the time period of 1980 to 2021. This relationship proved to be no mere flicker, but rather a burning connection that captivated our statistical senses. It's clear that when it comes to air quality, the kerosene industry may indeed have a significant impact - talk about a "fiery" relationship!
The scatterplot (Fig. 1) visually illustrates the tight bond between air pollution in Dallas and global kerosene use. It's as if the data points were saying, "You can't contain our association - it's air pollution for sure!"
Our findings suggest that the kerosene factor may be adding fuel to the fire of air pollution in Dallas. If only we had known sooner, we could have warned Dallas residents to "kerosene" good-bye to those polluted skies!
-------
Your response should start like this:
[[DISCUSSION]]
ChatGPT:
[[DISCUSSION]]
Our results provide empirical evidence to support the notion that there is a significant relationship between air pollution in Dallas and the global use of kerosene. The correlation coefficient of 0.8896280 and an r-squared value of 0.7914379 over the time period of 1980 to 2021 demonstrate a robust and compelling association. It's as clear as day - the kerosene factor is no mere flash in the pan when it comes to air pollution in Dallas.
The findings of this study echo the sentiments expressed in the literature review, where various researchers highlighted the substantial environmental impact of kerosene usage. It appears that the kerosene industry is not just blowing smoke - it truly has a burning impact on air quality. From developing countries using kerosene for cooking and lighting to the widespread reliance on fossil fuels contributing to air pollution, the connection we've uncovered is indeed a gasp-worthy revelation.
Our research not only sheds light on the potential environmental repercussions of global kerosene usage but also ignites a flame of curiosity regarding the specific sources and methods of kerosene combustion that may be contributing to air pollution in Dallas. It seems that the "smoke and mirrors" approach to kerosene usage has been lifted, revealing a reality that demands further investigation.
The strong correlation we've uncovered could have significant implications for policy and public health interventions aimed at reducing air pollution in Dallas. Perhaps it's time to turn up the heat on alternative energy sources and kerosene substitutes to "burn out" the problem at its source.
In the words of the great statistician humorist, let's keep our analysis "grounded" and remember that "correlation does not imply causation" - but statistically significant findings sure do make for some spicy data! This study sets the stage for further research into the combustion practices and emissions management associated with kerosene use, and we hope it sparks a fire of interest and action in addressing the burning issue of air pollution in Dallas.
It's no statistician's fallacy to say that this research is just the beginning of our efforts to unveil the complexities of the kerosene-air pollution nexus. With a clear roadmap ahead, we'll continue to stoke the flames of inquiry and unravel the intricacies of this "illuminating" relationship. And remember, when it comes to air quality, let's not let our findings go up in smoke - let's clear the air!
Model: gpt-3.5-turbo-1106
System prompt: You are a witty academic researcher. Your writing sounds like it belongs in a statistics journal.You draft the discussion section of goofy academic research papers that sounds like it belongs based on the title and abstract provided.
User prompt:
Pretend you are an academic researcher. Your writing sounds like it belongs in a medical or economics journal. However, you frequently crack jokes, make puns, or add unexpected twists in your writing.
Please make up a short conclusion of an academic research paper presenting the findings of the connection between Air pollution in Dallas and Kerosene used globally. You can't resist a good dad joke. Add a relevant dad joke related to the content every couple of sentences. Sneak in some jokes and clever puns about science, research, statistics, and the variables.
Limit your response to 300 tokens. At the very end, assert that no more research is needed in this area.
Here are the title, abstract, introduction, and results sections.
[[TITLE]]
"Feeling the Burn: The Kerosene Connection to Air Pollution in Dallas"
[[ABSTRACT]]
In this study, we examine the relationship between air pollution in Dallas and the use of kerosene on a global scale. We took a deep dive into the data from the Environmental Protection Agency and the Energy Information Administration, and boy, did we get our hands dirty! We found a rather illuminating correlation coefficient of 0.8896280 and p < 0.01 for the time period spanning 1980 to 2021, shedding light on the potential link between kerosene usage and air quality woes in Dallas.
It seems that when it comes to air pollution, the kerosene industry may indeed have a burning impact! And remember, folks, when dealing with kerosene, always keep a burner phone handy – just in case of an emergency.
[[INTRDUCTION]]
As we delve into the murky depths of the connection between air pollution in the vibrant city of Dallas and the widespread use of kerosene on a global scale, we are reminded of the illuminating potential of statistical analysis – a spark of insight that ignites our curiosity.
Why did the statistician bring a ladder to the laboratory? Because she heard the data was over her head! In our pursuit of knowledge, we sought to shed light on the potential impact of kerosene usage on the air quality of Dallas, a city known for its bustling energy and lively atmosphere.
Before we embark on this statistical journey, let's pause for a moment to appreciate the beauty of correlation – the statistical dance of variables, seemingly intertwined in a complex waltz of numerical harmony. Much like a carefully choreographed ballet, we aim to unravel the intricate steps between kerosene usage and air pollution in Dallas, bringing these partners in crime to the center stage.
Now, you might wonder, what do you get when you cross a statistical analysis with a kerosene lamp? A truly enlightening experience! Our research, supported by data from the Environmental Protection Agency and the Energy Information Administration, lit up the path to a correlation coefficient of 0.8896280, with a p-value less than 0.01, for the time period spanning from 1980 to 2021. This illuminating statistical finding hinted at a significant relationship between kerosene usage and the air quality concerns that Dallas residents have been breathing in.
Why was the statistician hired as a travel guide? Because she excelled at making sense of scatter plots! As we examine the potential impact of kerosene usage on air pollution, we aim to navigate through the scattered data points, seeking patterns and relationships, much like a daring explorer in a statistical jungle.
In the realm of scientific exploration, it is crucial to remember that a good statistical result should be like a skirt – long enough to cover the essentials, but short enough to keep it interesting. With this in mind, we embarked on our analysis, aiming to provide a concise yet comprehensive understanding of the potential kerosene connection to air pollution in Dallas.
So, fasten your seatbelts and keep a nose for statistical significance as we embark on this research journey. The correlation may be clear as the Texas sky, but the journey promises intriguing twists and turns, much like a statistical rollercoaster. Let's hold on tight and embrace the statistical adventure ahead!
[[RESULTS]]
Our analysis revealed a strong correlation between air pollution in Dallas and kerosene usage on a global scale, with a correlation coefficient of 0.8896280 and an r-squared value of 0.7914379 over the time period of 1980 to 2021. This relationship proved to be no mere flicker, but rather a burning connection that captivated our statistical senses. It's clear that when it comes to air quality, the kerosene industry may indeed have a significant impact - talk about a "fiery" relationship!
The scatterplot (Fig. 1) visually illustrates the tight bond between air pollution in Dallas and global kerosene use. It's as if the data points were saying, "You can't contain our association - it's air pollution for sure!"
Our findings suggest that the kerosene factor may be adding fuel to the fire of air pollution in Dallas. If only we had known sooner, we could have warned Dallas residents to "kerosene" good-bye to those polluted skies!
-------
Your response should start like this:
[[CONCLUSION]]
ChatGPT:
[[CONCLUSION]]
In conclusion, our study has illuminated a strong and significant correlation between air pollution in Dallas and the use of kerosene on a global scale. This finding underscores the pressing need to address the impact of kerosene usage on urban air quality, particularly in vibrant cities such as Dallas. It seems that when it comes to air pollution, the kerosene industry may indeed have a "burning" impact – much like that one time I forgot to blow out a Bunsen burner in the lab! If only statistical significance had a “kerosene” switch to turn down the heat, but alas, this relationship is here to stay.
The statistical evidence presented in this study brings to mind the classic dad joke – why did the scientist install a knocker on the laboratory door? She wanted to win the No-bell prize! But in all seriousness, the strong correlation coefficient of 0.8896280 and an r-squared value of 0.7914379 paint a clear picture of the intertwined relationship between air pollution in Dallas and global kerosene use. It's as unmistakable as spotting a pink elephant in a scatterplot of gray mice!
So, what does this mean for future research and policy implications? Well, it's time to extinguish the notion that the kerosene factor is just blowing hot air! Our findings emphasize the need for further investigation into the specific sources and mechanisms through which kerosene usage influences air quality, paving the way for targeted interventions and regulatory measures. As for policy recommendations, perhaps it’s time for a “bright” idea to phase out kerosene in favor of cleaner energy alternatives. After all, we wouldn't want to keep fueling the fire of air pollution, now would we?
In the end, it's clear that no more research is needed in this area. The data has spoken, and it's high time to take action. Let's shine a light on this relationship and work towards a brighter, cleaner future for Dallas and beyond. And remember, when it comes to statistical research – keep calm and stay "p-value"!
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of academic journals. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding research, scientific, or academic journal that would publish a paper entited Feeling the Burn: The Kerosene Connection to Air Pollution in Dallas. Respond only with the name of a fictional academic journal.
ChatGPT:
The Journal of Ecological Quirks
Model: gpt-3.5-turbo-1106
System prompt: You provide fictional names of nonprofit research organizations and associations. You say nothing else, and you do not chat with the user.
User prompt: Please provide the name of a funny but plausible sounding nonprofit, academic, or scientific association or organization that would sponsor research that resulted in a paper entited Feeling the Burn: The Kerosene Connection to Air Pollution in Dallas. Respond only with the name of a fictional organization.
ChatGPT:
The Institute for Sustainable Energy Solutions
Model: gpt-3.5-turbo-1106
System prompt: You provide potential search keywords separated by commas. You say nothing else, and you do not chat with the user.
User prompt: Please provide potential search keywords for a paper titled Feeling the Burn: The Kerosene Connection to Air Pollution in Dallas with an abstract of In this study, we examine the relationship between air pollution in Dallas and the use of kerosene on a global scale. We took a deep dive into the data from the Environmental Protection Agency and the Energy Information Administration, and boy, did we get our hands dirty! We found a rather illuminating correlation coefficient of 0.8896280 and p < 0.01 for the time period spanning 1980 to 2021, shedding light on the potential link between kerosene usage and air quality woes in Dallas.
It seems that when it comes to air pollution, the kerosene industry may indeed have a burning impact! And remember, folks, when dealing with kerosene, always keep a burner phone handy – just in case of an emergency.
ChatGPT:
kerosene usage, air pollution, Dallas, Environmental Protection Agency data, Energy Information Administration data, correlation coefficient, air quality, kerosene industry, global scale, burner phone, emergency use
*There is a bunch of Python happening behind the scenes to turn this prompt sequence into a PDF.
Discover a new correlation
View all correlations
View all research papers
Report an error
Data details
Air pollution in DallasDetailed data title: Percentage of days 'unhealthy' or worse air quality in Dallas-Fort Worth-Arlington, TX
Source: Environmental Protection Agency
See what else correlates with Air pollution in Dallas
Kerosene used globally
Detailed data title: Kerosene used globally in millions of barrels per day
Source: Energy Information Administration
See what else correlates with Kerosene used globally
Correlation is a measure of how much the variables move together. If it is 0.99, when one goes up the other goes up. If it is 0.02, the connection is very weak or non-existent. If it is -0.99, then when one goes up the other goes down. If it is 1.00, you probably messed up your correlation function.
r2 = 0.7914379 (Coefficient of determination)
This means 79.1% of the change in the one variable (i.e., Kerosene used globally) is predictable based on the change in the other (i.e., Air pollution in Dallas) over the 42 years from 1980 through 2021.
p < 0.01, which is statistically significant(Null hypothesis significance test)
The p-value is 3.4E-15. 0.0000000000000033963144899864
The p-value is a measure of how probable it is that we would randomly find a result this extreme. More specifically the p-value is a measure of how probable it is that we would randomly find a result this extreme if we had only tested one pair of variables one time.
But I am a p-villain. I absolutely did not test only one pair of variables one time. I correlated hundreds of millions of pairs of variables. I threw boatloads of data into an industrial-sized blender to find this correlation.
Who is going to stop me? p-value reporting doesn't require me to report how many calculations I had to go through in order to find a low p-value!
On average, you will find a correaltion as strong as 0.89 in 3.4E-13% of random cases. Said differently, if you correlated 294,436,808,766,789 random variables You don't actually need 294 trillion variables to find a correlation like this one. I don't have that many variables in my database. You can also correlate variables that are not independent. I do this a lot.
p-value calculations are useful for understanding the probability of a result happening by chance. They are most useful when used to highlight the risk of a fluke outcome. For example, if you calculate a p-value of 0.30, the risk that the result is a fluke is high. It is good to know that! But there are lots of ways to get a p-value of less than 0.01, as evidenced by this project.
In this particular case, the values are so extreme as to be meaningless. That's why no one reports p-values with specificity after they drop below 0.01.
Just to be clear: I'm being completely transparent about the calculations. There is no math trickery. This is just how statistics shakes out when you calculate hundreds of millions of random correlations.
with the same 41 degrees of freedom, Degrees of freedom is a measure of how many free components we are testing. In this case it is 41 because we have two variables measured over a period of 42 years. It's just the number of years minus ( the number of variables minus one ), which in this case simplifies to the number of years minus one.
you would randomly expect to find a correlation as strong as this one.
[ 0.8, 0.94 ] 95% correlation confidence interval (using the Fisher z-transformation)
The confidence interval is an estimate the range of the value of the correlation coefficient, using the correlation itself as an input. The values are meant to be the low and high end of the correlation coefficient with 95% confidence.
This one is a bit more complciated than the other calculations, but I include it because many people have been pushing for confidence intervals instead of p-value calculations (for example: NEJM. However, if you are dredging data, you can reliably find yourself in the 5%. That's my goal!
All values for the years included above: If I were being very sneaky, I could trim years from the beginning or end of the datasets to increase the correlation on some pairs of variables. I don't do that because there are already plenty of correlations in my database without monkeying with the years.
Still, sometimes one of the variables has more years of data available than the other. This page only shows the overlapping years. To see all the years, click on "See what else correlates with..." link above.
| 1980 | 1981 | 1982 | 1983 | 1984 | 1985 | 1986 | 1987 | 1988 | 1989 | 1990 | 1991 | 1992 | 1993 | 1994 | 1995 | 1996 | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | |
| Air pollution in Dallas (Bad air quality days) | 11.7486 | 11.5068 | 10.411 | 15.6164 | 12.5683 | 15.8904 | 11.5068 | 10.411 | 13.6612 | 7.12329 | 7.12329 | 6.30137 | 4.91803 | 4.93151 | 12.0548 | 13.1507 | 7.10383 | 9.0411 | 10.9589 | 10.137 | 9.56284 | 6.57534 | 9.58904 | 8.21918 | 6.28415 | 10.9589 | 7.67123 | 3.0137 | 2.18579 | 3.0137 | 1.36986 | 5.47945 | 3.55191 | 1.36986 | 0.821918 | 1.36986 | 0.273224 | 0 | 2.46575 | 0.273973 | 0.819672 | 1.09589 |
| Kerosene used globally (Million Barrels/Day) | 2201.35 | 2210.5 | 2175.22 | 2170.58 | 2176.54 | 2180.11 | 2208.05 | 1809.3 | 1761.92 | 1642.33 | 1616.4 | 1582.82 | 1709.78 | 1721.72 | 1747.12 | 1798.06 | 1854.83 | 1814.36 | 1767.51 | 1754.29 | 1866.94 | 1859.14 | 1729.5 | 1707.08 | 1615.87 | 1617.94 | 1483.9 | 1366.11 | 1282.98 | 1192.33 | 1178.34 | 1087.09 | 1052.17 | 989.492 | 928.981 | 869.07 | 836.509 | 806.53 | 762.194 | 725.943 | 658.02 | 632.512 |
Why this works
- Data dredging: I have 25,153 variables in my database. I compare all these variables against each other to find ones that randomly match up. That's 632,673,409 correlation calculations! This is called “data dredging.” Instead of starting with a hypothesis and testing it, I instead abused the data to see what correlations shake out. It’s a dangerous way to go about analysis, because any sufficiently large dataset will yield strong correlations completely at random.
- Lack of causal connection: There is probably
Because these pages are automatically generated, it's possible that the two variables you are viewing are in fact causually related. I take steps to prevent the obvious ones from showing on the site (I don't let data about the weather in one city correlate with the weather in a neighboring city, for example), but sometimes they still pop up. If they are related, cool! You found a loophole.
no direct connection between these variables, despite what the AI says above. This is exacerbated by the fact that I used "Years" as the base variable. Lots of things happen in a year that are not related to each other! Most studies would use something like "one person" in stead of "one year" to be the "thing" studied. - Observations not independent: For many variables, sequential years are not independent of each other. If a population of people is continuously doing something every day, there is no reason to think they would suddenly change how they are doing that thing on January 1. A simple
Personally I don't find any p-value calculation to be 'simple,' but you know what I mean.
p-value calculation does not take this into account, so mathematically it appears less probable than it really is.
Try it yourself
You can calculate the values on this page on your own! Try running the Python code to see the calculation results. Step 1: Download and install Python on your computer.Step 2: Open a plaintext editor like Notepad and paste the code below into it.
Step 3: Save the file as "calculate_correlation.py" in a place you will remember, like your desktop. Copy the file location to your clipboard. On Windows, you can right-click the file and click "Properties," and then copy what comes after "Location:" As an example, on my computer the location is "C:\Users\tyler\Desktop"
Step 4: Open a command line window. For example, by pressing start and typing "cmd" and them pressing enter.
Step 5: Install the required modules by typing "pip install numpy", then pressing enter, then typing "pip install scipy", then pressing enter.
Step 6: Navigate to the location where you saved the Python file by using the "cd" command. For example, I would type "cd C:\Users\tyler\Desktop" and push enter.
Step 7: Run the Python script by typing "python calculate_correlation.py"
If you run into any issues, I suggest asking ChatGPT to walk you through installing Python and running the code below on your system. Try this question:
"Walk me through installing Python on my computer to run a script that uses scipy and numpy. Go step-by-step and ask me to confirm before moving on. Start by asking me questions about my operating system so that you know how to proceed. Assume I want the simplest installation with the latest version of Python and that I do not currently have any of the necessary elements installed. Remember to only give me one step per response and confirm I have done it before proceeding."
# These modules make it easier to perform the calculation
import numpy as np
from scipy import stats
# We'll define a function that we can call to return the correlation calculations
def calculate_correlation(array1, array2):
# Calculate Pearson correlation coefficient and p-value
correlation, p_value = stats.pearsonr(array1, array2)
# Calculate R-squared as the square of the correlation coefficient
r_squared = correlation**2
return correlation, r_squared, p_value
# These are the arrays for the variables shown on this page, but you can modify them to be any two sets of numbers
array_1 = np.array([11.7486,11.5068,10.411,15.6164,12.5683,15.8904,11.5068,10.411,13.6612,7.12329,7.12329,6.30137,4.91803,4.93151,12.0548,13.1507,7.10383,9.0411,10.9589,10.137,9.56284,6.57534,9.58904,8.21918,6.28415,10.9589,7.67123,3.0137,2.18579,3.0137,1.36986,5.47945,3.55191,1.36986,0.821918,1.36986,0.273224,0,2.46575,0.273973,0.819672,1.09589,])
array_2 = np.array([2201.35,2210.5,2175.22,2170.58,2176.54,2180.11,2208.05,1809.3,1761.92,1642.33,1616.4,1582.82,1709.78,1721.72,1747.12,1798.06,1854.83,1814.36,1767.51,1754.29,1866.94,1859.14,1729.5,1707.08,1615.87,1617.94,1483.9,1366.11,1282.98,1192.33,1178.34,1087.09,1052.17,989.492,928.981,869.07,836.509,806.53,762.194,725.943,658.02,632.512,])
array_1_name = "Air pollution in Dallas"
array_2_name = "Kerosene used globally"
# Perform the calculation
print(f"Calculating the correlation between {array_1_name} and {array_2_name}...")
correlation, r_squared, p_value = calculate_correlation(array_1, array_2)
# Print the results
print("Correlation Coefficient:", correlation)
print("R-squared:", r_squared)
print("P-value:", p_value)Reuseable content
You may re-use the images on this page for any purpose, even commercial purposes, without asking for permission. The only requirement is that you attribute Tyler Vigen. Attribution can take many different forms. If you leave the "tylervigen.com" link in the image, that satisfies it just fine. If you remove it and move it to a footnote, that's fine too. You can also just write "Charts courtesy of Tyler Vigen" at the bottom of an article.You do not need to attribute "the spurious correlations website," and you don't even need to link here if you don't want to. I don't gain anything from pageviews. There are no ads on this site, there is nothing for sale, and I am not for hire.
For the record, I am just one person. Tyler Vigen, he/him/his. I do have degrees, but they should not go after my name unless you want to annoy my wife. If that is your goal, then go ahead and cite me as "Tyler Vigen, A.A. A.A.S. B.A. J.D." Otherwise it is just "Tyler Vigen."
When spoken, my last name is pronounced "vegan," like I don't eat meat.
Full license details.
For more on re-use permissions, or to get a signed release form, see tylervigen.com/permission.
Download images for these variables:
- High resolution line chart
The image linked here is a Scalable Vector Graphic (SVG). It is the highest resolution that is possible to achieve. It scales up beyond the size of the observable universe without pixelating. You do not need to email me asking if I have a higher resolution image. I do not. The physical limitations of our universe prevent me from providing you with an image that is any higher resolution than this one.
If you insert it into a PowerPoint presentation (a tool well-known for managing things that are the scale of the universe), you can right-click > "Ungroup" or "Create Shape" and then edit the lines and text directly. You can also change the colors this way.
Alternatively you can use a tool like Inkscape. - High resolution line chart, optimized for mobile
- Alternative high resolution line chart
- Scatterplot
- Portable line chart (png)
- Portable line chart (png), optimized for mobile
- Line chart for only Air pollution in Dallas
- Line chart for only Kerosene used globally
- AI-generated correlation image
- The spurious research paper: Feeling the Burn: The Kerosene Connection to Air Pollution in Dallas
You're the correlation whisperer we needed!
Correlation ID: 1613 · Black Variable ID: 20509 · Red Variable ID: 24117


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}